💭⭐ WebRISE: Requirement-Induced State Evaluation for MLLM-Generated Web Artifacts
Published in Arxiv, 2026
Arxiv地址:https://arxiv.org/abs/2606.03220
Project Page: https://iigroup.github.io/WebRISE
1. 关键词 (Keywords)
- Web Artifact Generation / 网页产物生成
- Requirement-Induced State Evaluation / 需求诱导状态评测
- Interaction Contract Graph (ICG) / 交互契约图
- Requirement Coverage / 需求覆盖率
- Transition Validity / 状态转移有效性
- DOM/Visual Dual Oracle / DOM-视觉双通道判定
- Explicit vs. Implicit Requirements / 显式与隐式需求
- Contract-Guided Agent Execution / 契约引导的浏览器执行
2. 背景与动机 (Background & Motivation)
问题定义
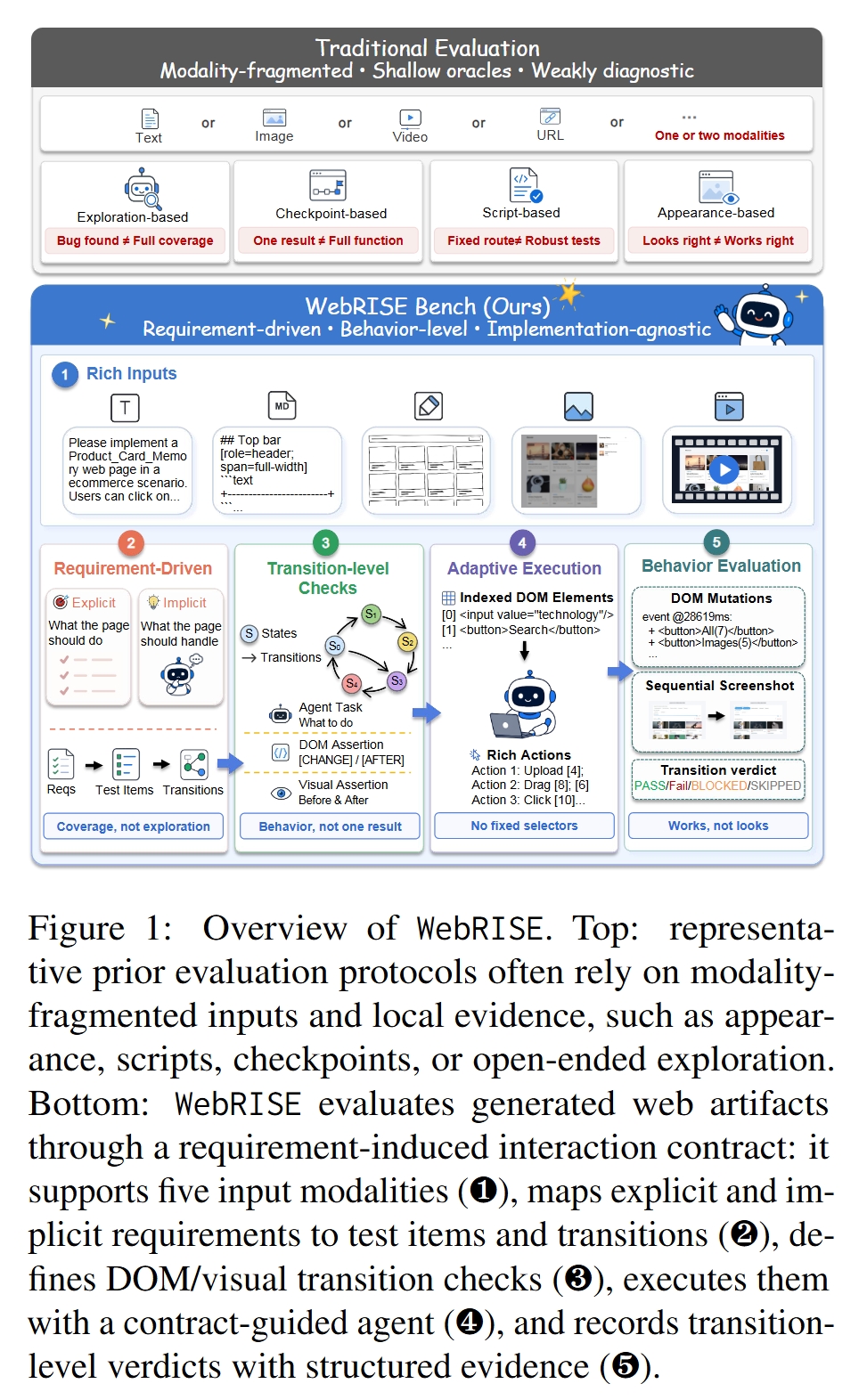
论文关注 MLLM 生成网页产物时的一个核心评测问题:一个网页看起来像,不代表它真的能用。现实中的网页交互不是单个按钮是否存在,也不是某张截图是否美观,而是用户执行一系列操作后,页面状态是否按需求正确更新。
例如:
- 筛选器点击后,列表是否真的被过滤?
