🚩 [TMLR 2026] A Survey of Reasoning in Autonomous Driving Systems: Open Challenges and Emerging Paradigms
Published in TMLR, 2026
关键词 (Keywords):
- 自动驾驶 / Autonomous Driving
- 推理 / Reasoning
- 大语言模型 / 多模态大模型(LLM / MLLM)
- 认知层级 / Cognitive Hierarchy
- 长尾场景 / Long-tail Scenarios
- 社会博弈 / The Social Game
- 基准与评测 / Benchmarks and Evaluation
OpenReview(TMLR):https://openreview.net/forum?id=XwQ7dc4bqn
Arxiv地址:https://arxiv.org/abs/2603.11093
PDF:https://openreview.net/pdf?id=XwQ7dc4bqn
Accepted by TMLR
1. 背景与动机 (Background & Motivation)
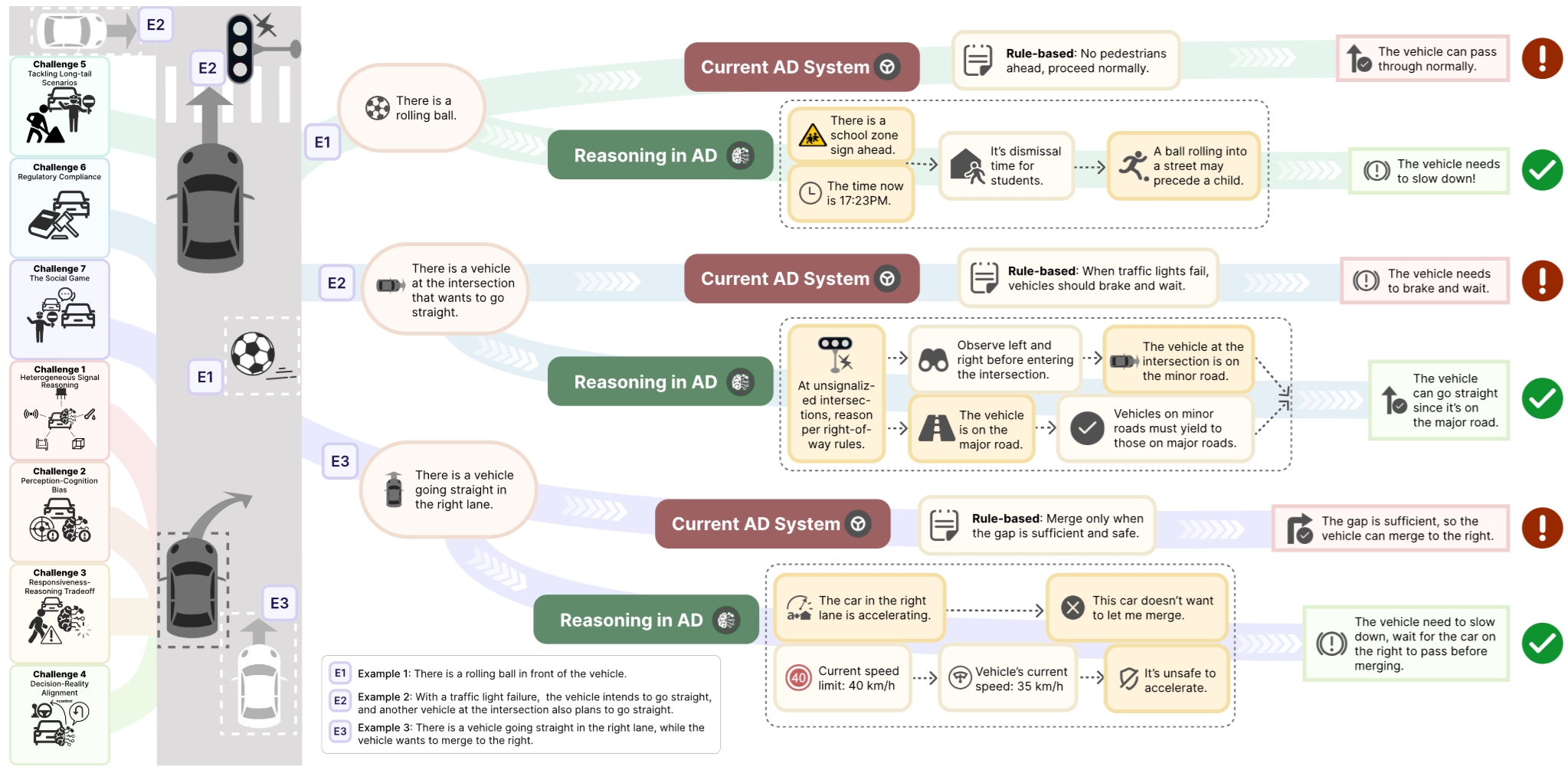
本文的基本判断是:高阶自动驾驶的主要瓶颈正在由感知能力不足,转向稳健且可泛化的推理能力不足。现有 AD 系统在结构化环境中已经具备较强的感知、跟踪与基础决策能力,但在长尾场景、规则冲突场景以及复杂社会交互场景中,仍然容易出现系统性失效,例如对临时施工区、遮挡风险、无信号路口博弈以及交通参与者隐含意图的处理不够稳健。
我们进一步指出,Waymo、Cruise 等真实部署案例中暴露出的关键问题,并不完全来源于传感器精度或单点模块误差,更深层地体现为 prediction discrepancy、planning discrepancy 以及缺乏上下文约束的决策逻辑。与此同时,LLM 与 MLLM 的快速发展为自动驾驶提供了新的技术路径:将推理能力由传统系统中的附属能力提升为整个 AD 系统的认知核心(cognitive core),从而使系统从模式匹配走向面向场景理解、约束协调与决策解释的综合推理。
基于此,我们关注的并不是在既有模块化 AD 管线中额外叠加一个推理模块,而是重新审视如下问题:推理应如何作为统一的高层认知能力,协调感知、预测、规划与控制,并支撑复杂开放环境中的可靠决策。
