[ICLR 2026] YuE: Scaling Open Foundation Models for Long-Form Music Generation
Published in ICLR, 2026
Arxiv地址:https://arxiv.org/abs/2503.08638
Github: https://github.com/multimodal-art-projection/YuE
Demo: https://map-yue.github.io/
1. 关键词 (Keywords)
- 长音频/完整歌曲生成 / Long-form music (full-song) generation
- 音频语言模型 / Audio Language Model (Audio LM)
- 离散音频标记化 / Discrete audio tokenization
- 双轨下一标记预测 / Track-Decoupled Next-Token Prediction (Dual-NTP)
- 结构化渐进条件化 / Structural Progressive Conditioning (CoT)
- 音频上下文学习 / Music In-Context Learning (ICL)
- 残差码本建模 / Residual codebook modeling
- 可控性评测与人类偏好 / Controllability & human preference evaluation
2. 背景与动机 (Background & Motivation)
问题定义
论文关注一个明确但长期难解的目标:在开放(可复现)范式下,实现分钟级、结构完整、具备人声且能遵循歌词与风格控制的“整首歌”生成。作者将关键挑战聚焦在两点:
- 音乐性(musicality):旋律、和声、编配与整体审美的连贯与成熟度。
- 歌曲级歌词跟随(song-level lyrics-following):长时程范围内人声内容与歌词对齐、可懂度与稳定性。
研究动机
- 当前高体验产品多为闭源系统;开放体系受限于数据治理、长上下文训练、tokenizer/decoder 能力以及可控性机制,通常难以同时达到“长时程结构 + 人声可懂 + 声学质量”。
- 自动指标与人类感知存在显著错位,导致研究社区很难用可靠的离线指标闭环改进。论文因此强调以人评为主,并系统检验自动指标与人评的相关性,试图建立更可用的评测代理信号。
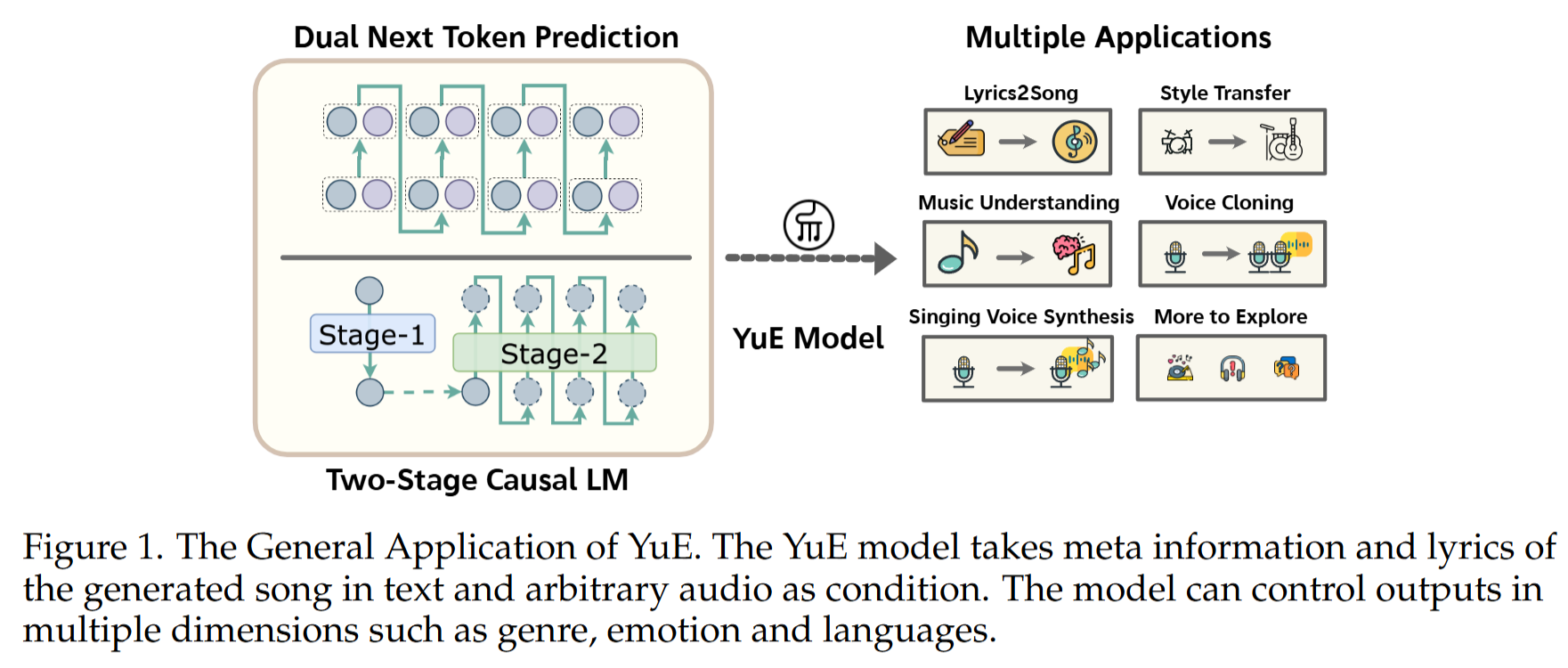
3. 核心方法 (Core Methodology)
整体架构
YuE 是一个两阶段的自回归 Transformer 系统:
- Stage-1 LM:建模文本 token 与更偏语义层的 codebook-0(在“歌词到歌曲”设置中采用双轨 token 形式)。
- Stage-2 LM:在给定 Stage-1 的 codebook-0 语义骨架后,生成其余 残差码本(1–7)补足声学细节;推理时对 codebook-0 进行 clamp,以保持语义与控制对齐。
