[ICML 2026] Smaller Models are Natural Explorers for Policy-Level Diversity in GRPO
Published in ICML, 2026
Arxiv地址:https://arxiv.org/abs/2605.30789
Code: https://github.com/qishisuren123/S2L-PO
1. 关键词 (Keywords)
- GRPO / Group Relative Policy Optimization
- RLVR / Reinforcement Learning with Verifiable Rewards
- 策略级多样性 / Policy-Level Diversity
- 小模型探索器 / Smaller Models as Natural Explorers
- Small-to-Large Policy Optimization / S2L-PO
- 混合 rollout 采样 / Mixed Rollout Generation
- 渐进退火 / Progressive Annealing
- 数学推理后训练 / Mathematical Reasoning Post-Training
2. 背景与动机 (Background & Motivation)
问题定义
论文关注 GRPO 在大语言模型推理后训练中的一个核心瓶颈:rollout 多样性不足会削弱组内相对优势估计,导致学习信号变弱甚至停滞。标准 GRPO 通常对同一 prompt 采样多个候选解,再依据可验证奖励计算组内相对 advantage;如果候选解过于相似,奖励差异和梯度信号都会变小。
已有方法多通过提高 temperature、top-p 或 entropy 来增加 token 级随机性,但这种做法容易把噪声注入到每一步解码中。对于数学推理这类长链任务,局部 token 扰动会沿着推理链累积,导致轨迹表面上更“多样”,但整体逻辑更不连贯。
核心观察
