💭🚩 Internalize the Temperature: On-Policy Self-Distillation as Policy Reheater for Reinforcement Learning
Published in Arxiv, 2026
Arxiv地址:https://arxiv.org/abs/2606.00755
1. 关键词 (Keywords)
- 强化学习可验证奖励 / Reinforcement Learning from Verifiable Rewards (RLVR)
- 熵塌缩 / Entropy Collapse
- 策略复温 / Policy Reheating
- Rollout Reheating vs. Policy Reheating
- On-Policy Self-Distillation (OPSD)
- Temperature-Scaled OPSD / TS-OPSD
- Forward KL / Reverse KL
- Continued RL / 继续强化学习
2. 背景与动机 (Background & Motivation)
问题定义
论文关注 RLVR 训练中的一个关键瓶颈:随着 RL 推进,模型策略会逐渐变得尖锐,输出分布熵下降,rollout 多样性减少,后续可学习信号枯竭。这种现象通常被称为 entropy collapse。
在数学推理等任务中,RL 初期能显著提升模型能力,但训练后期经常出现:
- policy 分布过度集中;
- 多次采样得到的轨迹越来越相似;
- 高价值探索路径难以被采到;
- reward 增长放缓;
- 继续 RL 的边际收益下降。
这意味着,训练瓶颈不只是“模型还不够强”,而是 policy 已经变得太确定,缺少继续探索和产生有效梯度的空间。
现有方法的局限
已有缓解方式大致有两类:
- 目标函数层面的约束:例如 entropy regularization、entropy-preserving update、adaptive clipping 等。
- rollout 采样层面的调温:例如提高 rollout collection 时的 sampling temperature。