- 删除购物车商品后,总价、数量、结算按钮是否同步变化?
- 搜索为空时,页面是否给出正确空状态反馈?
- 翻页、排序、过滤组合后,状态是否保持一致?
已有 web/UI 生成评测通常依赖静态视觉相似度、固定脚本、局部 checkpoint、探索式 agent 或单次动作结果。这些协议能让“交互”变得可观察,但难以完整枚举和归因需求诱导的状态空间。
研究动机
论文提出:交互式网页评测应该从“局部证据”升级为“需求契约一致性”。也就是说,评测对象不应只是某次点击是否有响应,而应是:
- 需求应该诱导哪些稳定 UI 状态?
- 用户意图应该触发哪些状态转移?
- 每个转移后的 DOM、视觉结果和跨组件状态是否满足要求?
- 每个失败能否回溯到显式功能需求或隐式产品约束?
因此,WebRISE 把 MLLM 生成网页的评测形式化为:requirement-induced observable state-transition conformance。
3. 核心方法 (Core Methodology)
整体架构:Requirement → ICG → Browser Execution → Diagnostics
WebRISE 将任务需求编译成可执行交互契约,并在浏览器中验证生成网页是否满足该契约。整体流程包括:
- 输入多模态任务说明;
- 抽取显式需求与隐式需求;
- 构建 Interaction Contract Graph (ICG);
- 用契约引导 agent 执行状态转移;
- 通过 DOM/visual oracle 验证转移;
- 聚合为状态、转移、需求和视觉层面的诊断指标。
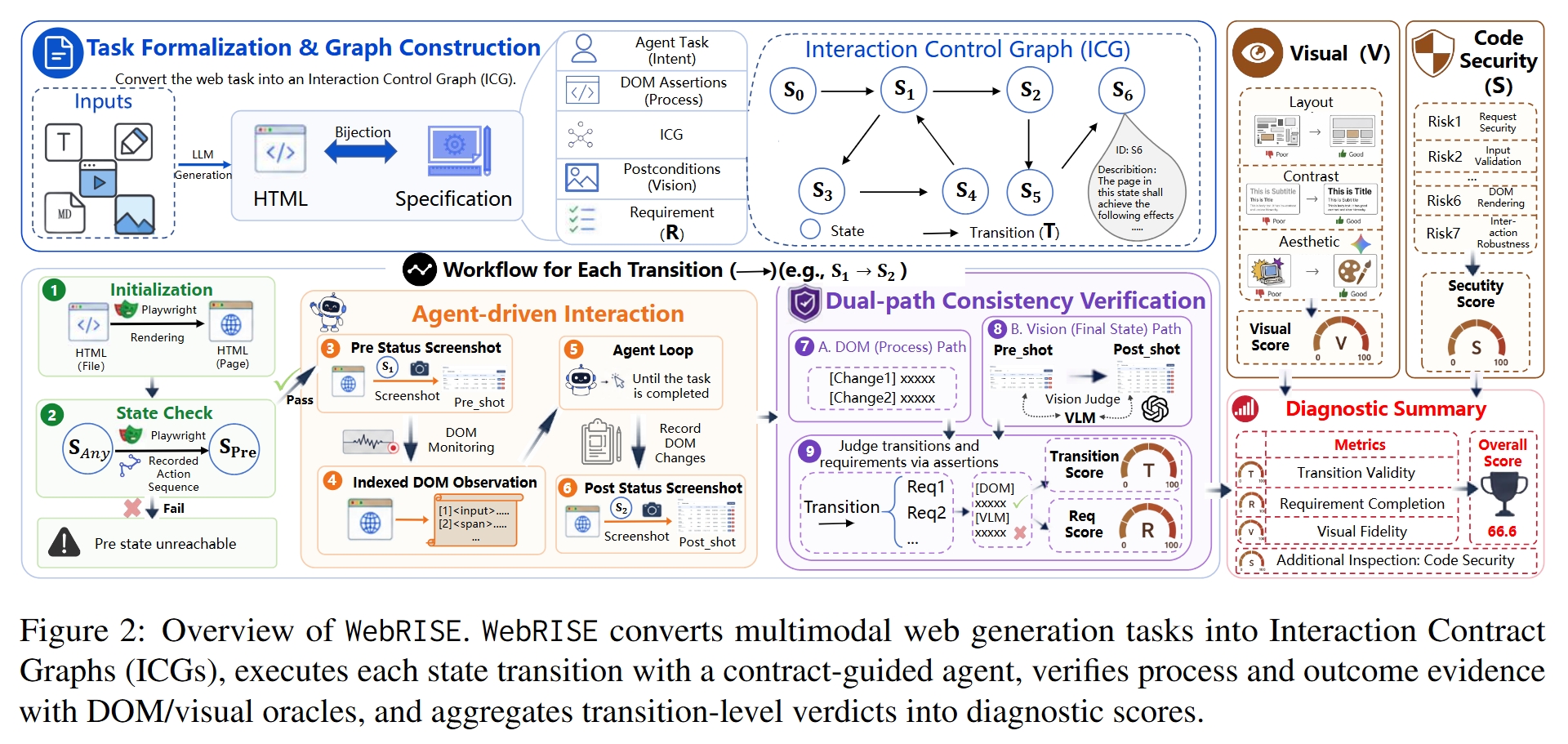
Interaction Contract Graph (ICG)
对每个任务 τ,WebRISE 构建一个交互契约图:
[ G_\tau = (S_\tau, T_\tau, \Phi_\tau, M_\tau) ]
其中:
- Sτ:稳定且可重放的 UI 状态,而不是完整 DOM 快照;
