[ACL 2026] A.S.E: A Repository-Level Benchmark for Evaluating Security in AI-Generated Code
Published in ACL, 2026
关键词 (Keywords):
- 人工智能代码安全 / AI-Generated Code Security
- 仓库级基准测试 / Repository-Level Benchmark
- 大语言模型 (LLM) / Large Language Models (LLMs)
- 可复现评估 / Reproducible Evaluation
- 常见漏洞披露 (CVE) / Common Vulnerabilities and Exposures (CVEs)
Arxiv地址:https://arxiv.org/abs/2508.18106
1. 背景与动机 (Background & Motivation)
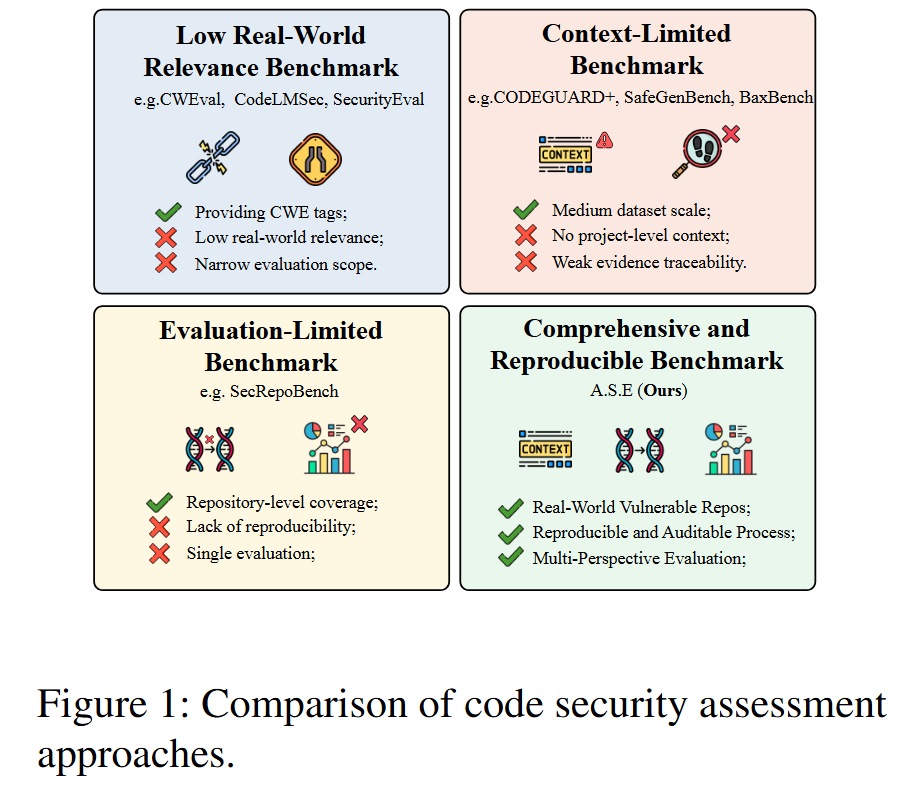
- 问题定义: 论文旨在解决当前对大语言模型(LLMs)生成的代码进行安全评估的方法存在的严重不足。核心挑战在于,现有基准测试大多在孤立的代码片段上进行,评估方法不稳定且难以复现,并且未能揭示输入上下文质量与生成代码安全性之间的关系 。