这些方法都能在一定程度上恢复探索,但它们有共同问题:温度或熵干预仍然停留在模型参数之外。换言之,采样时可以“加热”,但模型本身的默认分布没有变;这会造成 behavior policy 与 optimized policy 的不一致,也限制了继续 RL 的效果。
核心问题
论文提出一个直接的问题:
能否把 temperature 的探索效果“内化”进模型参数,让 reheated policy 本身成为继续 RL 的更好初始化?
这就是本文的核心:Internalize the Temperature。
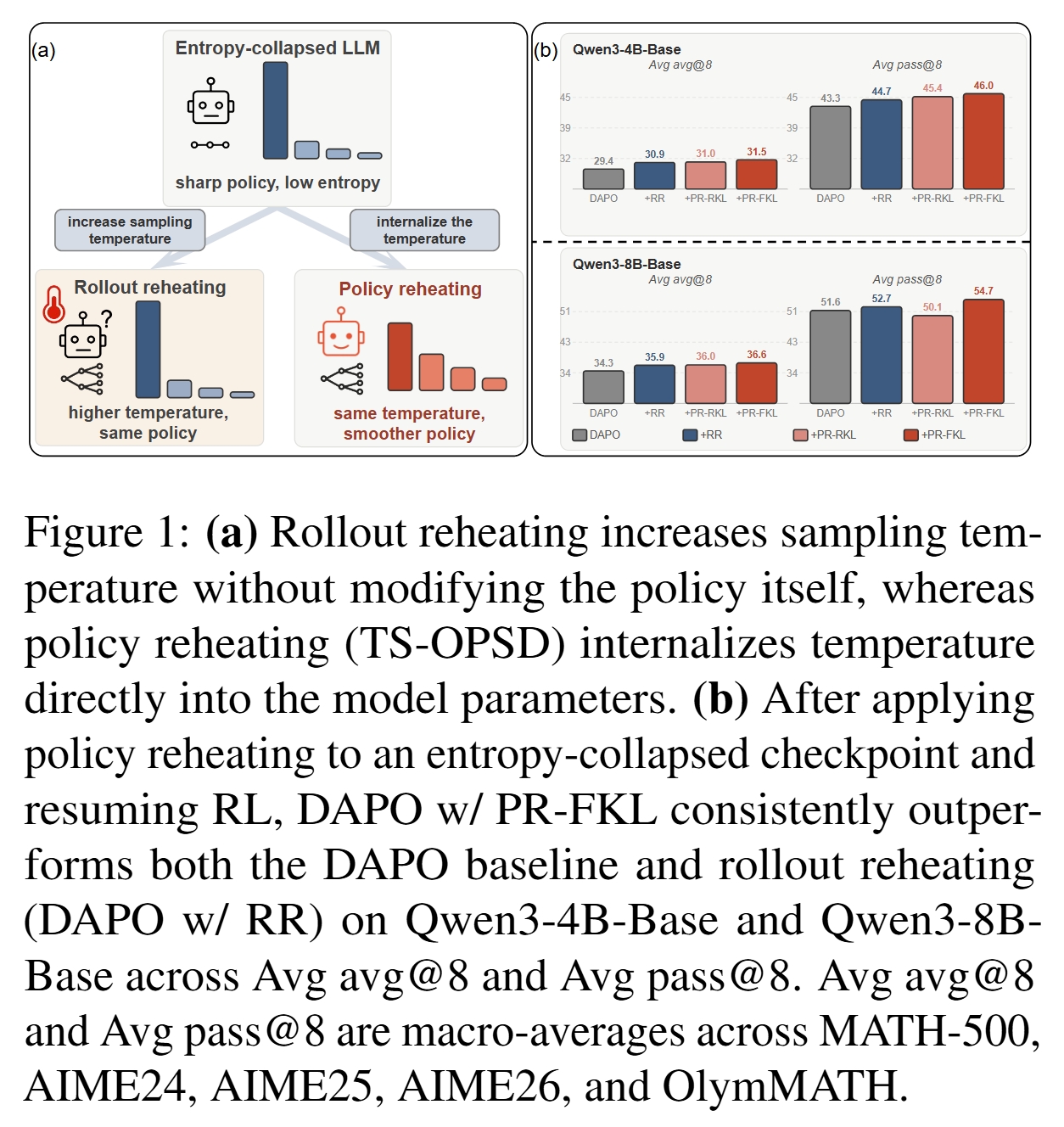
3. 核心方法 (Core Methodology)
整体思路:Policy Reheating
本文提出 Temperature-Scaled On-Policy Self-Distillation (TS-OPSD)。它不是在 rollout 时临时提高温度,而是在 entropy-collapsed checkpoint 上做一次轻量级自蒸馏,将高温分布的平滑性写回模型参数。
整体流程是:
也就是说:
- 先用 DAPO/RLVR 训练到 entropy collapse;
- 对 collapsed checkpoint 做 TS-OPSD;
- 得到更高熵、更平滑但仍保持推理偏好的 reheated policy;
- 从这个 checkpoint 继续标准 RL。
Temperature-Scaled Self Teacher
给定当前模型 logits z_theta,TS-OPSD 构造一个高温 self-teacher:
q_T(v | x_<t) = exp(z_{theta,v} / T) / sum_u exp(z_{theta,u} / T)其中 T > 1 会让分布更平滑。关键是:teacher 来自模型自己的 logits,不需要外部 teacher、不需要 privileged data,也不需要额外推理模型。
Internalize the Temperature
TS-OPSD 的结构性质是:
p_T(v) ∝ q_theta(v)^(1/T)因此,高温 teacher 与原 student 保持相同 token ranking,只改变分布 sharpness。这与普通 KD 不同:普通 teacher 可能和 student 在语义偏好、tail token、support set 上发生错配,而 TS-OPSD 的 teacher 是 student 自身的平滑版本。
直观理解:
- 不改变模型“认为哪些 token 更合理”的排序;
- 不引入外部答案或外部偏好;
- 只压缩 top candidates 之间的 logit margin;
- 让低概率但仍在模型支持集内的推理分支重新有机会被采样。
FKL 与 RKL
论文比较了两种 KL 方向:
- PR-FKL:用 forward KL 让 student 拟合高温 self-teacher;
- PR-RKL:用 reverse KL 做同样的 policy reheating。
理论上,FKL 的 logit 梯度形式为 q_theta(v) - p_T(v),更像是沿着模型原有偏好几何做 structured smoothing。RKL 在 self-temperature coupling 下近似为 entropy maximization:
grad_z L_RKL = -(1 - 1/T) * grad_z H(q_theta)因此,RKL 更像通用地抬高 entropy;FKL 则更明确地匹配一个由模型自身偏好诱导出的高温目标分布。实验中 PR-FKL 整体优于 PR-RKL。
4. 实验设计 (Experimental Design)
模型与训练数据
实验使用:
- Qwen3-4B-Base;
- Qwen3-8B-Base;
- 训练数据:DAPO-Math-17K;
- 基础 RL 方法:DAPO,基于 verl 实现。
policy reheating 在 mean token entropy 低于 0.08 nats 的 collapsed checkpoint 上执行;随后使用相同 RL 超参数继续训练。
评估基准
论文评估五个数学推理基准:
- MATH-500;