- Tτ:由用户意图驱动的状态转移;
- Φτ:可观察的 DOM/视觉断言;
- Mτ:需求、测试项、转移和断言之间的映射。
这种设计的关键是:状态不是任意页面快照,而是与需求相关的可观察配置;转移不是固定 selector 脚本,而是用户意图层面的行为;断言同时覆盖过程证据和最终可见结果。
显式需求与隐式需求
WebRISE 特别区分两类需求:
- 显式需求 (Explicit Requirements):用户直接说明的功能,例如搜索、筛选、排序、拖拽、导航。
- 隐式需求 (Implicit Requirements):产品级状态一致性约束,例如分页重置、加载反馈、边界提示、删除后的计数同步、隐藏状态清理。
这一区分很重要,因为很多网页“表面可交互”,但失败在隐式约束上。例如按钮能点、列表也变化,但总数、空状态、结算按钮、分页状态没有同步更新。
契约构建流水线
WebRISE 的任务构建包含四步:
- Expert-informed task collection:由行业实践者提供真实场景、用户需求、交互目标和数据假设。
- Requirement normalization:将原始材料标准化为显式/隐式需求集合。
- Test Data Contract & test items:定义评测所需的最小功能准备条件与语义测试项,不绑定布局、DOM 层级或具体 selector。
- ICG compilation:将稳定状态、用户触发行为、DOM/视觉 postcondition 编译成 ICG,并建立需求覆盖映射。
Contract-Guided Evaluation
评测时,ICG 决定“要验证什么”,而 contract-guided browser agent 决定“如何在当前生成页面上执行”。与固定脚本不同,agent 会读取当前页面的 indexed DOM observation,并根据页面状态动态选择操作。
每个 transition 被表示为:
[ t_j = (s_j^{\mathrm{from}}, s_j^{\mathrm{to}}, g_j, P_j, A_j^{\mathrm{dom}}, A_j^{\mathrm{vis}}) ]
其中 g_j 是自然语言 agent goal,P_j 是前置条件,A_j^{dom} 和 A_j^{vis} 分别是 DOM 与视觉断言。只有当 source state 可达、agent 完成目标、DOM/visual 检查全部通过时,该 transition 才记为 PASS。
DOM/Visual 双通道判定
WebRISE 对每个 transition 记录:
- agent trace;
- DOM event log;
- pre/post screenshot;
- DOM assertion verdict;
- visual postcondition verdict;
- transition outcome。
DOM 断言负责过程级或结构级证据,例如 [CHANGE] 检查执行中的 transient behavior,[AFTER] 检查最终稳定 DOM 状态。视觉断言负责用户可见结果,例如列表更新、排序变化、卡片移动、面板展开、空状态显示等。
4. 数据与实验设计 (Dataset & Experimental Design)
Benchmark 规模
WebRISE 包含:
- 442 个任务;
- 5 种输入模态:Text、Markdown、Sketch、Image、Video;
- 5,271 条需求;
- 5,081 个状态;
- 5,495 个状态转移;
- 12,441 条 DOM/visual 断言。
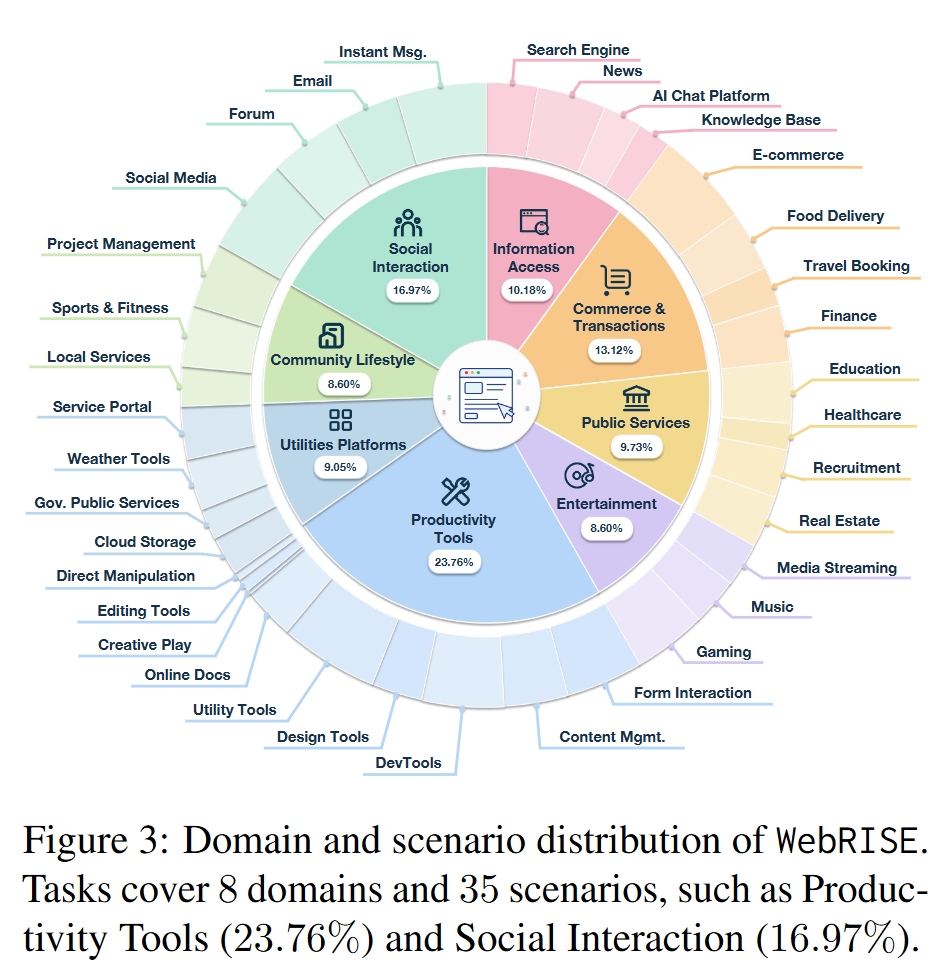
任务覆盖 8 个领域、35 个场景,例如 Productivity Tools、Social Interaction、E-commerce、Food Delivery、AI Chat Platform、Knowledge Base 等。
与已有 benchmark 的区别