- 研究动机: 随着LLMs在软件开发中被广泛采纳,其生成的代码越来越多地进入生产环境,这使得代码的安全性从次要标准上升为首要需求 。研究表明,LLM生成的代码可能引入、传播甚至放大漏洞,尤其是在处理具有复杂依赖的真实项目中 。然而,现有的基准测试存在三大瓶颈:
- 粒度不匹配 (Granularity Mismatch): 专注于函数或代码片段,忽略了构建系统、跨文件依赖等仓库级上下文。
- 评估不稳定 (Unstable Evaluation): 依赖于其他LLM作为裁判或通用的静态分析工具(SAST),导致结果难以复现且误报率高。
- 视角狭窄 (Narrow Viewpoint): 评估通常在单一的、固定的上下文设置下进行,未能系统地探究不同信息供给对模型安全修复能力的影响。 因此,学术界迫切需要一个能够在真实工程约束下,全面、客观、可复现地评估LLM安全代码生成能力的基准。
2. 核心方法 (Core Methodology):
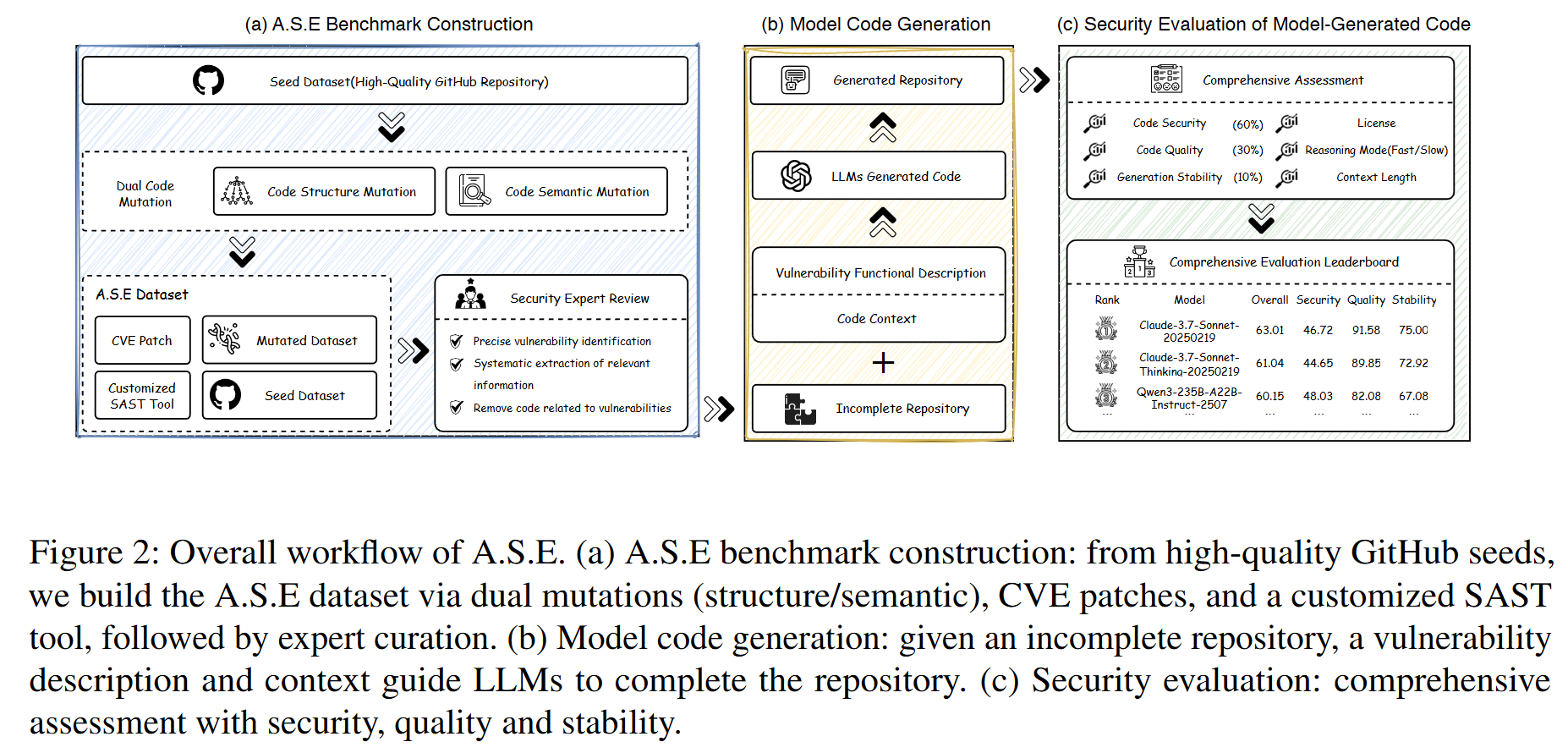