- AIME24;
- AIME25;
- AIME26;
- OlymMATH。
每个 benchmark 报告:
- avg@8:8 次采样平均准确率;
- pass@8:8 次采样中至少一次正确的概率;
- Avg:五个 benchmark 的宏平均。
评估采样设置为 temperature T = 1.0、top-p = 0.7。
对比方法
主要比较:
- Base:未 RL 的 base checkpoint;
- DAPO:标准 RL,训练到 entropy collapse;
- DAPO w/ RR:Rollout Reheating,即继续 RL 时把 rollout temperature 提高到
T = 1.2; - DAPO w/ PR-RKL:使用 RKL 的 policy reheating 后继续 RL;
- DAPO w/ PR-FKL:使用 FKL 的 policy reheating 后继续 RL。
OPSD 训练使用 teacher temperature T = 1.2、learning rate 1e-6、effective batch size 1024、full-vocabulary KL,并用 on-policy rollouts 训练。RL、OPSD 和 evaluation 的完整超参见原文 Table 3、Table 4、Table 5。
5. 实验结果与分析 (Results & Analysis)
主结果:Policy Reheating 优于 Continued RL 和 Rollout Reheating
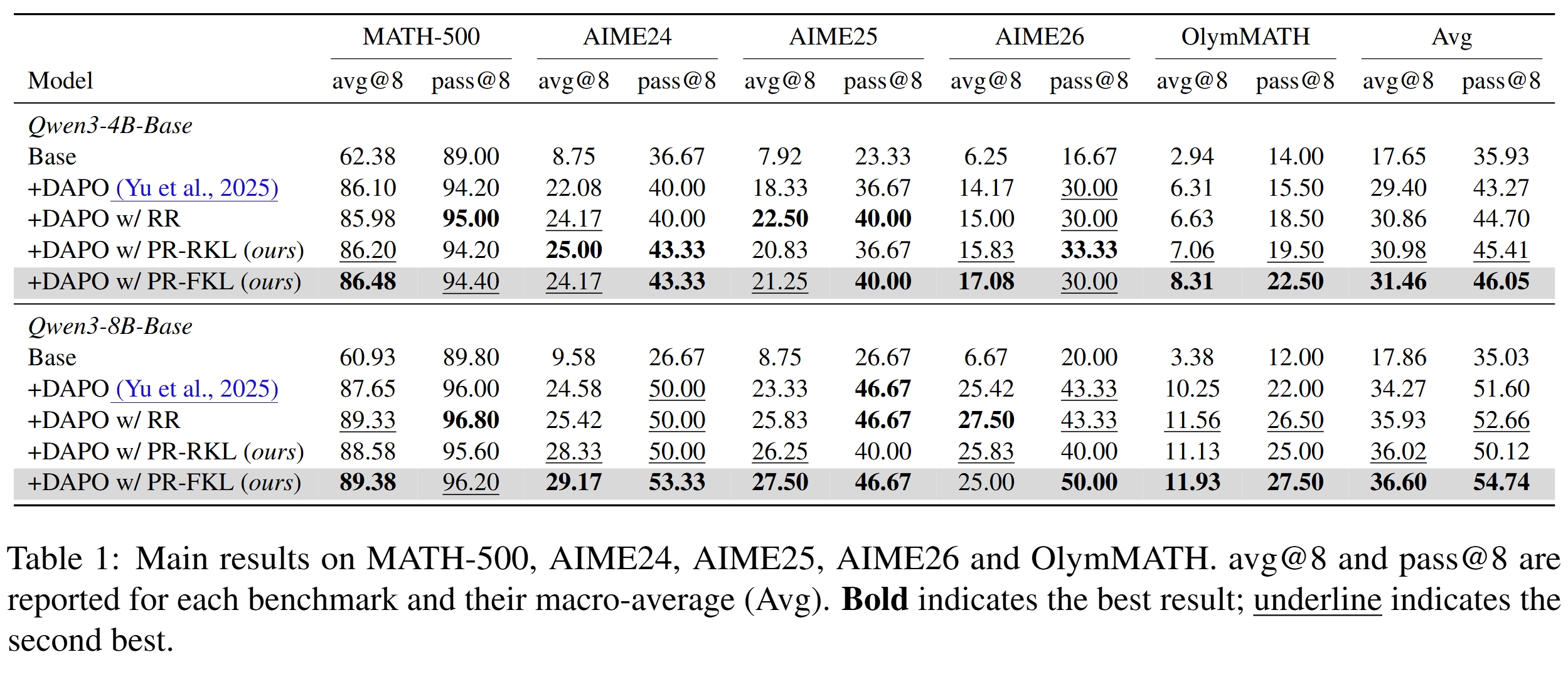
在 Qwen3-4B-Base 上:
- DAPO 的 Avg avg@8 / pass@8 为 29.40 / 43.27;
- DAPO w/ RR 提升到 30.86 / 44.70;
- DAPO w/ PR-RKL 提升到 30.98 / 45.41;
- DAPO w/ PR-FKL 最好,达到 31.46 / 46.05。
在 Qwen3-8B-Base 上:
- DAPO 的 Avg avg@8 / pass@8 为 34.27 / 51.60;
- DAPO w/ RR 提升到 35.93 / 52.66;
- DAPO w/ PR-RKL 为 36.02 / 50.12;
- DAPO w/ PR-FKL 最好,达到 36.60 / 54.74。
这说明:
- entropy collapse 后继续标准 RL 的收益有限;
- rollout reheating 已经能带来一定收益;
- policy reheating 进一步提升,尤其 PR-FKL 在 4B 和 8B 上都取得最高宏平均。
Entropy Collapse 会拖慢标准 RL
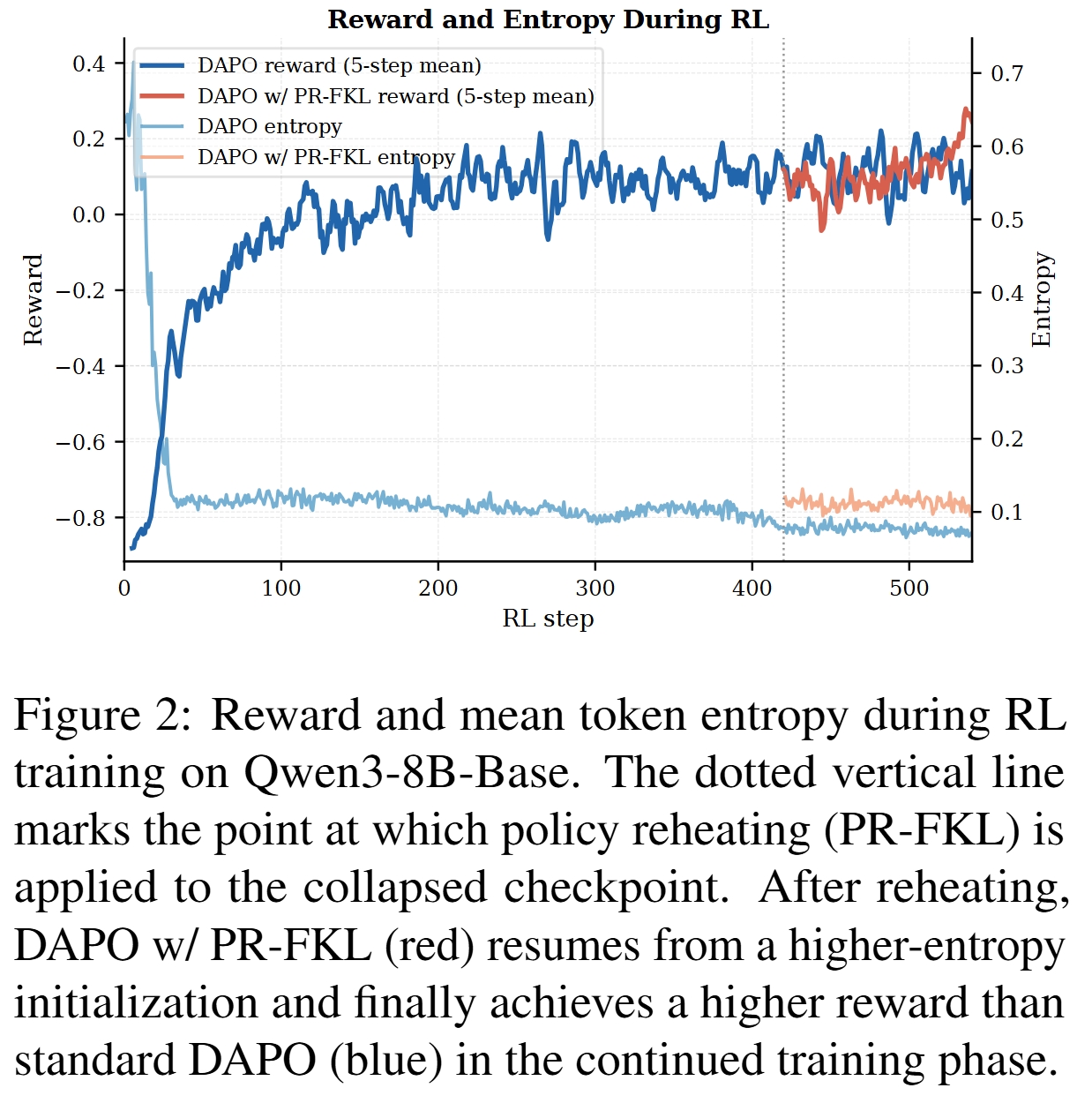
Qwen3-8B-Base 的 RL 曲线显示,标准 DAPO 的 token entropy 在训练早期快速下降,并长期保持低位;对应地,reward 增长在后期明显放缓。PR-FKL 在 collapsed checkpoint 上复温后,以更高 entropy 初始化继续 RL,最终 reward 高于标准 DAPO。
这一现象支持论文的核心判断:entropy collapse 不是只影响采样多样性,而是会直接限制后续 RL 的有效学习。
Policy Reheating 改变什么:主要改变输出 sharpness
论文进一步分析 TS-OPSD 对模型内部的影响,结论是:它主要改变输出分布的 sharpness,而不是破坏中间表示、候选支持集或推理能力。
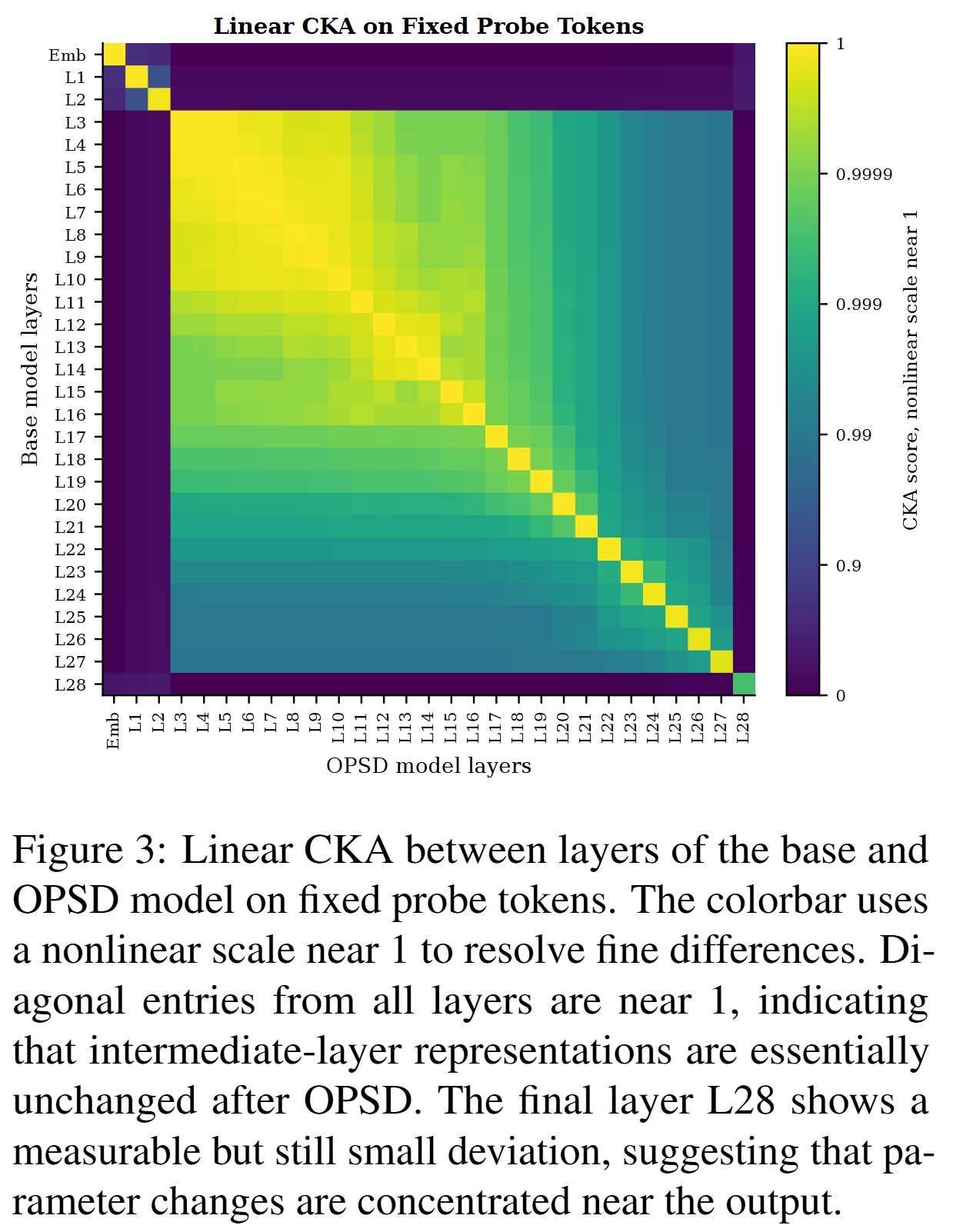
中间表示基本不变
见 Figure 3。Linear CKA 显示 reheating 前后各层对角线相似度几乎都接近 1,说明中间层表示基本保持不变,变化主要集中在靠近输出层的位置。
推理能力保持稳定
见 Figure 4。在 FKL OPSD 训练过程中,MATH-500 和 GPQA Main 的准确率没有随着 entropy 上升而系统性下降,说明复温不是用能力换多样性。

输出分布做 support-preserving redistribution