相较 WebCoderBench、VibeCodeBench、Interaction2Code、FrontendBench、WebGen-Bench、IWR-Bench 等评测,WebRISE 的核心差异是:
- 同时支持 interaction、vision、safety;
- 同时建模显式需求与隐式需求;
- 支持五种输入模态;
- 判定机制不是静态指标、固定脚本或局部 checkpoint,而是 DOM/VLM assertion 下的需求诱导状态转移一致性。
评测模型
论文评测 14 个代表性模型:
- 开源/开放权重:Qwen3.5-27B、Qwen3.5-122B-A10B、Qwen3.5-397B-A17B、Qwen3.6-27B、Qwen3.6-35B-A3B、Kimi-K2.5、Kimi-K2.6;
- 闭源/专有模型:GPT-5.4、GPT-5.5、Claude Opus 4.6、Claude Opus 4.7、Gemini 3 Flash、Gemini 3.1 Pro、Qwen3.6-Plus。
指标体系
WebRISE 报告一组从同一 ICG 投影出的诊断指标:
- S% (State Reachability):可达状态比例;
- T% (Transition Validity):PASS 的状态转移比例;
- Re% (Explicit Requirement Coverage):显式需求覆盖率;
- Ri% (Implicit Requirement Coverage):隐式需求覆盖率;
- R% (Overall Requirement Coverage):总体需求覆盖率;
- V% (Visual Quality):辅助视觉质量分;
- Overall:跨模态的 T、R、V 紧凑平均。
这些指标的重点不是给一个单一分数,而是把失败定位到状态可达性、转移正确性、显式功能、隐式约束或视觉质量。
5. 实验结果与分析 (Results & Analysis)
主要结果:交互式网页生成远未解决
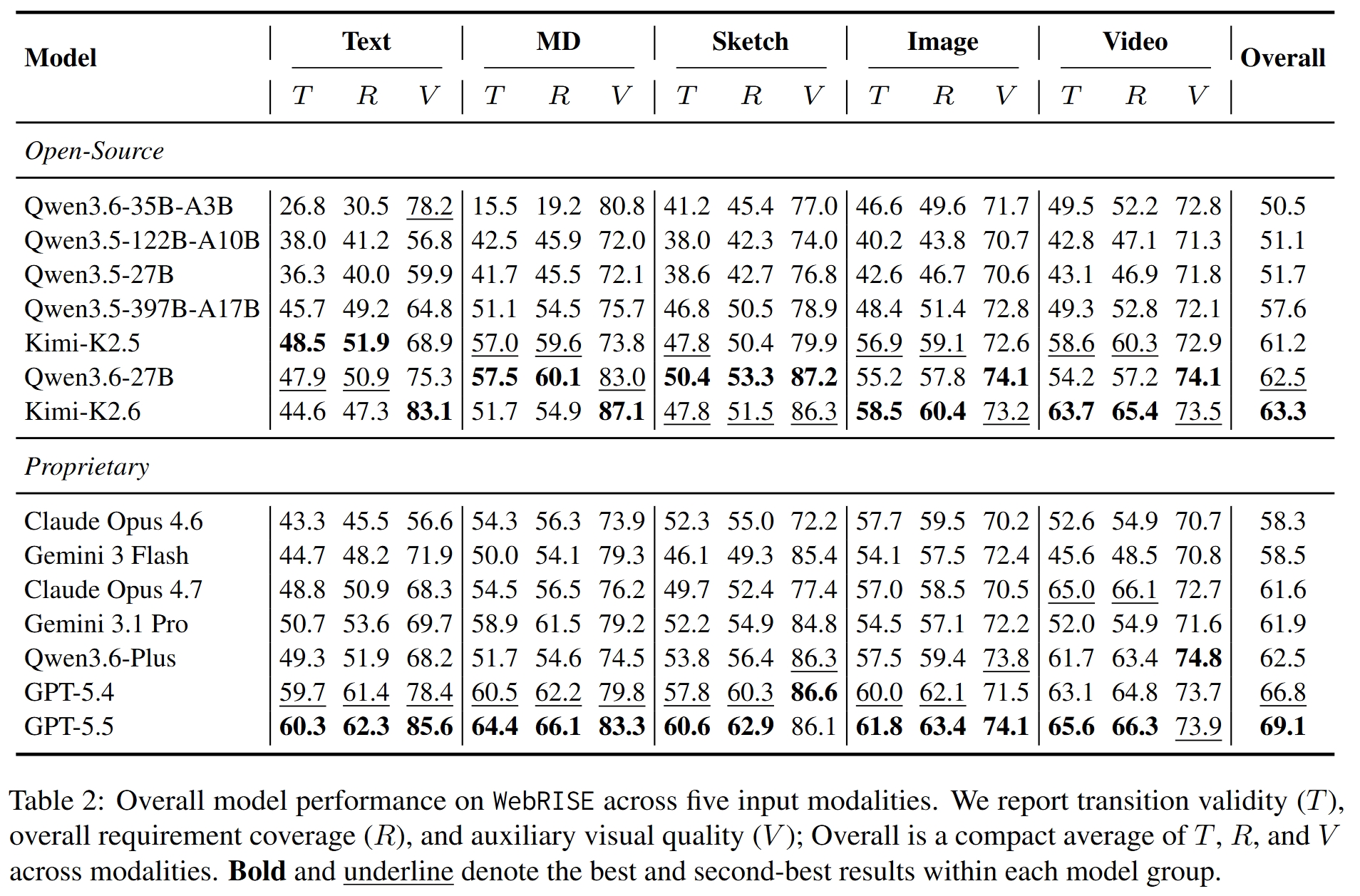