作者提出一个重要经验发现:在同一模型家族内部,较小模型虽然 pass@1 往往低于大模型,但随着采样次数 k 增大,小模型的 pass@k 增长更快,甚至可以追平或超过更大模型。这说明小模型并不只是“弱”,它们还天然提供了更多策略级探索路径。
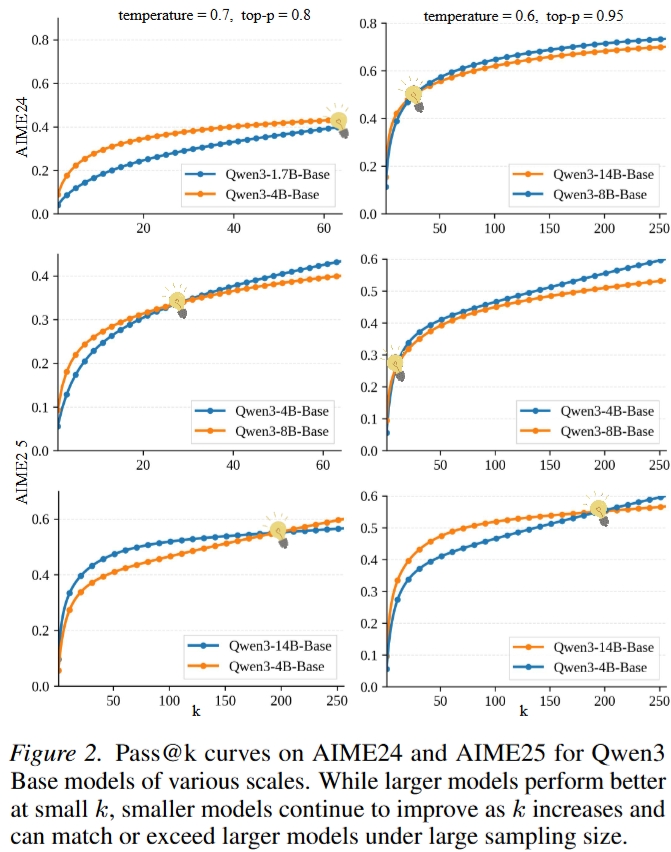
Qwen3 Base 系列在 AIME24/AIME25 上的 pass@k 曲线显示,大模型在小 k 区间更强,但小模型在大采样预算下持续提升,体现出更高的策略多样性。
研究动机
这篇论文的关键视角是区分两类多样性:
- Token-level diversity:通过采样温度等方式扰动每一步 token 选择,容易带来局部噪声与长程不一致。
- Policy-level diversity:通过模型参数、能力边界和归纳偏置差异,让整个解题策略发生一致性偏移,更容易形成连贯的替代推理路径。
因此,作者提出:不要只用大模型自己高温采样探索,而是让同家族的小模型作为“天然探索器”,为大模型提供更便宜、更结构化的 rollout。
3. 核心方法 (Core Methodology)
整体框架:S2L-PO
S2L-PO(Small-to-Large Policy Optimization)的核心思想很直接:冻结小模型,用它在训练早期为大模型生成一部分 rollout;随着训练推进,逐步把 rollout 来源切换回大模型自身,最终恢复标准 on-policy GRPO。
上半部分是标准 GRPO,所有 rollout 都来自当前 policy;下半部分是 S2L-PO,小模型和大模型共同生成候选组,但只更新大模型。
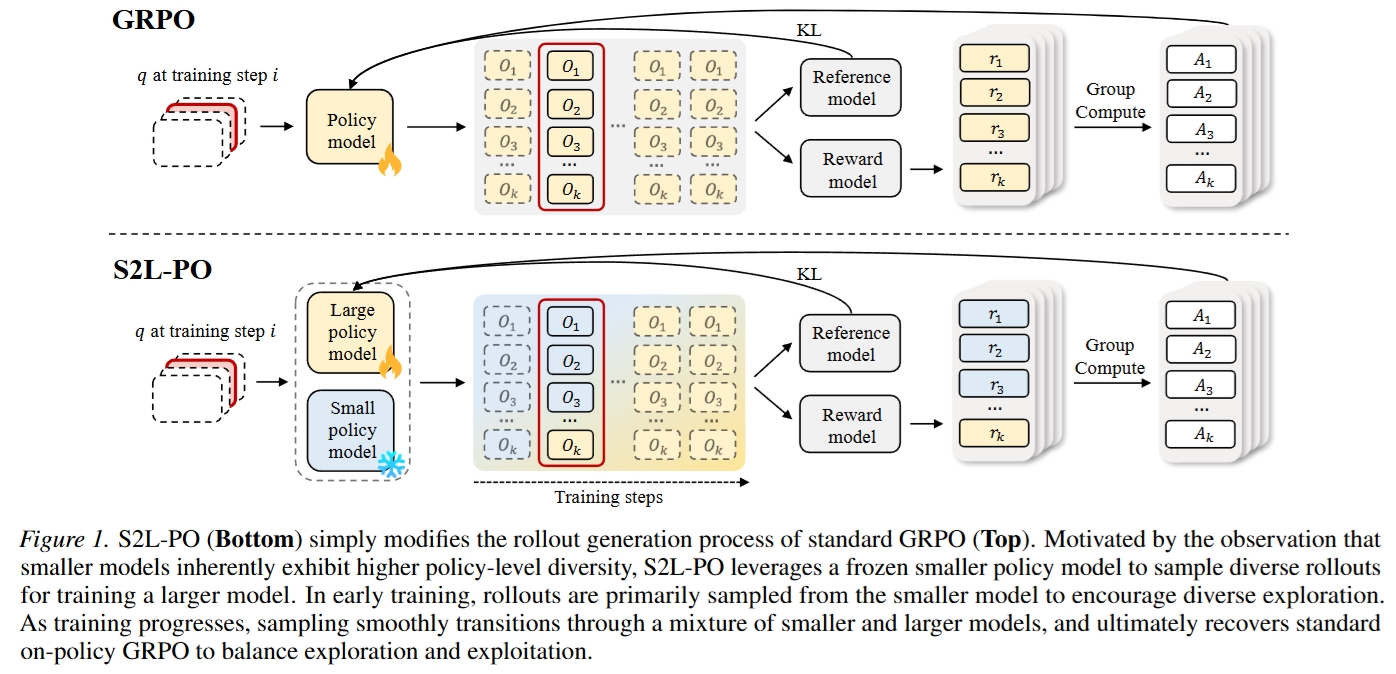
为什么小模型适合作为探索器
作者把小模型视为同一模型家族中的“参数级压缩扰动”。以 Qwen3 系列为例,小模型通常由更大教师模型蒸馏得到,因此它们与大模型保持分布相近,但由于容量受限,会形成不同的决策边界和归纳偏置。
这种差异不是逐 token 的独立噪声,而是作用在整个 policy 上的结构性偏移。因此,小模型生成的轨迹更可能体现完整的替代解法,而不是随机破坏某一步推理。