2. 核心框架:认知层级与七大挑战 (Core Framework)
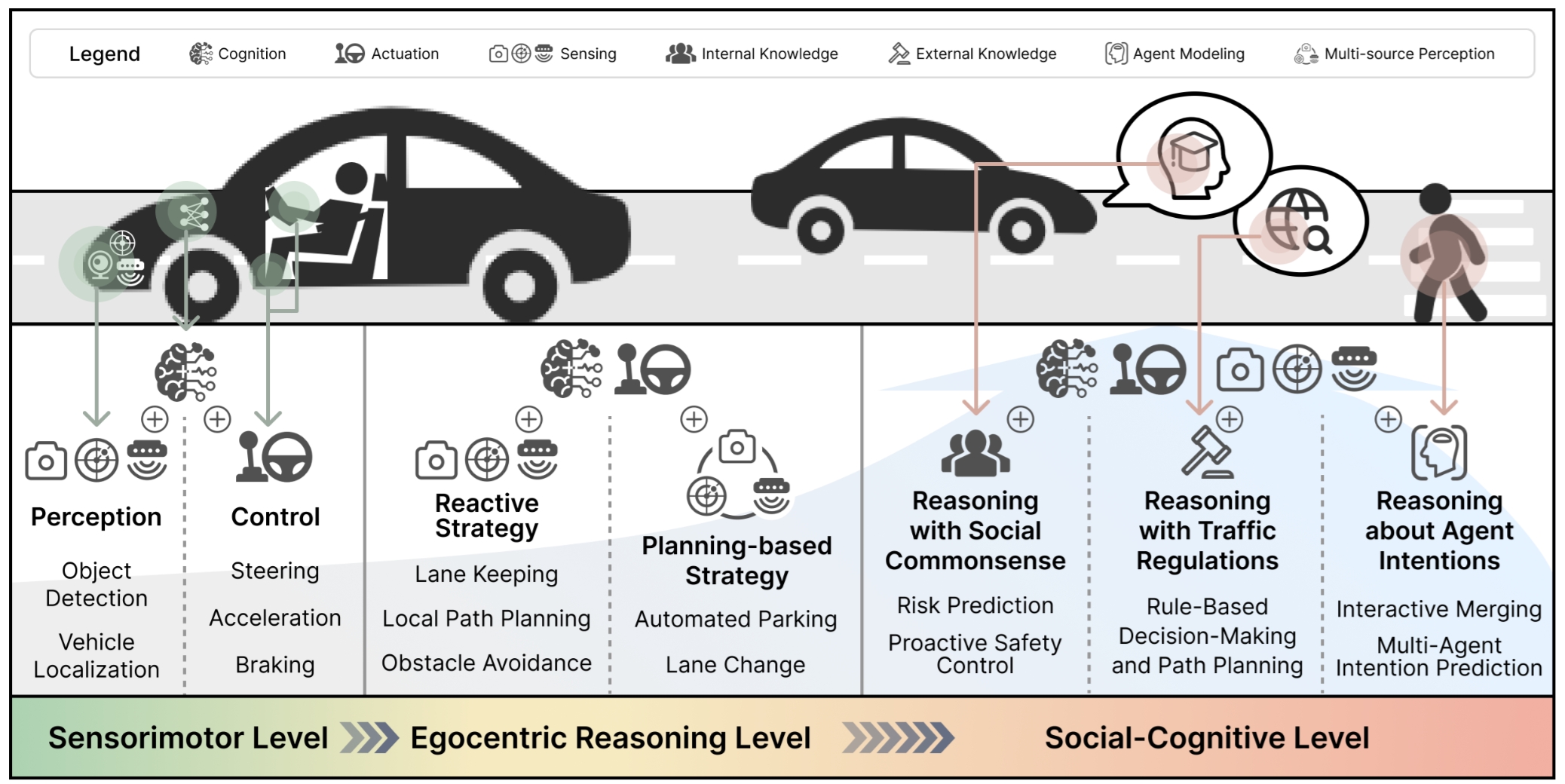
本文最重要的理论贡献之一,是提出了一个面向自动驾驶推理的认知层级(Cognitive Hierarchy)。我们将原本相对整体化的“驾驶任务”分解为三个层次:
- Sensorimotor Level:感知与控制层,处理基础的感知输入与执行输出。
- Egocentric Reasoning Level:自车中心推理层,关注与周围交通参与者的闭环互动,例如避障、跟车、并线、停车等。
- Social-Cognitive Level:社会认知层,要求系统理解交通规则、社会常识、他人意图与隐性协商机制,真正成为交通系统中的“社会参与者”。
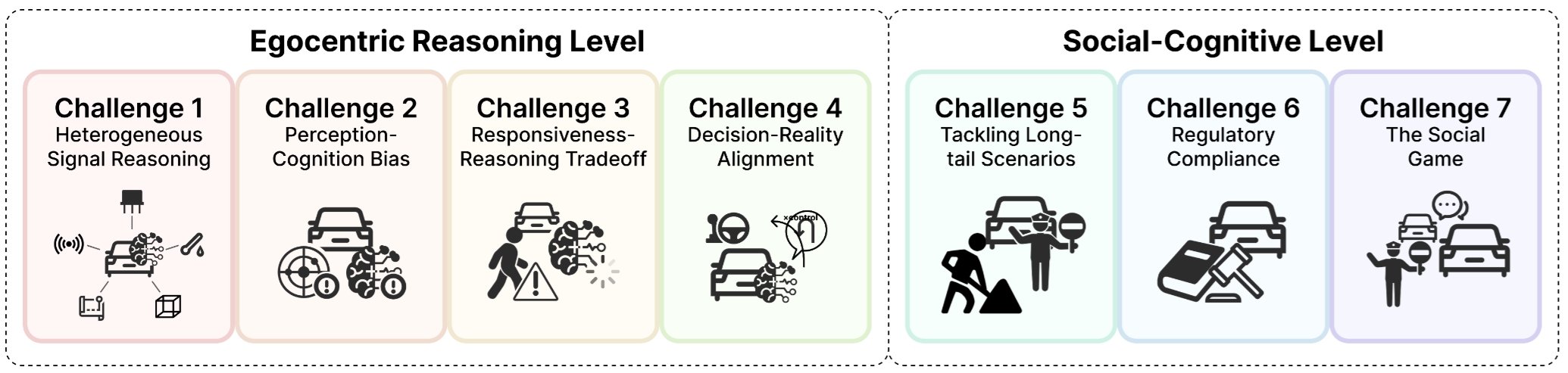
在这一层级框架之上,我们进一步系统化了七大核心推理挑战,并以此构成全文的问题刻画框架:
- Heterogeneous Signal Reasoning:如何融合相机、LiDAR、雷达、地图等异构信号,形成统一世界模型。
- Perception-Cognition Bias:如何处理传感器失真、模型幻觉与认知偏差,保证系统对环境理解可靠。