主结果显示,即使最强模型 GPT-5.5 的 best modality 也只达到:
- T = 65.6% transition validity;
- R = 66.3% requirement coverage;
- Overall = 69.1。
这意味着仍有约三分之一的需求转移或需求检查无法满足。
模型层面的 Overall 排名中:
- GPT-5.5:69.1;
- GPT-5.4:66.8;
- Kimi-K2.6:63.3,是开放权重模型中最高;
- Qwen3.6-27B:62.5;
- Qwen3.6-Plus:62.5。
论文的一个重要结论是:闭源模型整体领先,但模型开放性不是唯一决定因素;模态处理能力和状态交互推理同样显著影响排名。
视觉质量不是行为正确性的代理
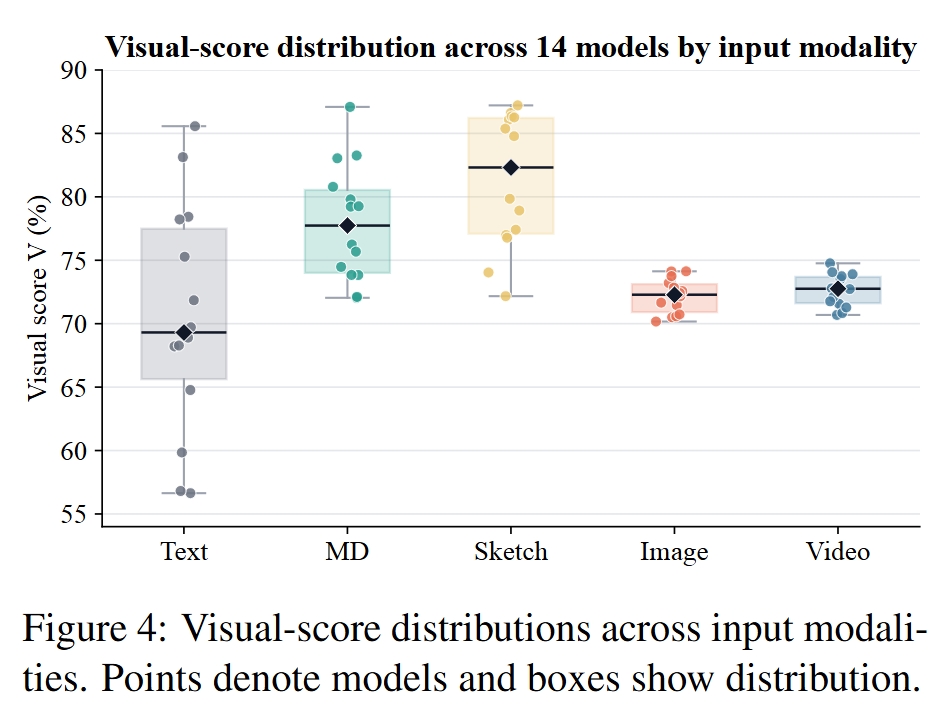
WebRISE 明确展示了视觉分数与交互正确性之间的断裂。例如:
- Qwen3.6-35B-A3B 在 Markdown 输入下视觉质量 V = 80.8;
- 但 transition validity 只有 T = 15.5;
- requirement coverage 只有 R = 19.2。
这说明“页面看起来好”不能说明“页面能正确工作”。因此,Web artifact 评测必须进入状态转移与需求覆盖层面。
输入模态影响:Video 最能帮助交互行为恢复
论文在所有模型和任务上统计模态平均表现:
- Text:T = 46.0,R = 48.9,Ri = 43.0;
- Markdown:T = 50.8,R = 53.7,Ri = 47.6;
- Sketch:T = 48.8,R = 52.0,Ri = 45.4;
- Image:T = 53.6,R = 56.2,Ri = 50.8;
- Video:T = 54.8,R = 57.2,Ri = 53.6。
Video 相比 Text 提升约:
- T:+8.8;
- R:+8.3;