论文对比了高温采样带来的 token-level perturbation 与参数压缩带来的 policy-level perturbation。前者更容易在长链中累积随机偏差,后者更容易产生时间相关、逻辑一致的探索轨迹。
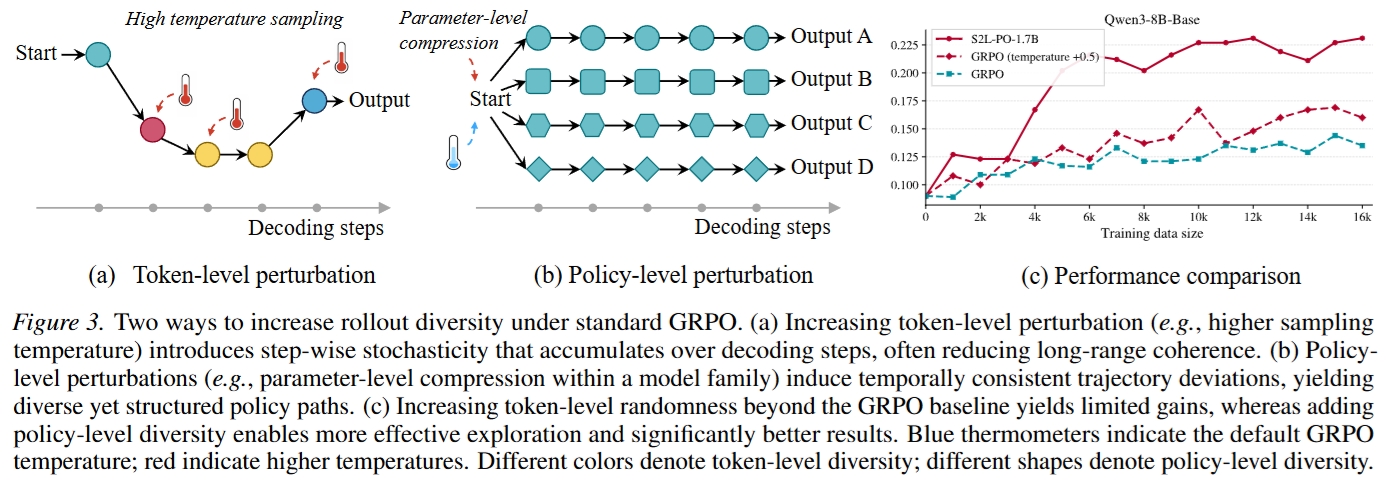
混合 rollout 生成
在每个训练 step 中,给定组大小 G:
- 从冻结的小模型采样 Gw 个候选;
- 从当前大模型采样 Gs 个候选;
- 将两部分候选合并为同一个 group;
- 对整个 group 计算可验证 reward 与组内相对 advantage;
- 只更新大模型参数,小模型始终保持 frozen。
这一点很重要:S2L-PO 不改变 GRPO 的 loss、advantage 计算和优化器,只改变 rollout 的来源。因此它可以较容易接入现有 GRPO 管线。
渐进退火策略
纯小模型 rollout 并不能一直有效,因为小模型能力上限较低,且随着大模型更新,二者的分布差距会扩大。为平衡 exploration 和 exploitation,S2L-PO 使用线性退火:
- 训练早期:主要使用小模型 rollout,提高策略级探索与组内差异;
- 训练中期:小模型 rollout 比例逐步降低,大模型 rollout 比例逐步提高;
- 训练后期:完全回到大模型 on-policy GRPO,避免长期 off-policy 分布错配。
算法给出 S2L-PO 的 progressive smaller-to-larger rollout sampling 过程。

4. 实验设计 (Experimental Design)
训练数据与评估任务
- 训练数据:去重后的 DAPO17k,聚焦可验证多步推理。
- 数学推理评估:AIME 2024、AIME 2025、MATH-500、OlympiadBench。
- 域外泛化评估:CommonsenseQA。
- 评估方式:遵循 Qwen3 技术报告中的 nothink 模式;每题采样 16 个 rollout,并统计 Pass@1。
模型家族
论文在两个模型家族上验证:
- Qwen3-Base:1.7B / 4B 作为小模型探索器,8B / 14B 作为大模型学习器。