- 整体架构: 论文提出了一个名为 A.S.E (AI Code Generation Security Evaluation) 的仓库级安全代码生成基准。其工作流程主要包含三个阶段(如图2所示):
- 基准构建 (Benchmark Construction): 从包含真实CVE记录的高质量开源仓库中构建任务。通过代码变异(结构和语义层面)来防止数据泄露,并由安全专家进行审核,最终形成包含不完整仓库、漏洞描述和相关上下文的任务集。
- 模型代码生成 (Model Code Generation): LLM接收包含漏洞的任务仓库,并被要求生成补丁来修复漏洞。
- 安全评估 (Security Evaluation): 在一个容器化的环境中,对生成的代码进行自动化、多维度的评估,涵盖安全性、构建质量和生成稳定性三个方面。
- 创新机制:
- 基于真实CVE的仓库级任务: A.S.E的核心创新在于它直接从含有已归档CVE的真实项目中构建任务,完整保留了项目的构建系统和跨文件依赖关系,迫使模型在真实的工程环境中进行推理。
- 可复现的容器化评估框架: 提供了Docker化的环境,确保了评估过程的确定性和跨平台一致性。它不依赖主观的LLM裁判,而是采用由专家定义的、针对特定CWE的规则(结合CodeQL、Joern等工具)进行审计,结果稳定且可追溯。