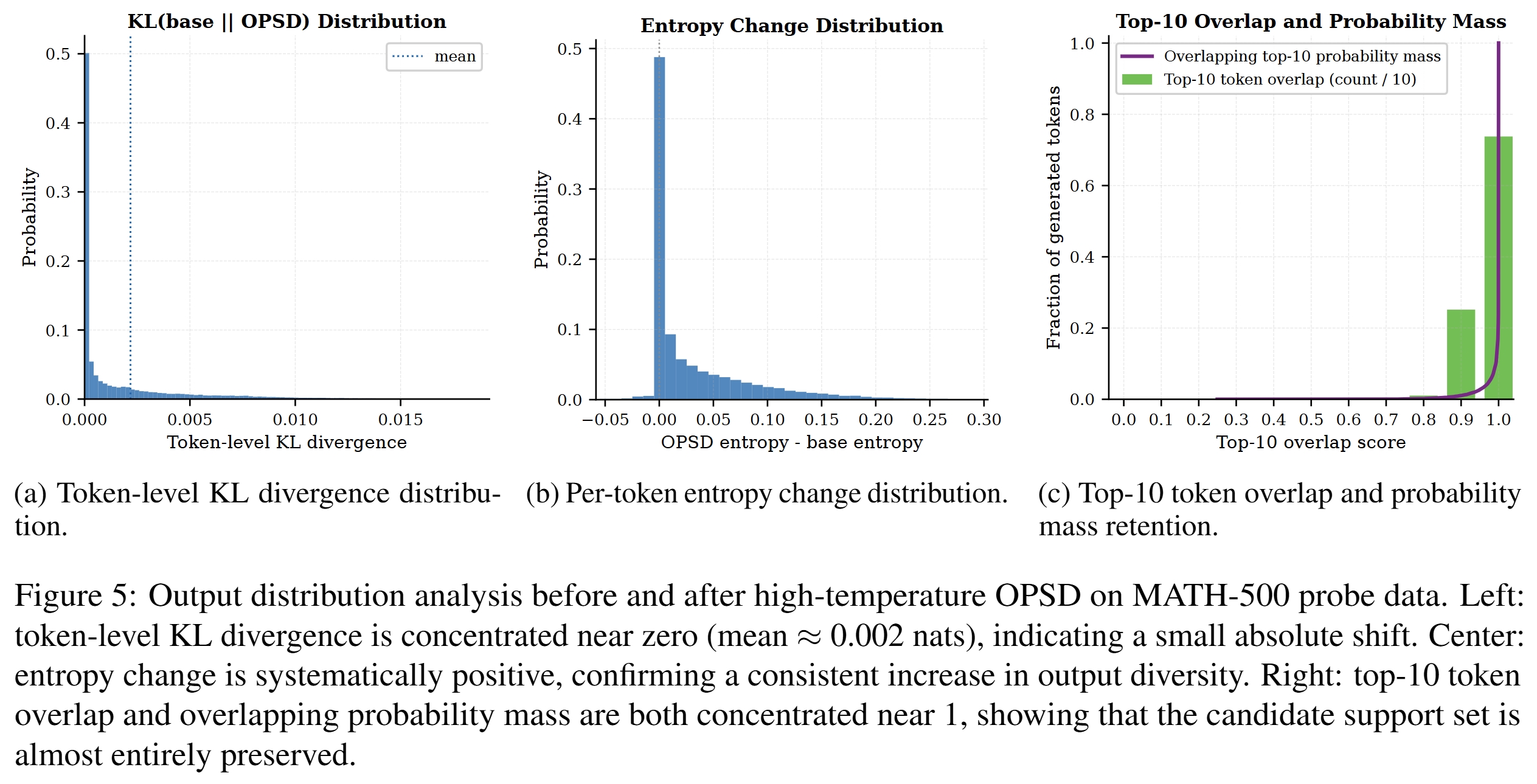
见 Figure 5。token-level KL 分布集中在 0 附近,均值约 0.002 nats;per-token entropy change 系统性为正;top-10 token overlap 与 overlapping probability mass 都集中在 1 附近。也就是说,TS-OPSD 不是引入新语义候选,而是在原有候选集合内重新分配概率。
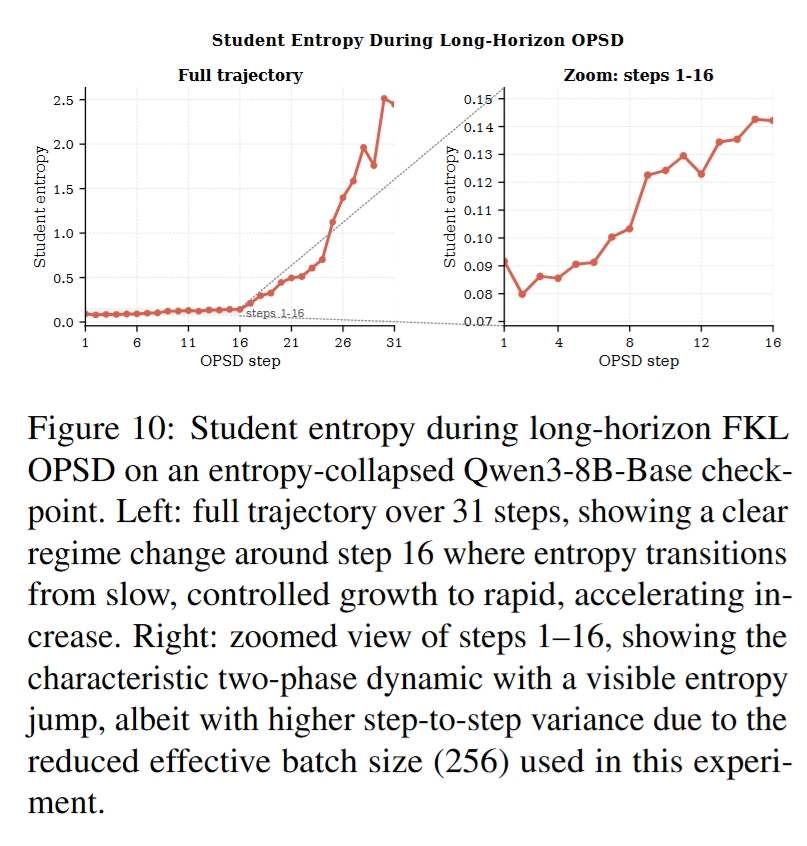
Entropy Jump:从局部平滑到真实探索

OPSD 训练中的 entropy 不是线性增长,而是出现两阶段动态:
- Slow phase:先缓慢增加,主要是在已有 top candidates 之间压缩 margin;
- Jump phase:随后出现 discontinuous entropy jump,一些低概率推理路径跨过采样阈值,进入 on-policy rollout 分布。
Figure 6 的 stochastic log-probability trace 显示,post-jump checkpoints 从约 token position 50 开始明显采样更低概率的后续路径。Table 2 也显示:
- fork position 从 jump 前约 56–57 提前到 jump 后约 48–50;
|Log-Prob|从 Ckpt-8 的 0.0613 上升到 Ckpt-9 的 0.0738;- edit distance 也有同步上升。
这说明 entropy jump 对应的不是表面随机性,而是生成轨迹更早分叉,并进入更低概率但仍有意义的推理分支。
FKL vs. RKL:同样复温,不同用途
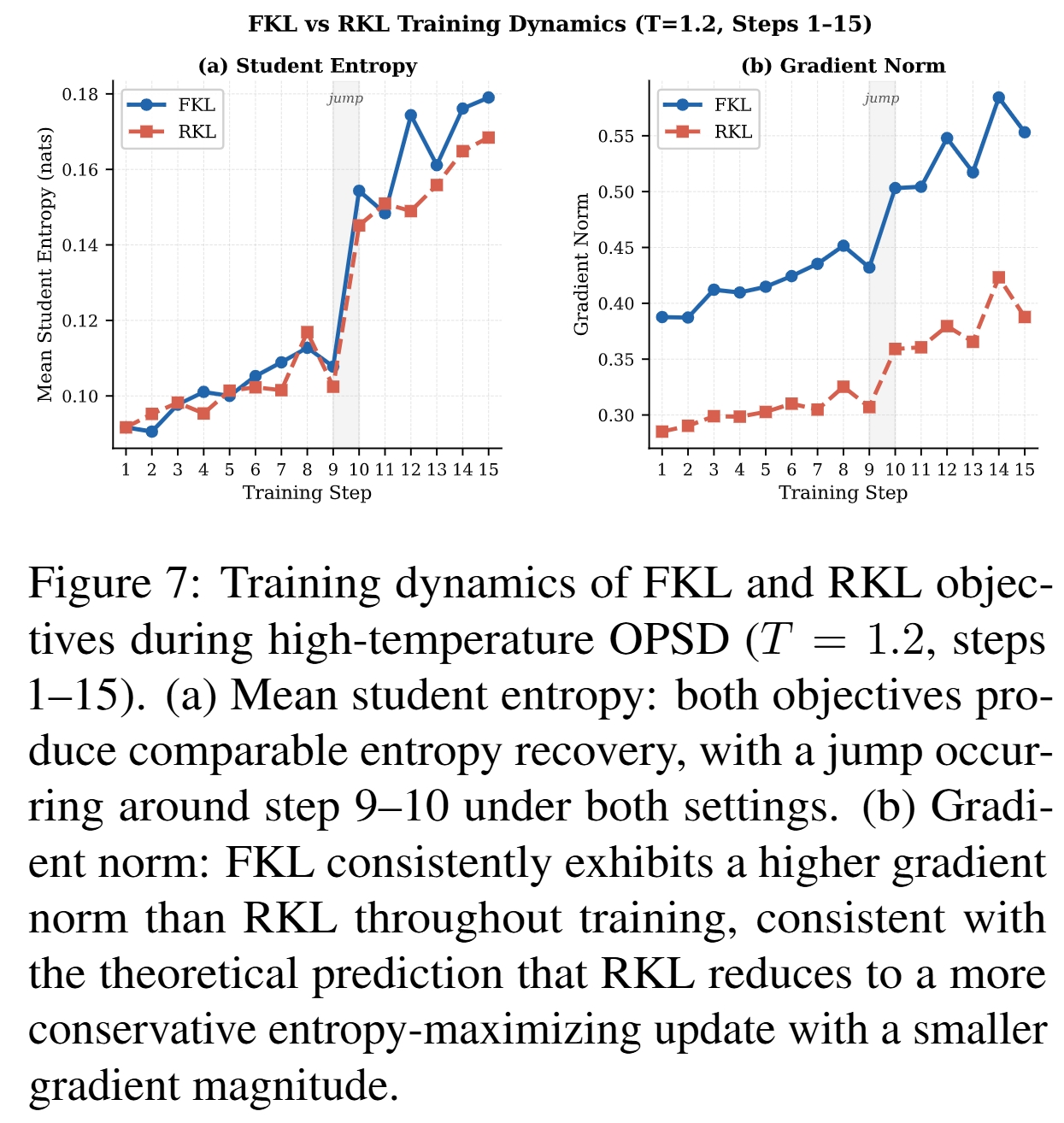
FKL 和 RKL 都能恢复 entropy,但梯度结构不同:
- RKL 在 self-temperature teacher 下近似等价于 entropy maximization,更新更保守;
- FKL 更像对模型自身偏好几何进行 structured smoothing;