- InternLM2.5-Base:1.8B 作为探索器,7B 作为学习器。
所有主要实验使用 8 张 NVIDIA L20 GPU,并基于 verl 的默认 GRPO 配置完成。
对比设置
主要对比包括:
- 标准 GRPO:rollout 完全来自当前大模型;
- 高温采样 GRPO:通过更强 token-level randomness 提升表面多样性;
- S2L-PO:使用小模型提供 policy-level diversity,并逐步退火回 on-policy;
- 小模型全程 rollout:只依赖小模型生成候选,不做渐进切换;
- abrupt switching:从小模型 rollout 突然切换到大模型 rollout;
- diversity-filtered S2L-PO:人为过滤小模型多样 rollout,用来验证收益是否真的来自多样性。
5. 实验结果与分析 (Results & Analysis)
主要结果
S2L-PO 在 Qwen3 和 InternLM2.5 两个模型家族、四个数学推理基准上均优于标准 GRPO。
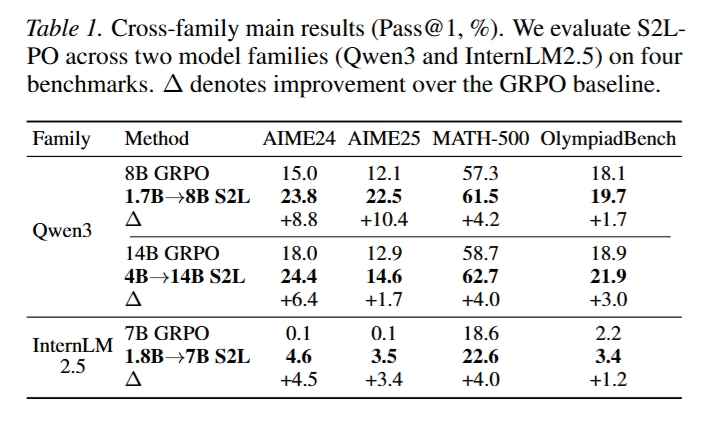
关键结果包括:
- Qwen3 1.7B → 8B:
- AIME24:15.0 → 23.8(+8.8)
- AIME25:12.1 → 22.5(+10.4)
- MATH-500:57.3 → 61.5(+4.2)
- OlympiadBench:18.1 → 19.7(+1.7)
- Qwen3 4B → 14B:
- AIME24:18.0 → 24.4(+6.4)
- AIME25:12.9 → 14.6(+1.7)
- MATH-500:58.7 → 62.7(+4.0)
- OlympiadBench:18.9 → 21.9(+3.0)
- InternLM2.5 1.8B → 7B:
- AIME24:0.1 → 4.6(+4.5)
- AIME25:0.1 → 3.5(+3.4)
- MATH-500:18.6 → 22.6(+4.0)
- OlympiadBench:2.2 → 3.4(+1.2)