- Responsiveness-Reasoning Tradeoff:如何在毫秒级反应要求和大模型深度推理延迟之间取得平衡。
- Decision-Reality Alignment:如何让高层语义决策与车辆动力学约束、道路物理约束严格对齐。
- Tackling Long-tail Scenarios:如何在缺乏直接经验的数据稀缺场景中,依靠常识与推理完成泛化。
- Regulatory Compliance:如何在复杂、多地域、动态变化的交通法规体系下做出合规决策。
- The Social Game:如何理解驾驶中的隐性社会协商,例如让行、博弈、意图表达与乘客可解释性。
我们强调,前四项挑战主要集中在Egocentric Reasoning 层,而后三项则更多对应于难度更高、开放性更强的 Social-Cognitive 层。这样的划分使“自动驾驶中的推理”不再停留于抽象概念,而被转化为一组可分析、可定位、可比较的具体研究问题。
3. 系统视角:推理如何进入 AD 系统 (System-Centric Review)
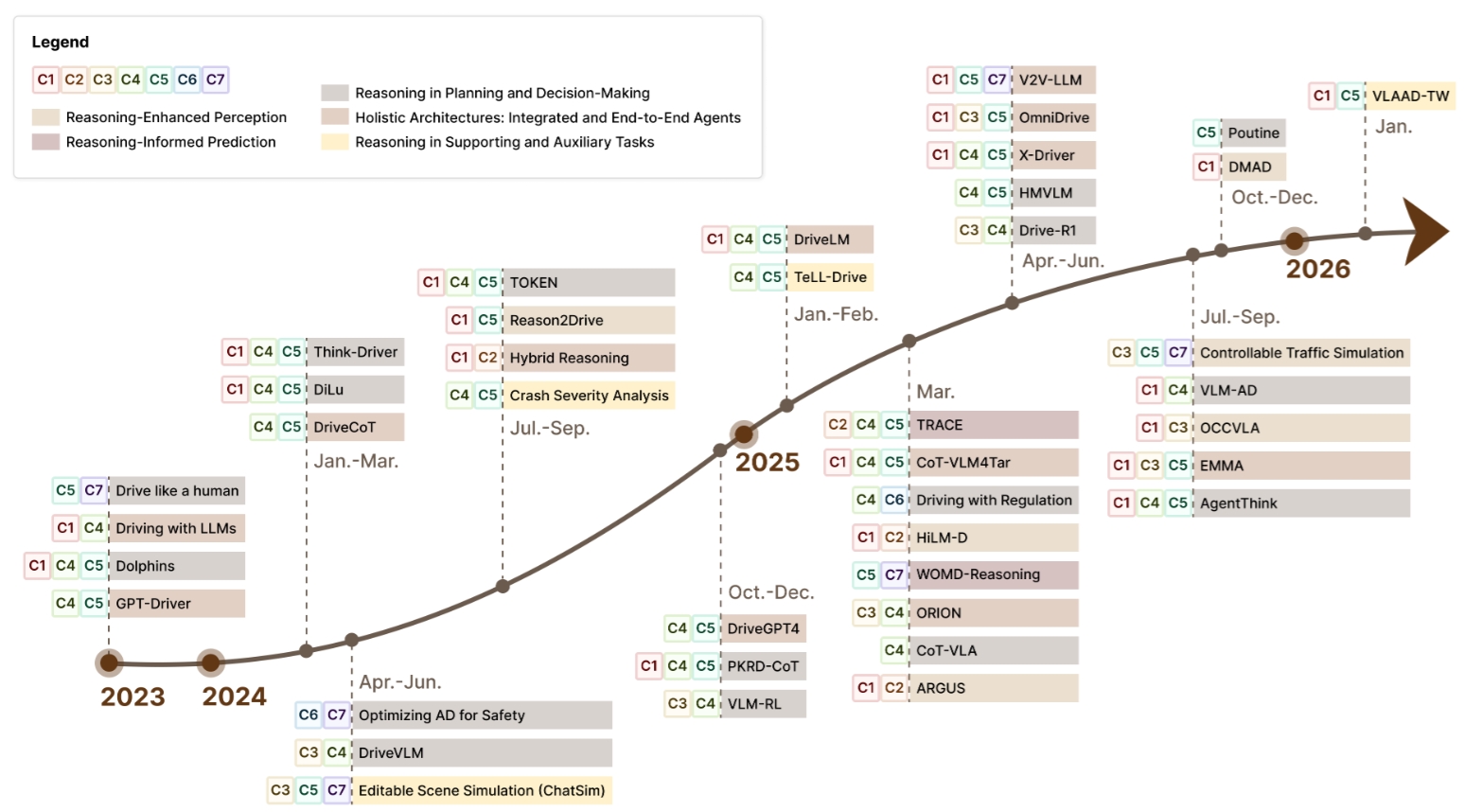