- FKL 的 gradient norm 更大,并在继续 RL 中带来更好的最终性能。
这解释了为什么 PR-RKL 也能复温,但 PR-FKL 在主结果中更稳定地提升继续 RL 的上限。
温度敏感性与适用范围
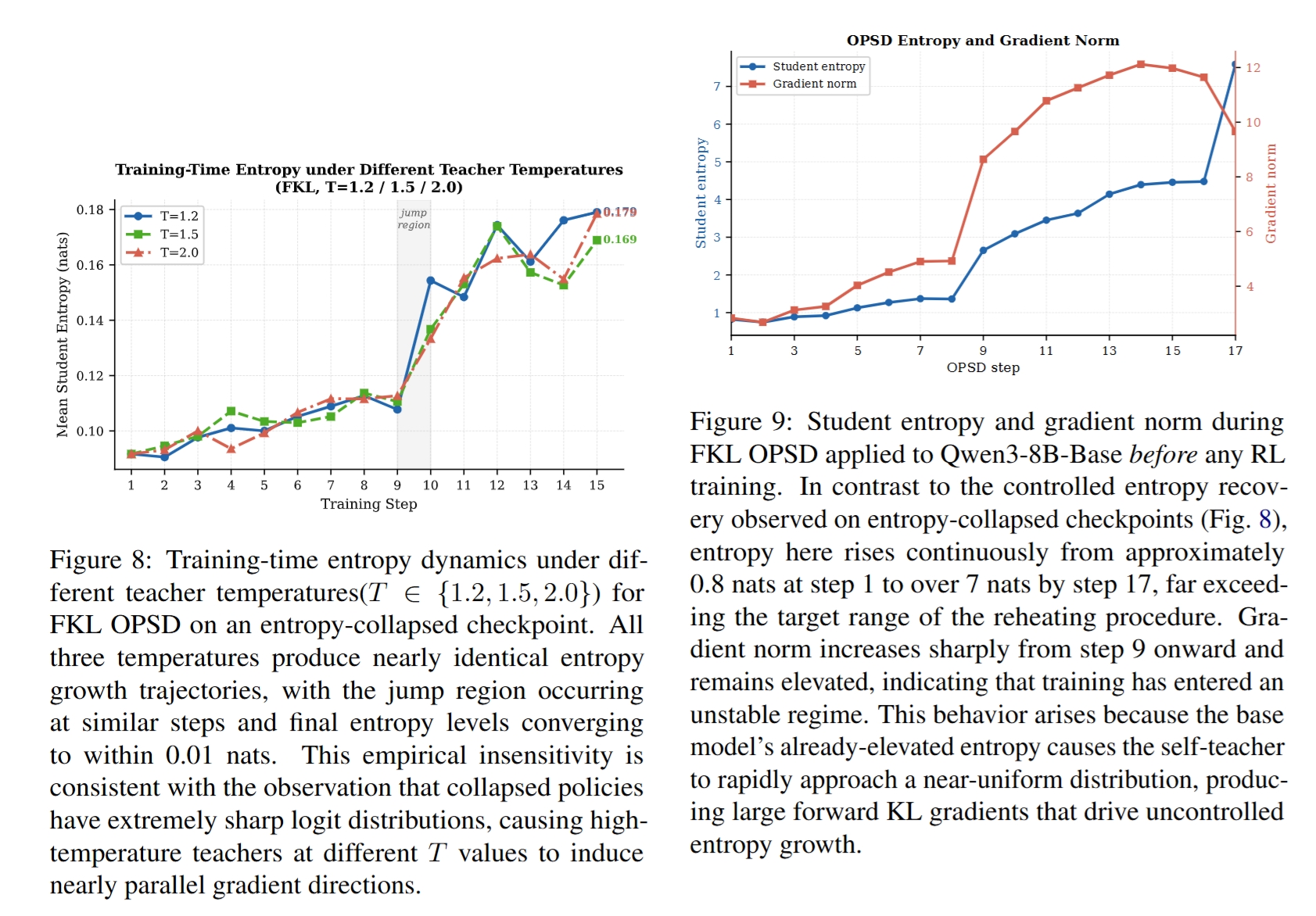
在 entropy-collapsed checkpoint 上,FKL OPSD 对 teacher temperature T in {1.2, 1.5, 2.0} 并不敏感,三条 entropy growth 轨迹几乎重合,最终差异小于 0.01 nats。这是因为 collapsed policy 的分布极尖锐,不同高温 teacher 的梯度方向近似平行。
但这也意味着 TS-OPSD 不是通用“提高 entropy”工具。若把它用于尚未 RL 的 base model,entropy 会快速失控上升,gradient norm 也会变大。因此,论文强调 TS-OPSD 应被视为 post-collapse reheating tool,需要由当前 policy entropy 触发。
附加分析:反向复温、数据稀缺与计算成本
论文附录还提供了三个有价值的补充结论:
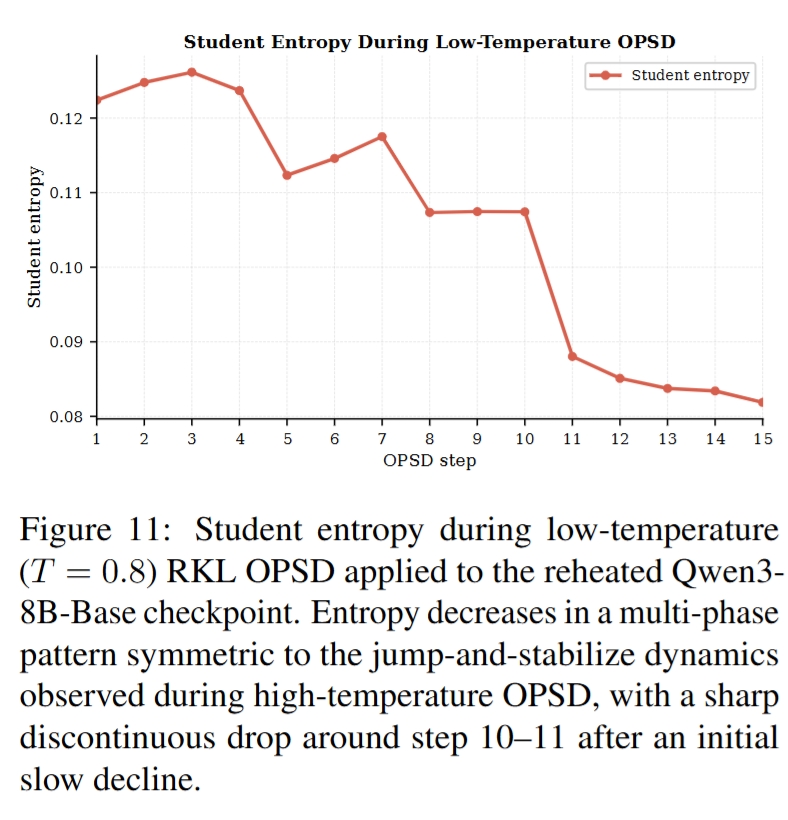
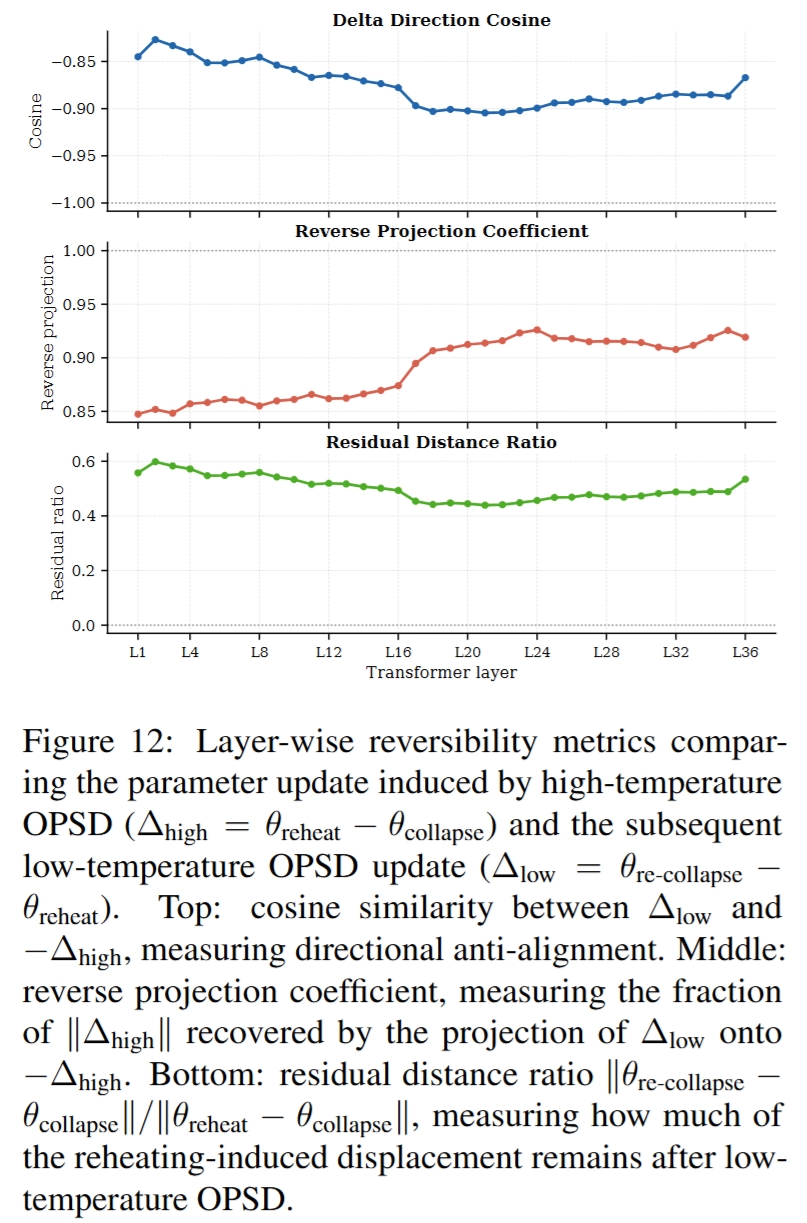
- Low-temperature OPSD 近似反向操作:见 Figure 11、Figure 12。对 reheated checkpoint 做 low-temperature RKL OPSD 会使 entropy 下降,并产生与高温更新强反向对齐的参数更新;但只能部分回到原 collapsed checkpoint。
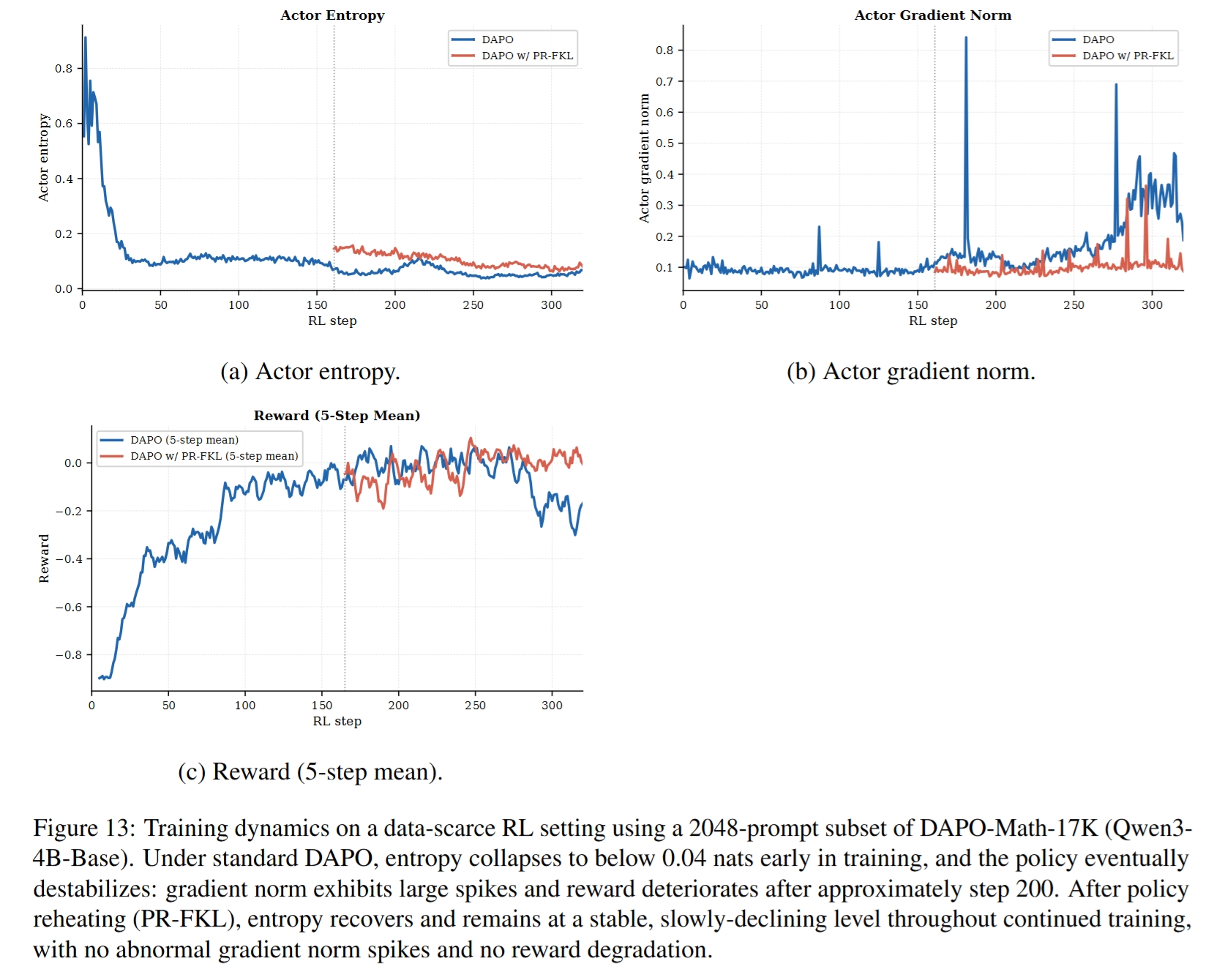
- 数据稀缺设置下更稳定:见 Figure 13。在只用 2048 条 DAPO-Math prompt 的数据稀缺 RL 设置中,标准 DAPO 更容易严重塌缩并出现 reward 退化;policy reheating 后继续 RL 能维持更稳定的 entropy、gradient norm 和 reward。