S2L-PO 不仅最终性能更高,训练收敛也更快。相比标准 GRPO,小模型早期提供的策略级探索使大模型更快进入高质量策略区域。
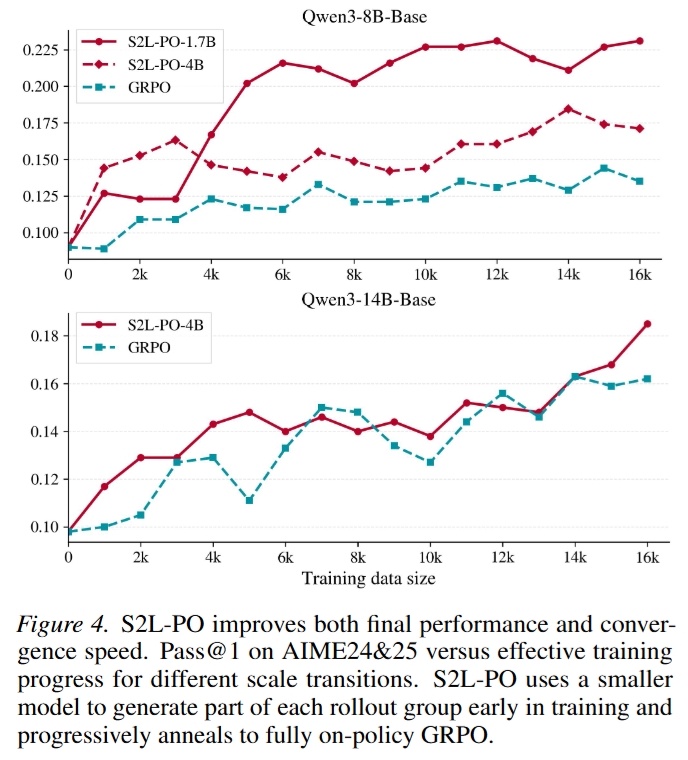
域外泛化
在只用数学数据训练后,模型在 CommonsenseQA 上也没有退化,反而略有提升。
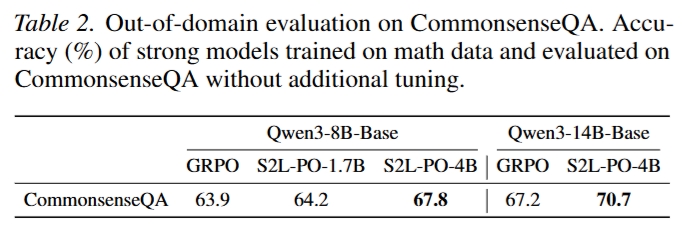
- Qwen3-8B-Base:
- GRPO:63.9
- S2L-PO-1.7B:64.2
- S2L-PO-4B:67.8
- Qwen3-14B-Base:
- GRPO:67.2
- S2L-PO-4B:70.7
这说明 S2L-PO 的收益不只是对数学 benchmark 的局部过拟合,也可能改善一般推理鲁棒性。
多样性分析
作者用 Self-BLEU、Edit Diversity 和 Unique Answer Ratio 度量 AIME24 上不同模型规模的 rollout 多样性。结果随模型变小呈现单调趋势:
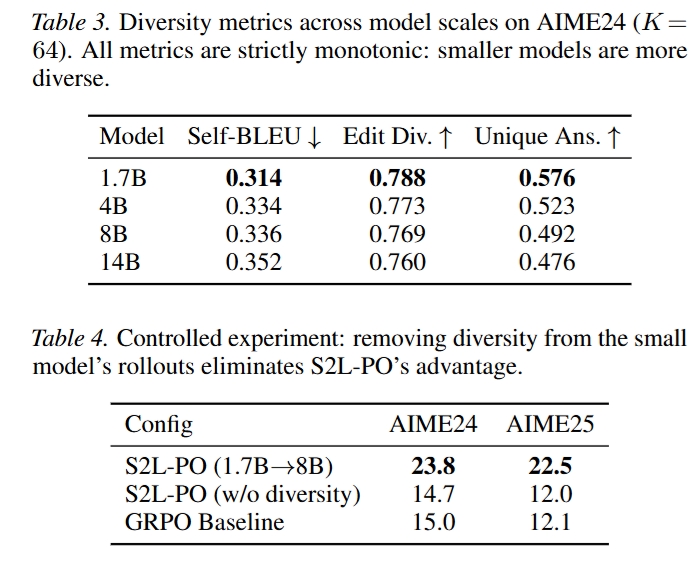
- 1.7B 的 Self-BLEU 最低,Edit Diversity 和 Unique Answer Ratio 最高;
- 14B 的 Self-BLEU 最高,Unique Answer Ratio 最低;
- 1.7B 的 Unique Answer Ratio 为 0.576,而 14B 为 0.476。
这支持论文的核心假设:小模型天然提供更高的策略级多样性。
控制实验
见 Table 4,当作者过滤掉小模型中多样性较高的 rollout,使其多样性接近大模型时,S2L-PO 的优势基本消失。
- S2L-PO (1.7B→8B):AIME24 = 23.8,AIME25 = 22.5
- S2L-PO without diversity:AIME24 = 14.7,AIME25 = 12.0
- GRPO baseline:AIME24 = 15.0,AIME25 = 12.1
这说明提升并非来自简单的 off-policy 混合,而是来自小模型 rollout 的策略级多样性。