整体思想是“先语义后细节”:Stage-1 负责结构、旋律/人声语义骨架与控制一致性;Stage-2 负责音色、质感、细节与真实感。
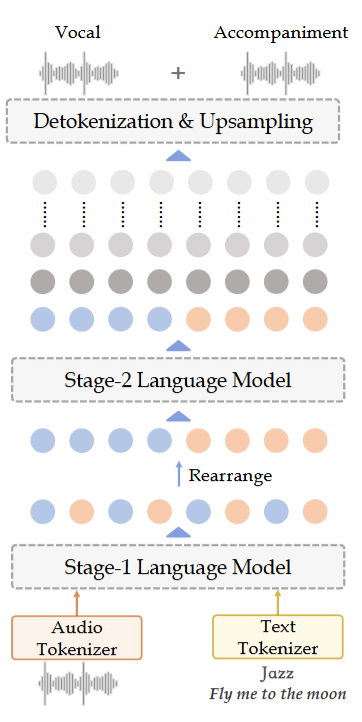
创新机制
(i) Dual-NTP:双轨下一标记预测(vocal/accompaniment 解耦) 传统“混合音频 token”迫使单一 token 同时表示人声与伴奏,伴奏容易掩蔽人声信息,使歌词可懂度下降。Dual-NTP 将每个时间步拆成两类 token:vocal token 与 accompaniment token,并以联合概率分解的方式实现自回归解码,从建模层面显式减轻“人声被伴奏淹没”的问题。
(ii) 结构化渐进条件化(CoT):段落级结构先验注入 利用自动分段与结构标签(intro/verse/chorus/bridge/outro 等),把“段落标签 + 段落歌词 + 段落音频 tokens”按段落交错组织成训练文档。生成时遵循从“宏观结构 → 局部段落”的渐进约束路径,缓解长程生成中的结构漂移与歌词跟随衰减。
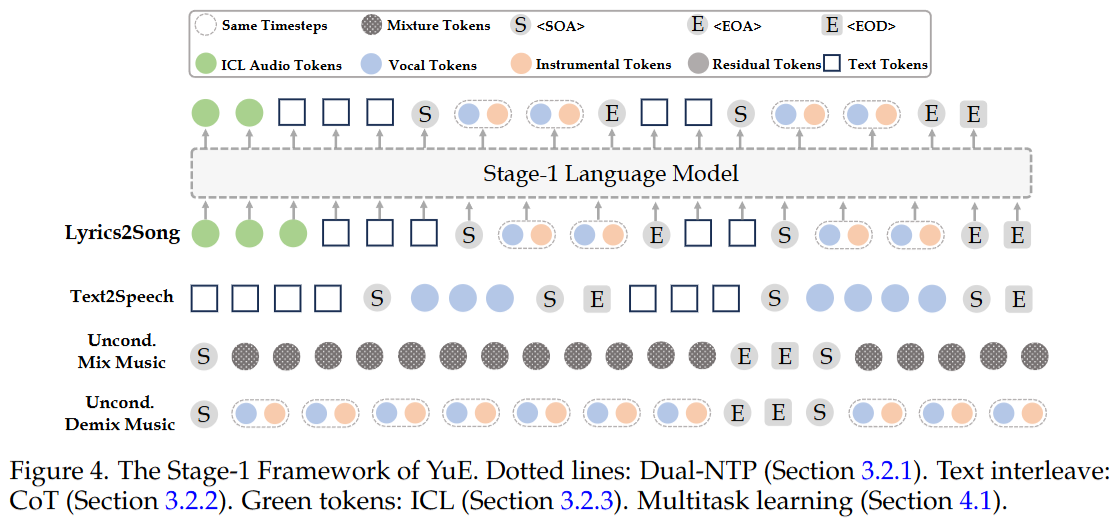
(iii) Music ICL:以参考音频作为强条件约束 在条件序列前加入 20–40 秒参考音频 token(支持单轨/双轨),并配合人声/风格相关提示,使生成更容易稳定在合理的音乐子空间,显著提高整体音乐性与可控一致性。