- Ri:+10.6。
这表明动态交互演示尤其有助于恢复状态变化和隐式产品行为。相比之下,Sketch 获得最高视觉质量分,但在交互和需求覆盖上不如 Image/Video,进一步说明静态视觉结构不是行为正确性的充分条件。
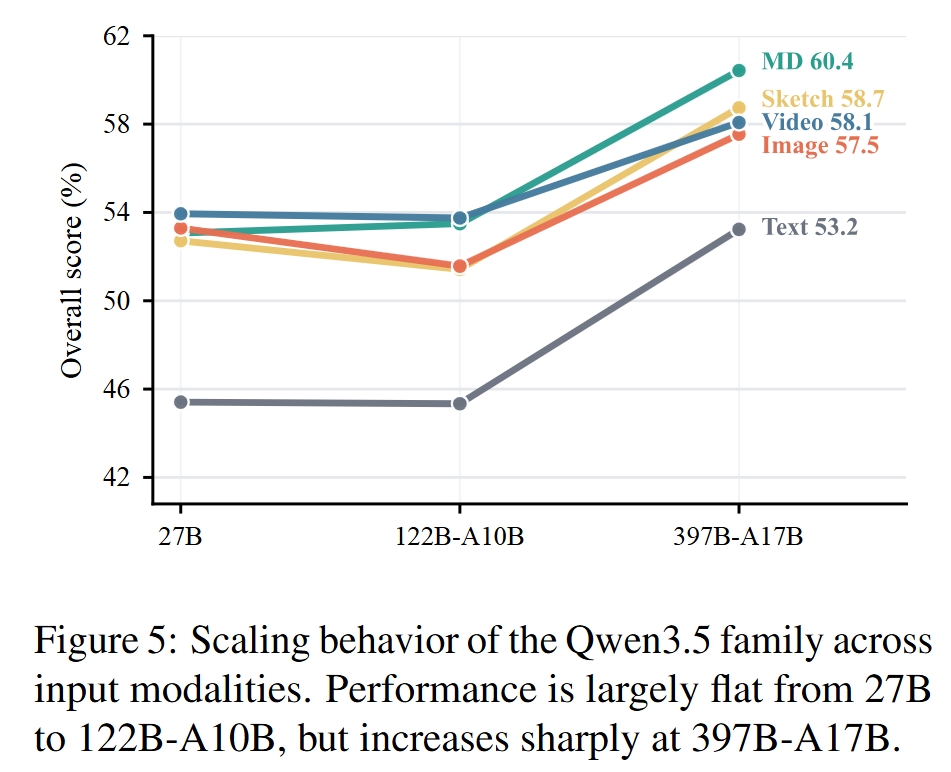
模型 scaling 效应
在 Qwen3.5 家族内,性能从 27B 到 122B-A10B 基本平缓,但到 397B-A17B 出现明显跃升。论文将其解释为 stateful web artifact generation 可能存在一个 scaling knee:模型需要足够容量才能同时处理布局、交互逻辑与状态行为。
缺陷注入:ICG 更敏感
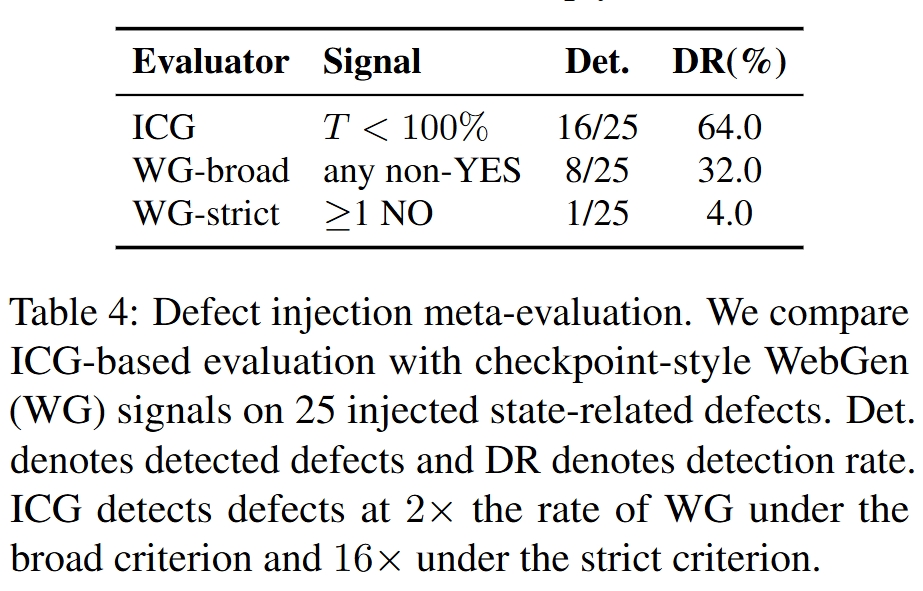
为了验证评测器是否真的能发现状态错误,作者在通过 GT 验证的页面中注入 25 个 state-related defects,并比较 ICG-based evaluation 与 checkpoint-style WebGen signals:
- ICG:检测 16/25,DR = 64.0%;
- WebGen broad:检测 8/25,DR = 32.0%;
- WebGen strict:检测 1/25,DR = 4.0%。
这说明 ICG 对状态一致性错误更敏感,检测率是 broad checkpoint 的 2×,是 strict checkpoint 的 16×。
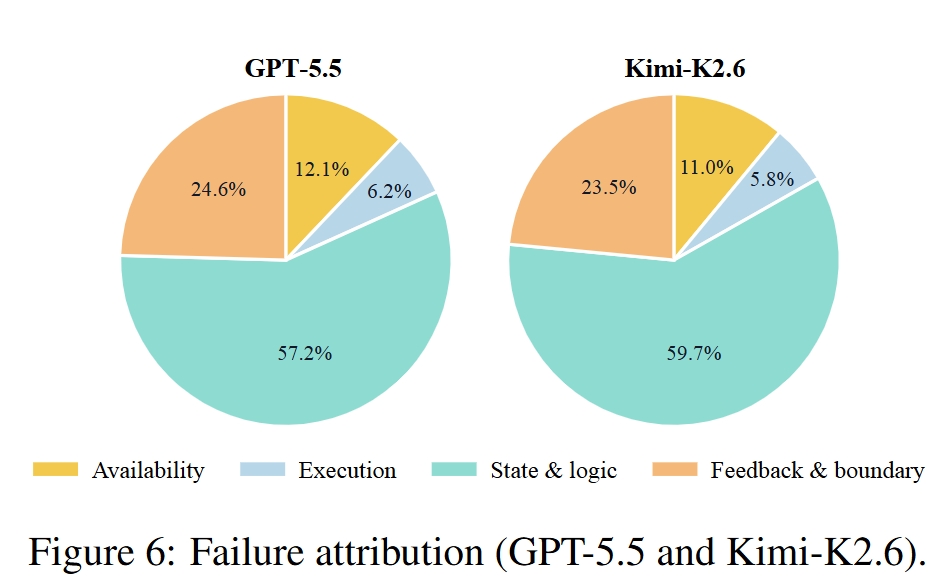
失败归因:State & Logic 是主瓶颈
论文将失败转移分为四类:
- Availability:缺少入口、控件或交互路径;
- Execution:控件存在但动作没有生效;
- State & Logic:动作后状态、数据规则、目标内容、视觉状态或上下文更新错误;
- Feedback & Boundary:验证、禁用状态、加载、错误、确认、空状态等反馈缺失。