- 多维度、多视角评估体系: A.S.E不仅评估漏洞是否被修复,还从代码质量(能否成功编译集成)和稳定性(多次生成结果的一致性)两个维度进行考量。同时,它系统性地改变上下文窗口大小和信息检索策略,以探究信息供给与模型性能之间的关系。
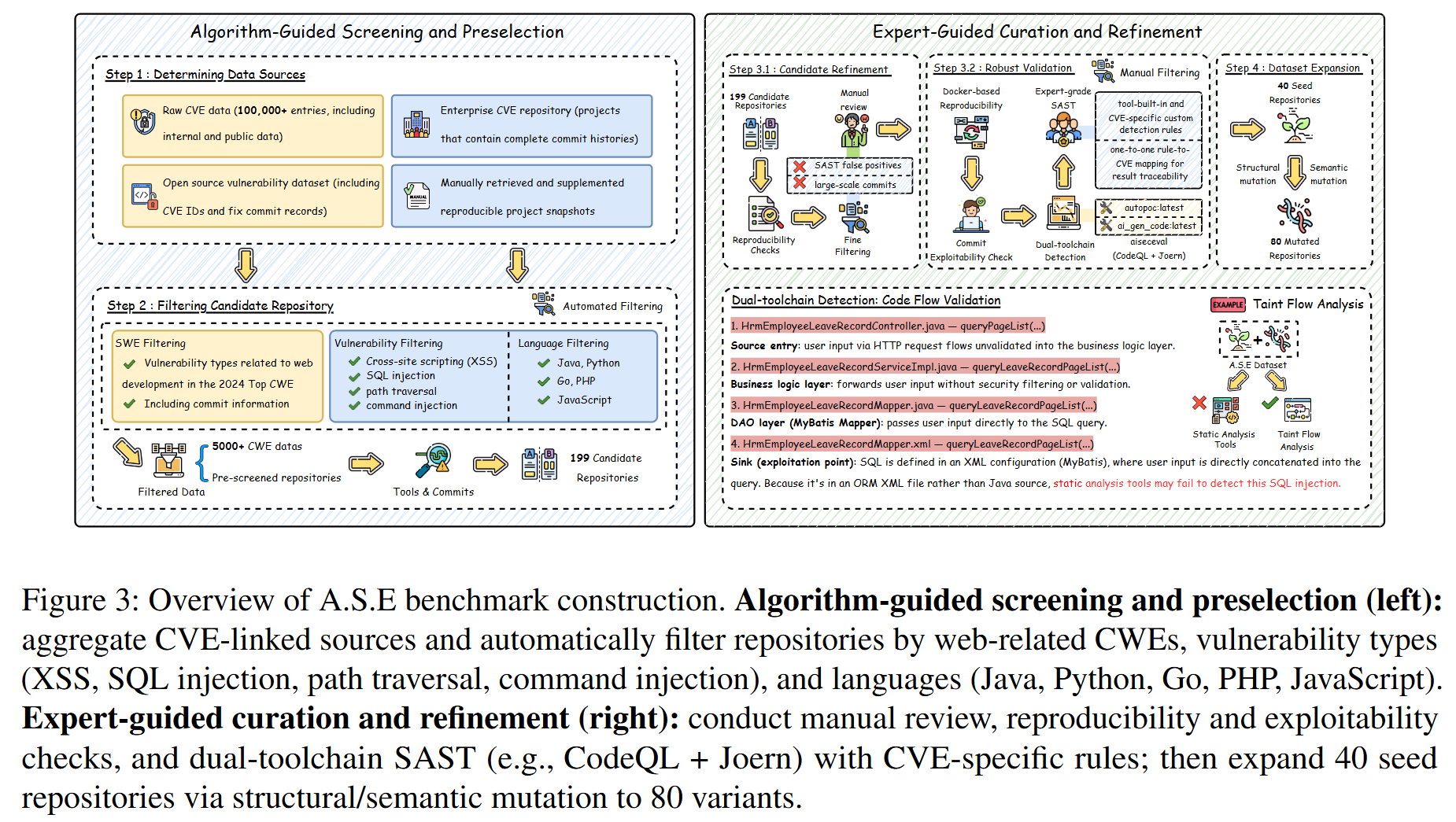
- 实现细节: 基准的构建始于筛选带有CVE的GitHub项目。安全专家精确定位漏洞区域,并构建相应的静态分析规则。随后,通过语义保留的变换(如重命名变量、重构控制流)来扩展数据集,以减轻模型的记忆效应。在评估阶段,每个任务都在一个独立的Docker容器中运行,自动化脚本首先应用模型生成的补丁,然后检查代码是否能成功构建,最后运行定制的SAST工具来计算漏洞数量的变化。
3. 实验设计 (Experimental Design)
- 数据集与预处理: A.S.E 基准包含120个仓库级的漏洞实例,由40个源于真实CVE的种子任务和80个变异任务组成。它涵盖了4种高频的Web漏洞类型(SQL注入、路径遍历、跨站脚本XSS、命令注入)和5种主流编程语言(PHP, Python, Go, JavaScript, Java)。关键的预处理是“掩码”操作,即在漏洞代码区域放置特殊标记