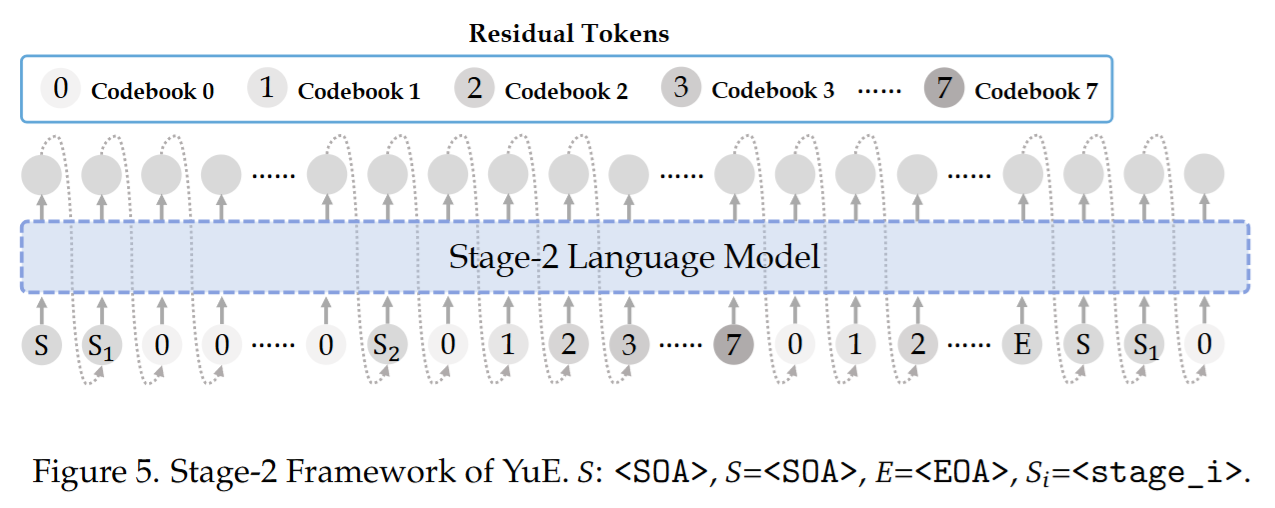
(iv) 残差码本建模:时间对齐的 factorization Stage-2 将每帧多码本 token 作为 tuple 建模,采用严格时间对齐的分解,并在序列组织上让模型先“看到全局 codebook-0 骨架”,再补全每帧的残差码本,从而提升细节补全的稳定性。
实现细节(简要)
- Tokenizer/Codec:采用多码本 RVQ 风格的离散表示;强调 codebook-0 含有丰富旋律与人声语义信息,适合作为 Stage-1 的主建模对象。
- 推理策略:Stage-1 强制解码至音频结束标记;Stage-2 强制使用 Stage-1 的 codebook-0,并限制词表范围;同时使用 CFG 等 test-time trick 提升 good-case rate。
4. 实验设计 (Experimental Design)
数据集与预处理
- 音乐数据:从互联网挖掘大规模 in-the-wild 音乐数据(小时级规模为数十万量级),其中一部分具有歌词配对信息。
- 语音/TTS 数据:引入大规模公开语音数据集,用于提升人声相关建模能力与稳健性。
- 训练策略:多阶段训练包含 warmup、上下文扩展、退火与控制注入;退火阶段引入质量筛选得到高质量子集;控制信号(CoT/ICL)在总训练 compute 中占比相对较低,但用于显著提升可控性与歌词跟随。

对比模型 (Baselines)