GPT-5.5 与 Kimi-K2.6 的失败分布相似,其中 State & Logic 占比最高,其次是 Feedback & Boundary。这说明很多失败不是“按钮找不到”或“点不动”,而是交互发生后,页面没有正确维护状态、规则和边界反馈。
案例分析:购物车状态同步错误
论文给出一个购物车交互案例:用户取消选中唯一商品后,正确页面应将总价清零并禁用 checkout;失败页面虽然更新了 checkbox 状态,却没有同步价格明细和结算按钮状态。
WebRISE 能通过 DOM assertion 和 visual assertion 将错误定位为状态一致性失败,而不是简单的点击执行失败。

6. 总结与贡献 (Conclusion & Contribution)
主要结论
WebRISE 证明:MLLM 生成网页的关键评测对象不应只是视觉外观或局部动作结果,而应是需求诱导的状态转移是否成立。当前模型即使视觉质量较高,也经常在状态同步、隐式约束、边界反馈和跨组件逻辑上失败;Video 等动态输入能改善交互恢复,但远未解决隐式状态一致性问题。
核心贡献
- 提出 WebRISE 评测范式:将 MLLM-generated web artifacts 的评测重构为 requirement-induced observable state-transition conformance。
- 构建 Interaction Contract Graph:用状态、转移、DOM/视觉断言和需求映射表达可执行交互契约。
- 设计契约引导评测协议:通过 adaptive browser agent 执行转移,并用 DOM/visual dual oracle 记录可审计证据。
- 发布多模态 benchmark:覆盖 442 个任务、5 种输入模态、5,271 条需求、5,495 个转移和 12,441 条断言。
- 提供诊断性实验发现:揭示最强模型仍约三分之一需求未满足,Video 提供最强交互信号,隐式状态约束和 State & Logic 仍是主要瓶颈。