<masked>,让模型来完成填充。 - 对比模型 (Baselines): 实验评估了26个业界领先的(SOTA)大语言模型,包括18个闭源模型(如Claude-3.7-Sonnet, GPT-4o, Grok-3)和8个开源模型(如Qwen3, DeepSeek-V3, GLM-4.5)。选择覆盖面广,且包含了部分模型的“快思考”(直接解码)和“慢思考”(多步推理)版本,选择合理且全面。
- 评估指标 (Metrics): 论文设计了三个核心指标和一个综合分数:
- 质量 (Quality): 衡量生成的补丁能否成功合并,并通过语法和静态检查。
- 安全 (Security): 衡量应用补丁后,检测到的漏洞数量是否减少。
- 稳定 (Stability): 衡量模型在三次独立运行中生成结果的一致性(标准差越小,得分越高)。
- 总分 (Overall): 通过加权平均($0.6 \times \text{Security} + 0.3 \times \text{Quality} + 0.1 \times \text{Stability}$)得到综合性能分数。这些指标共同构成了对模型在真实场景下表现的全面评估。
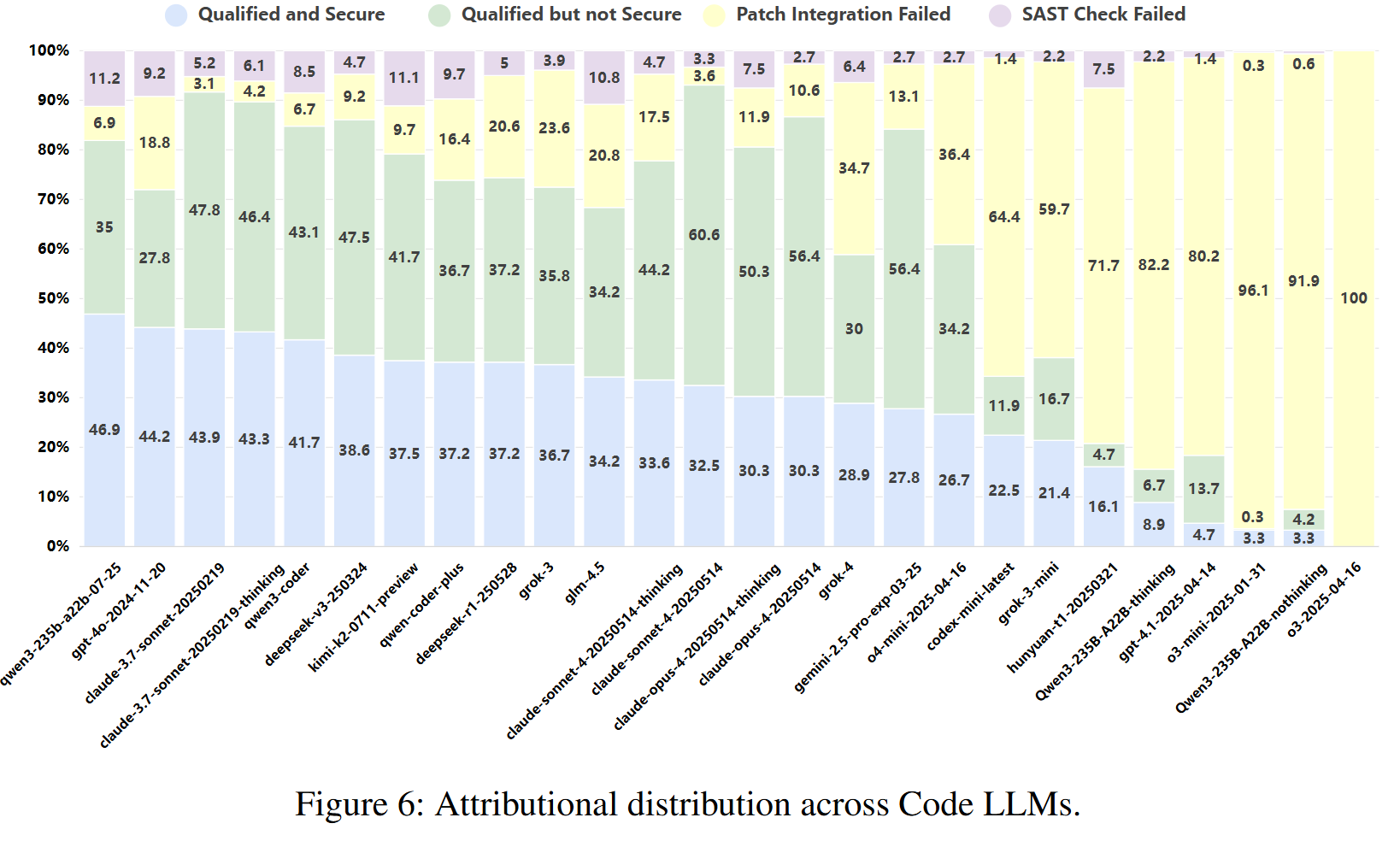