选取多个代表性闭源系统(如 Suno、Udio 等)作为黑盒 baseline,并明确评测时间点,强调闭源系统随版本更新而变化这一不可控因素。
评估指标 (Metrics)
- 人评(核心):采用 A/B test 的偏好比较;评测者包含领域专家与受训音乐人;测试提示包含 genre/instrument/emotion/lyrics/tempo,并提供 chorus reference 音频。
- 自动指标(辅助):包含分布距离与质量指标(如 FAD、KL)、以及音频-文本对齐指标(如 CLAP/CLaMP3 等),并额外分析其与人评的相关性。
- 任务化指标:如 vocal range(人声灵活度/表现力 proxy)与生成时长分布(长程结构能力)。
- 表示能力评测:在音乐理解/分类基准上评估表示质量与泛化能力。
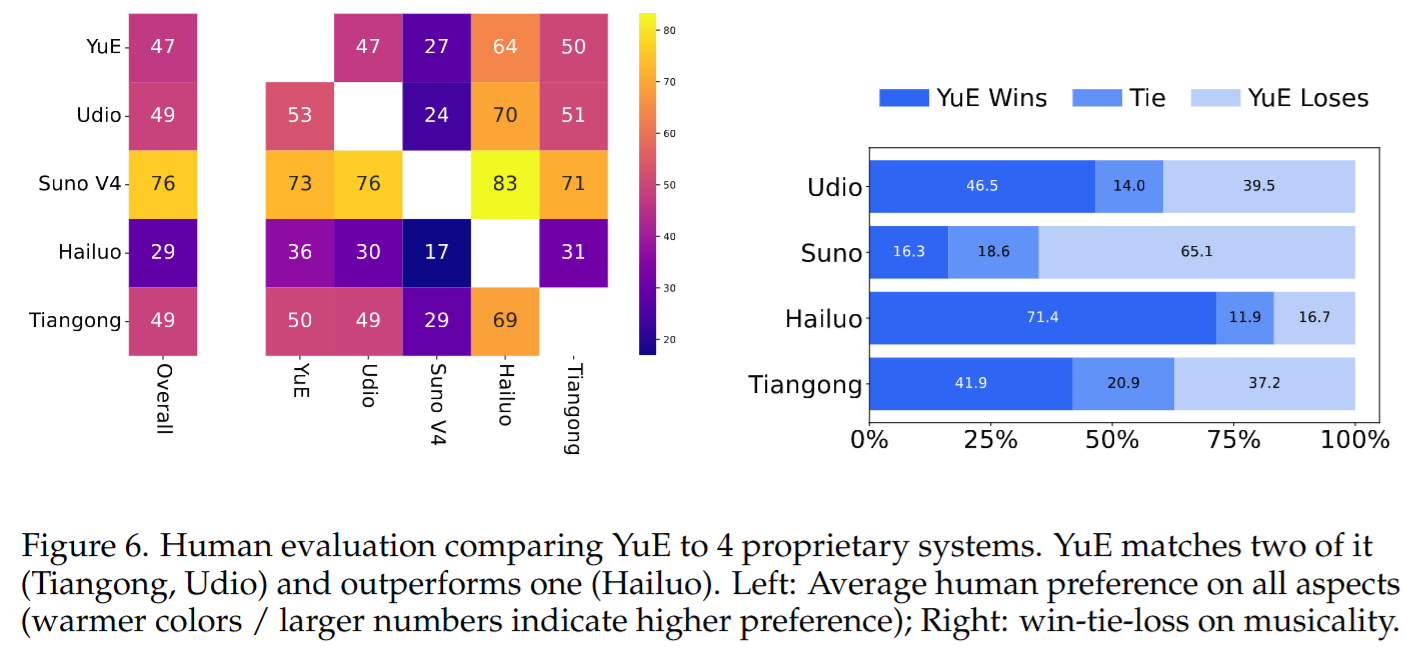
5. 实验结果与分析 (Results & Analysis)
主要结果
- 自动指标层面:YuE 在若干分布/对齐指标上表现较强,但不同对齐指标之间可能出现显著分歧,提示自动指标与人类感知不一致;因此自动指标需要谨慎解释。
- 人评层面:YuE 相比部分闭源系统有显著提升,与若干闭源系统大体相当,但仍落后于最强闭源系统。优势更集中在歌曲结构与编配,短板集中在人声与伴奏的声学质量,主要来自 tokenization/decoder 的上限。