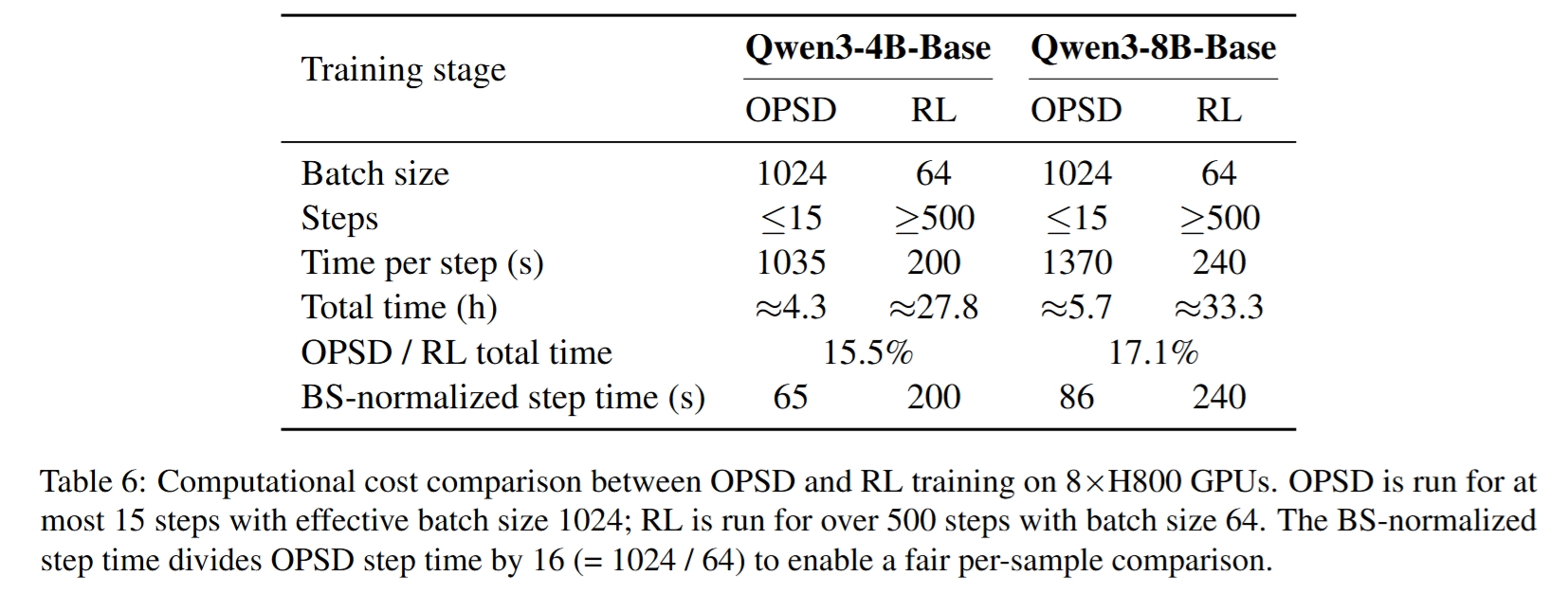
- 计算开销可控:见 Table 6。一次 OPSD 复温约需 4.3 小时(4B)或 5.7 小时(8B),约为完整 RL 训练时间的 15–17%;按 batch size 归一后,OPSD 单样本 step time 低于 RL。
6. 总结与贡献 (Conclusion & Contribution)
主要结论
本文提出的核心结论是:entropy restoration 可以从 RL objective 中解耦出来,作为 entropy collapse 后的模块化 inter-stage operation。相比只在 rollout 采样时提高 temperature,TS-OPSD 将高温探索效果内化进模型参数,使 reheated policy 本身成为更好的 continued RL 初始化。
核心贡献
- 提出 policy reheating 视角:把 entropy collapse 后的恢复问题从 rollout-level control 提升到 parameter-level intervention。
- 提出 TS-OPSD 方法:用模型自己的 high-temperature logits 构造 self-teacher,并通过 on-policy self-distillation 写回模型参数。
- 区分 rollout reheating 与 policy reheating:实验证明后者比单纯提高 rollout temperature 更能提升 continued RL 上限。
- 揭示 support-preserving smoothing 机制:TS-OPSD 主要降低 output sharpness,同时保留中间表示、top candidates 和推理能力。
- 分析 KL 方向与训练动态:解释 FKL/RKL 的差异、entropy jump 现象、温度不敏感性和 post-collapse 适用边界。