在系统视角下,我们系统梳理了推理能力进入自动驾驶方法体系的主要路径。不同于按模型类别进行静态罗列,本文按照“从局部模块增强到整体智能体构建”的演进脉络组织相关研究,从而更清晰地呈现该方向的方法学发展逻辑。
具体而言,系统综述分为五类:
- Reasoning-Enhanced Perception:用推理增强感知模块的细粒度理解与鲁棒性。
- Reasoning-Informed Prediction:用显式推理改善对其他交通参与者未来行为的预测。
- Reasoning in Planning and Decision-Making:将规则、CoT、外部知识与强化学习引入规划决策。
- Holistic Architectures:构建更整体化、更端到端、可解释的“玻璃盒”驾驶智能体。
- Reasoning in Supporting and Auxiliary Tasks:将推理用于训练、仿真、数据生成和事故分析等外围能力。
我们进一步选取了五个具有代表性的案例来对应上述方向,包括 HiLM-D、TRACE、Driving with Regulation、ORION 和 TeLL-Drive。这些工作共同表明,当前研究已经不再满足于单纯提升 backbone 或局部模块性能,而是更加关注系统是否具备显式推理链、规则建模能力、可解释性以及开放世界适应能力。
从本文的归纳来看,系统方法层面已经呈现出若干具有代表性的趋势:
- 从局部模块优化走向整体化推理架构;
- 从黑盒决策走向带有显式解释的 glass-box agents;
- 从只追求轨迹优化,转向同时关注法规约束、社会规范与推理一致性;
- 从封闭环境中的模式匹配,转向能够处理新场景、新规则和工具调用的开放世界智能体。
4. 评测视角:基准、数据集与验证范式 (Evaluation-Centric Review)
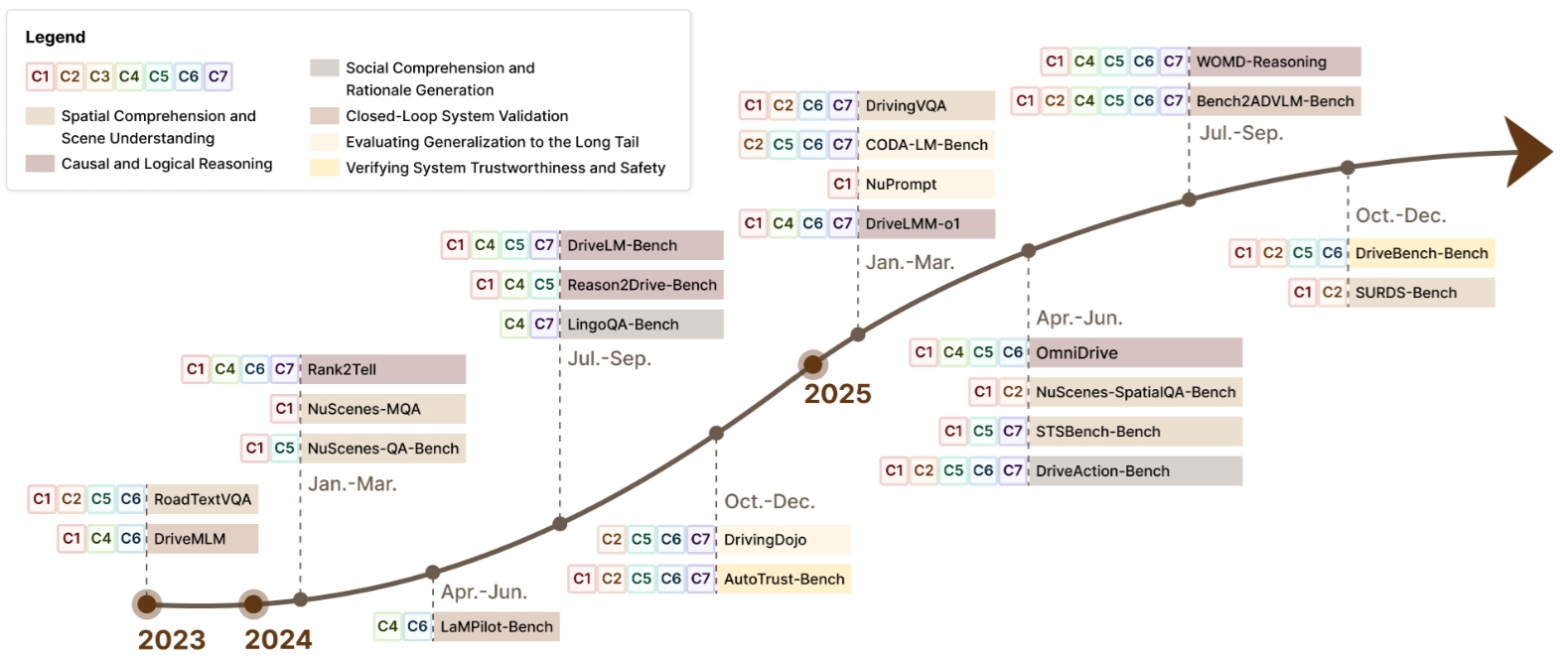
除了方法综述之外,本文的另一项重要贡献是系统梳理了自动驾驶推理评测的演化路径。我们认为,仅依赖碰撞率、轨迹误差等传统物理指标,已经不足以回答一个更关键的问题:模型为何作出某一决策,以及其推理过程是否可靠、可解释且可验证。
围绕这一问题,我们将评测体系分为三层:
- 基础认知能力评测:关注空间理解、因果推理、多步逻辑和解释生成。
- 系统级与交互式评测:关注闭环环境中推理是否真的能转化为可执行控制。
- 鲁棒性与可信性评测:关注长尾场景、安全关键场景、模型偏差与法规合规性。
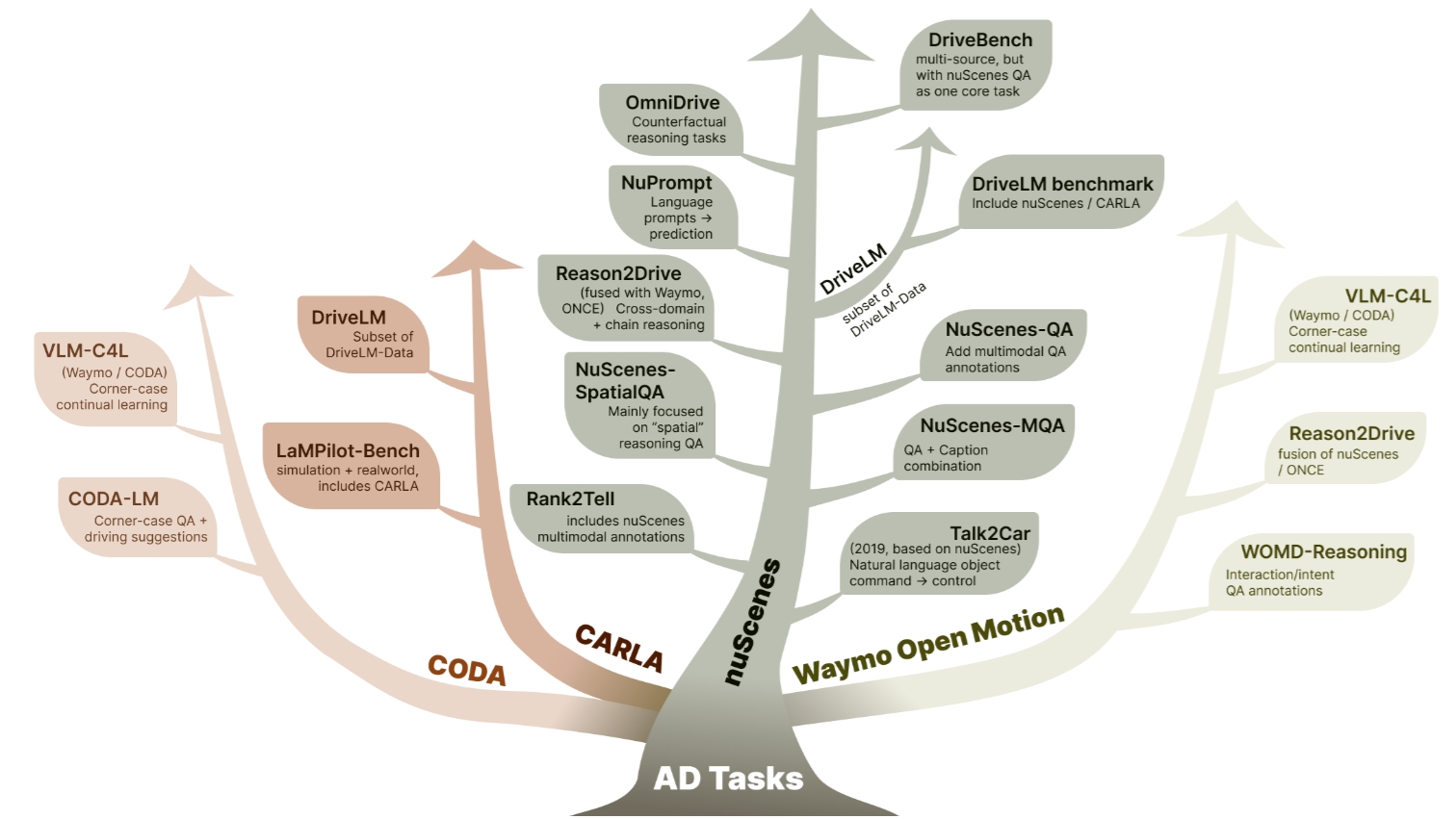