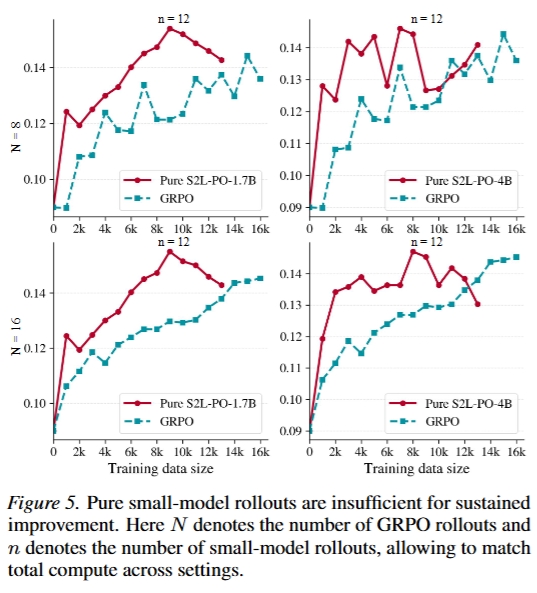
消融研究
- 不能全程依赖小模型 rollout
见原文 Figure 5。纯小模型 rollout 在训练早期提升很快,但随后会 plateau 或回落,原因是静态小模型和不断演化的大模型之间的分布错配越来越大。
- 渐进切换优于突然切换
见原文 Figure 6。abrupt switching 会给训练分布带来突然冲击,导致不稳定;线性退火能让大模型逐步吸收小模型探索到的高质量区域。
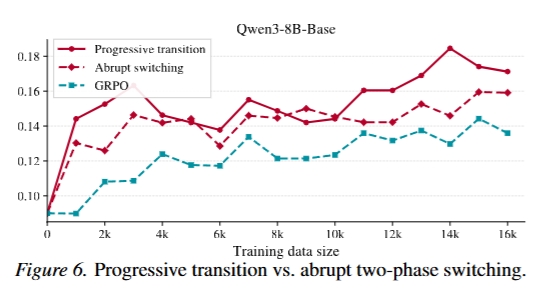
- 退火长度很重要
见原文 Figure 7。过短的退火阶段会降低训练稳定性和最终性能,说明 exploration-to-exploitation 的交接本身是一个关键控制变量。
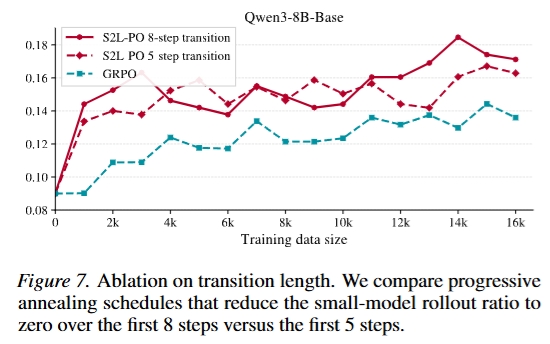
6. 总结与贡献 (Conclusion & Contribution)
论文的核心结论是:在 GRPO/RLVR 场景中,rollout 多样性不应只通过 token-level randomness 获得。小模型由于参数压缩、蒸馏和能力边界带来的 policy-level diversity,可以作为大模型训练中的天然探索器,为组内相对优势估计提供更结构化、更连贯的学习信号。
核心贡献可概括为四点:
- 经验发现:同家族小模型在 pass@k 上展现出更强的策略级探索能力,尤其在大采样预算下可能追平或超过大模型。
- 机制解释:将 token-level perturbation 与 policy-level perturbation 区分开来,指出后者更具时间相关性和轨迹一致性。
- 方法贡献:提出 S2L-PO,通过冻结小模型 + 混合 rollout + 渐进退火,在不改变 GRPO 目标函数的情况下提升训练效率和最终性能。
- 实证验证:在 Qwen3 与 InternLM2.5 两个模型家族、多个数学推理基准和 OOD 常识问答上验证有效性,并用控制实验确认收益来自小模型的 policy-level diversity。