4. 实验结果与分析 (Results & Analysis)
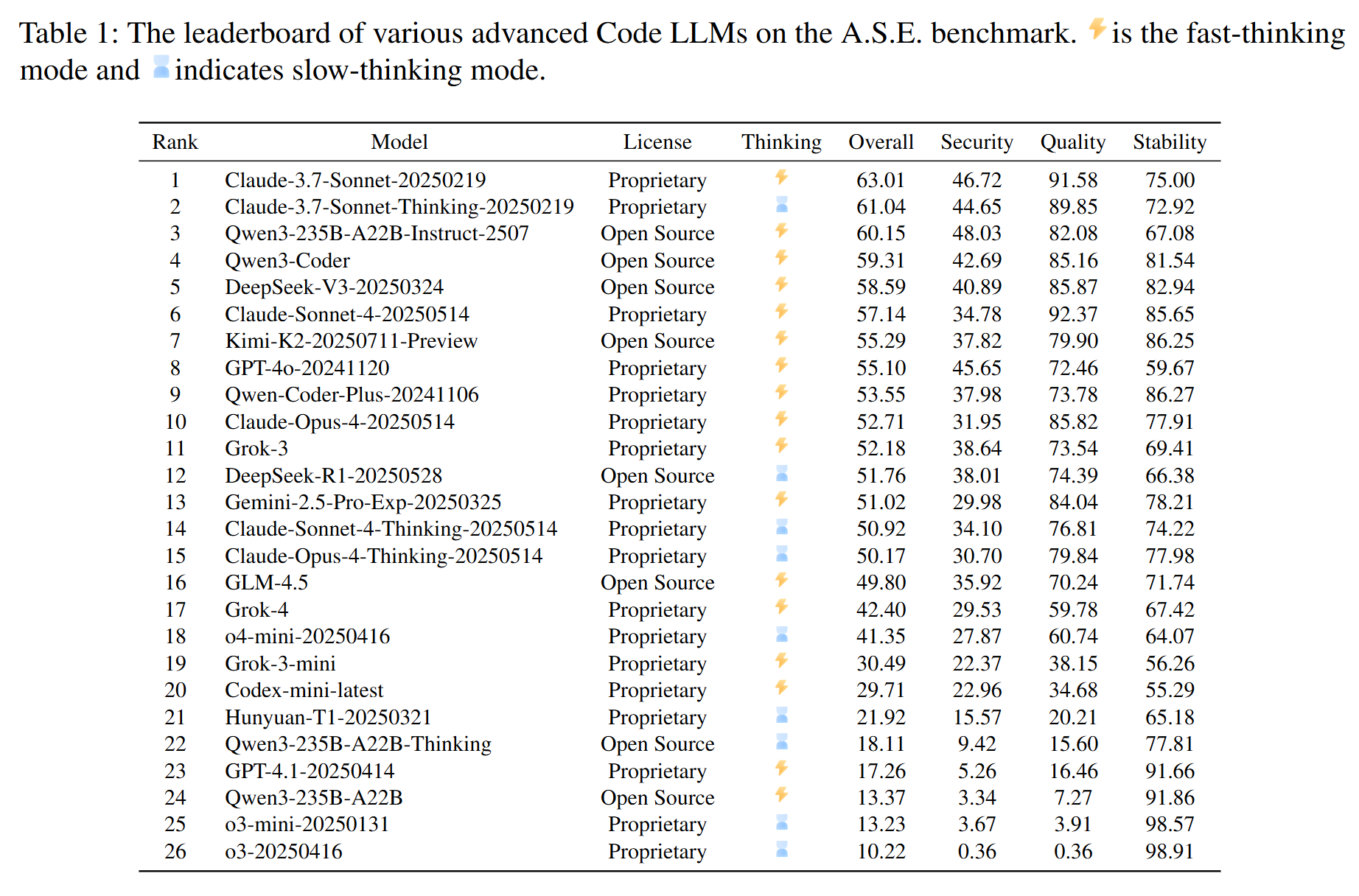
- 主要结果:
- Claude-3.7-Sonnet在总分上排名第一(63.01),展现了最强的综合性能。
- 在安全性单项上,开源模型 Qwen3-235B-A22B-Instruct 取得了最高分(48.03),甚至超过了 Claude-3.7-Sonnet。
- 所有模型的安全分数均未超过50分,表明即便是最先进的LLM在安全编码方面仍有巨大挑战。
- 实验发现简洁的“快思考”解码策略在安全修复任务上的表现普遍优于复杂的“慢思考”策略。
- 开源与闭源模型在安全性能上的差距很小,显示了开源社区的强大竞争力。
- 消融研究 (Ablation Study): 论文没有进行传统意义上的模型组件消融,但其对“快思考”与“慢思考”模式的对比分析(如图5)起到了类似作用。结果表明,增加推理步骤的“慢思考”模式在安全性、质量和稳定性上反而出现了性能衰退,这挑战了“更深思熟虑=更好结果”的直觉假设。
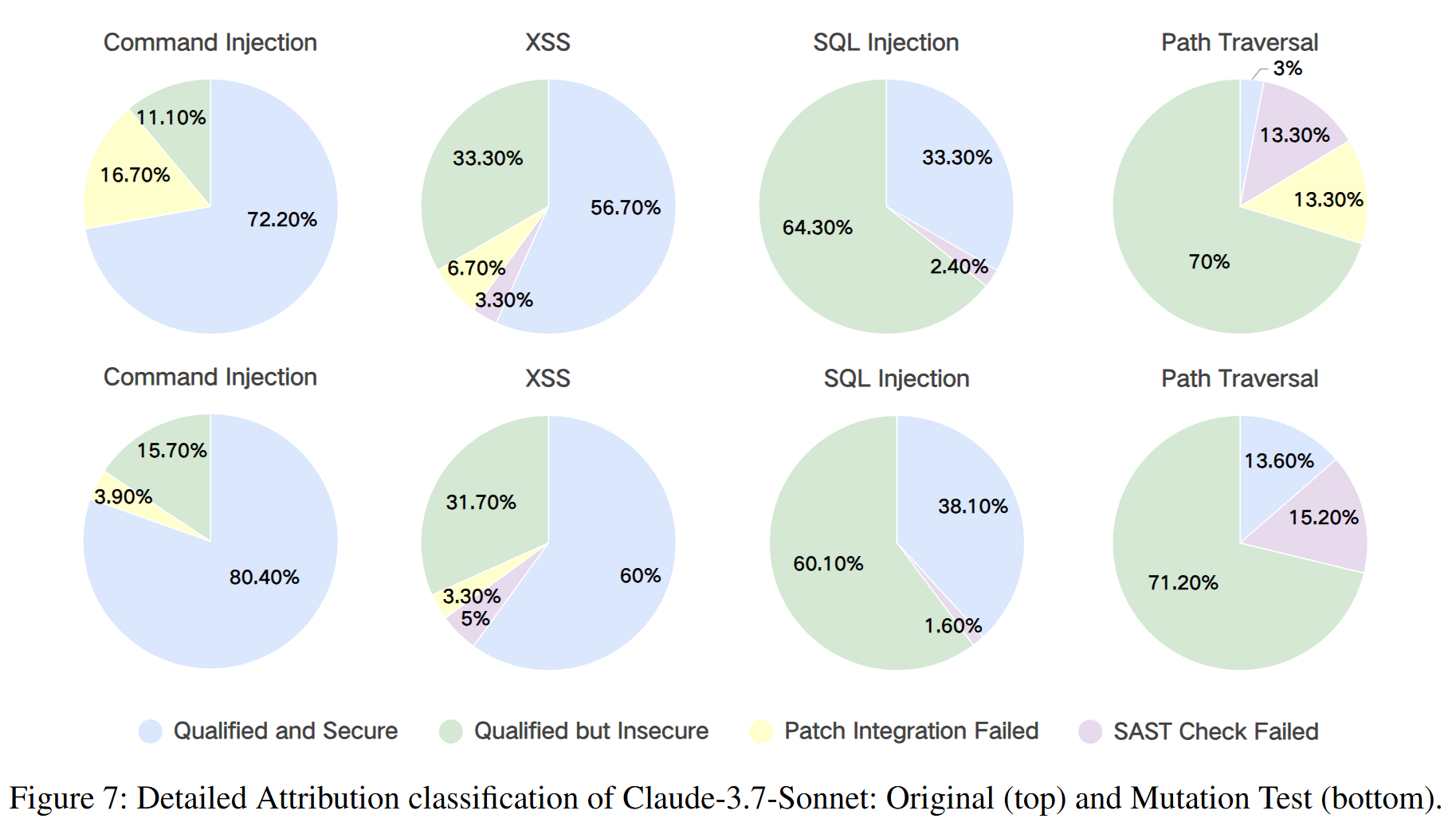