其中,我们重点讨论了若干代表性 benchmark,如 NuScenes-QA、OmniDrive、DrivingDojo 和 DriveBench,它们分别对应空间推理、整体规划、交互行为建模与安全可靠性评测等不同侧面。
5. 总结与启发 (Conclusion & Insights)
本文的贡献并不限于对“自动驾驶 + 大模型 + 推理”相关工作的汇总,更在于提出了一套具有结构性的分析框架。通过认知层级、七大挑战、系统视角与评测视角四条主线,我们刻画了一个正在形成的新研究范式:自动驾驶正逐步由“感知驱动的工程系统”演进为“以推理为核心的认知系统”。
本文最终形成的主要判断包括:
- 未来 AD 智能体将更趋向于整体化、可解释、可审计的 glass-box 设计;
- 高延迟深度推理与毫秒级安全控制之间的张力,仍然是当前最根本、也最难回避的核心矛盾;
- 下一阶段的重要方向,是打通符号推理与物理执行之间的鸿沟,发展可验证的神经符号架构、不确定性下的稳健推理机制,以及面向隐性社会协商的可扩展建模方法。
对于关注自动驾驶智能体、推理型多模态模型以及自动驾驶认知架构演进的研究者而言,本文可作为理解该领域研究脉络与关键问题的一份结构化参考。