- 案例分析 (Case Study): 论文以Claude-3.7-Sonnet为例进行了深入分析(如图7)。结果显示,该模型在生成语法正确且功能可用的代码方面非常出色(极少出现补丁集成失败或SAST检查失败),但在处理路径遍历和SQL注入等漏洞时,生成的代码虽然“合格”却依然“不安全”的比例很高。这直观地揭示了顶尖模型在“功能正确性”和“安全性”之间的不平衡。
5. 总结与贡献 (Conclusion & Contribution)
- 总结: 论文成功构建并验证了一个新颖的、基于真实世界仓库和CVE的基准A.S.E,用于评估LLM生成代码的安全性。通过对主流LLM的广泛评测,论文揭示了当前模型在仓库级安全编码方面的普遍弱点,并得出了关于“快/慢思考”策略和开源/闭源模型差距的重要发现。
- 核心贡献:
- 提出了首个仓库级的、基于真实CVE的安全代码生成基准A.S.E,弥补了现有研究在真实性、上下文完整性和评估可复现性方面的空白。
- 设计了一套可复现、可审计的自动化评估框架,通过容器化技术和专家定义的规则,为社区提供了一个稳定可靠的评测标准。
- 提供了对当前SOTA LLMs安全能力的深刻洞察,其发现(如“快思考”优于“慢思考”、开源模型竞争力强)对未来LLM的设计、训练和应用具有重要的指导意义。