- 长时长与结构能力:YuE 的生成时长分布更宽、整体更长,显示长程结构建模能力更强;在人声表现力 proxy 上也接近顶级系统。

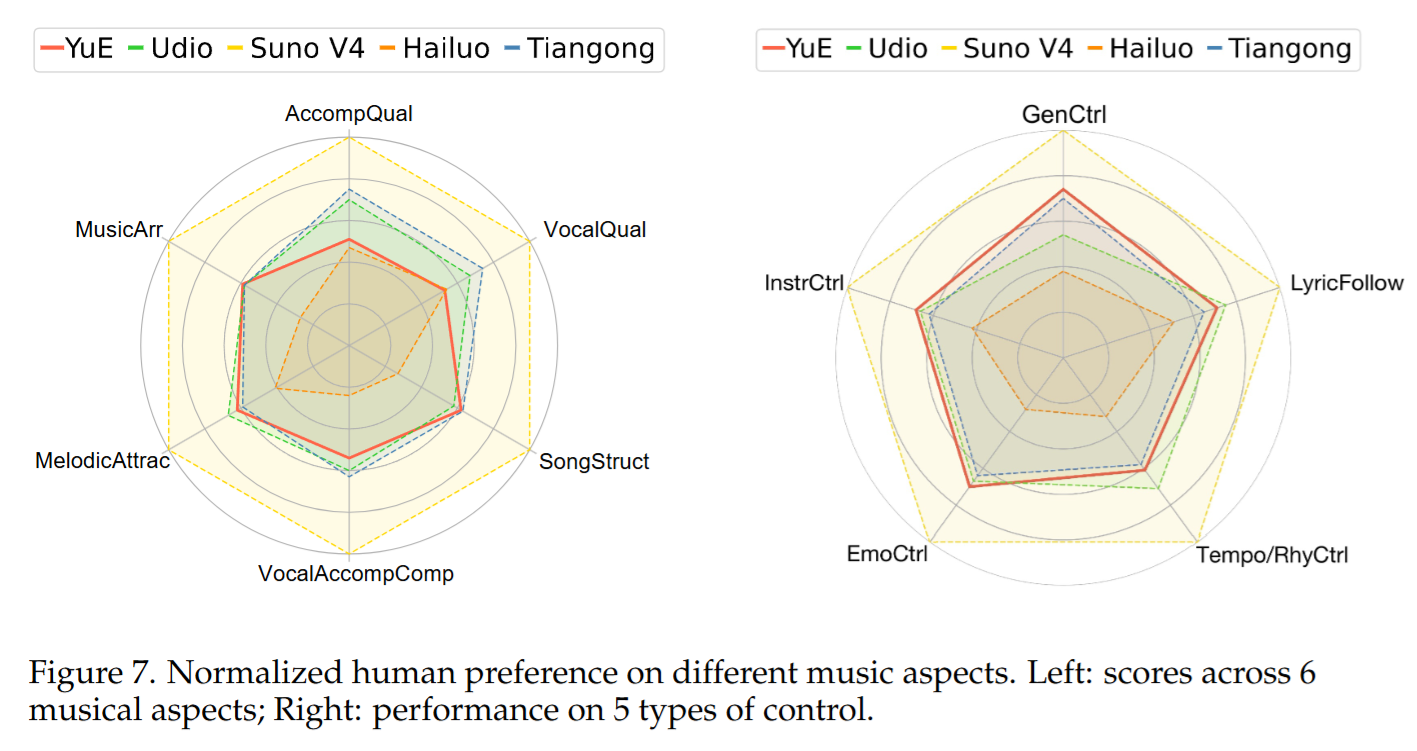
消融研究 (Ablation Study)
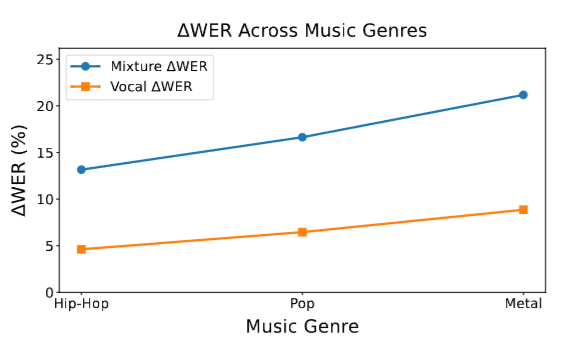
- Dual-NTP 的有效性:通过伴奏掩蔽导致歌词信息损失的分析(例如在低人声占比时更明显),以及在同等算力/数据下训练 loss 的改善,证明双轨建模更利于捕捉人声信息并提升歌词可懂度。
- CoT 的贡献:在多时长区间对比不同训练策略,CoT 在歌词跟随(如 WER)上显著优于替代方案;且该能力对规模高度敏感,模型扩展带来显著跃迁。
- Test-time tricks(ICL/CFG):ICL 的人评胜率显著高于纯 CoT;ICL 与 CFG 组合效果最好。解释为 ICL 将生成限制在更合理的音乐子空间,CFG 放大条件约束,从而提高好样本比例。
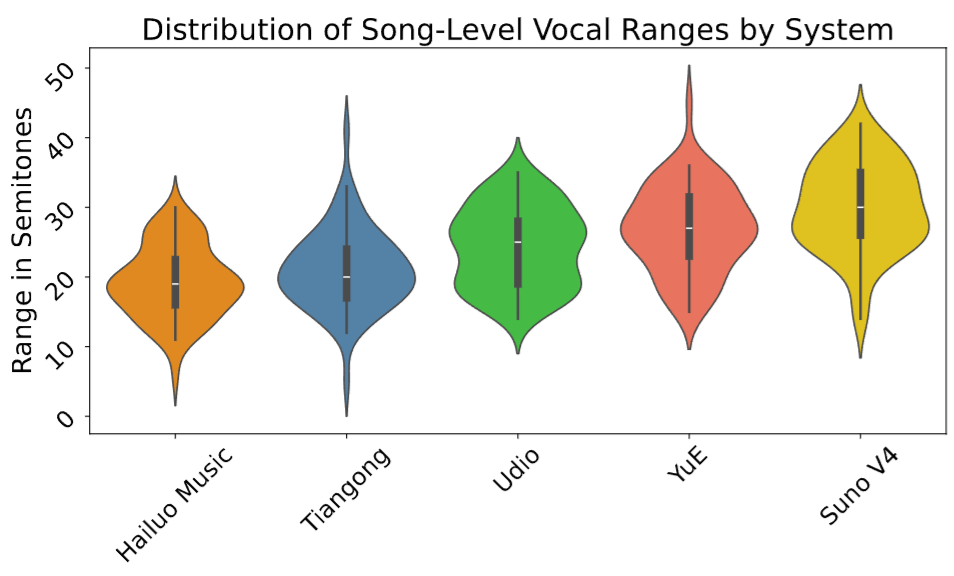
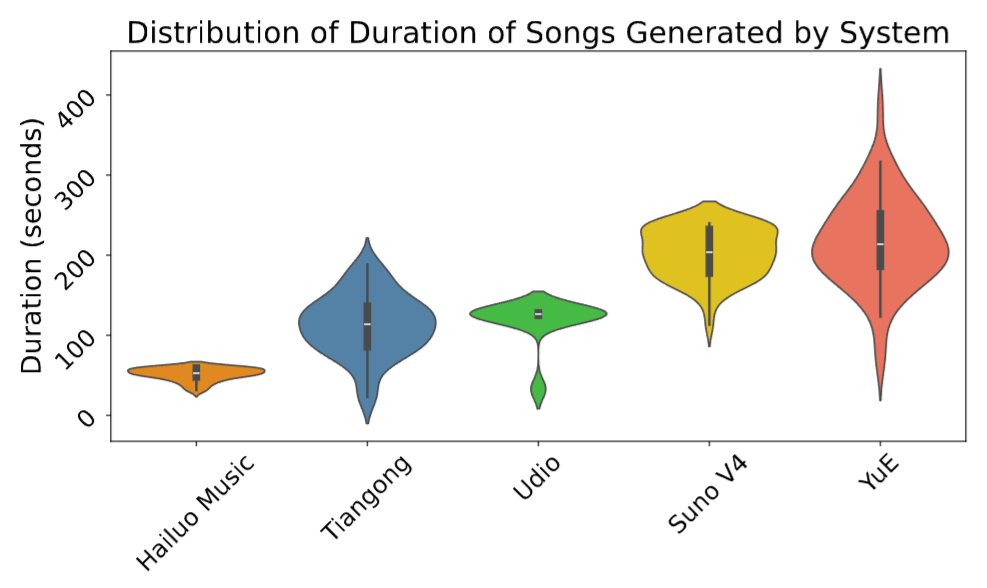
案例分析 (Case Study)
论文展示了多类“涌现”与可控能力案例:多种演唱技巧、即兴元素、多声部和声、跨风格融合等;也报告 style transfer、code switching、一定程度 voice cloning 等现象级能力。这些案例与“Dual-NTP + ICL 强条件”路线一致。
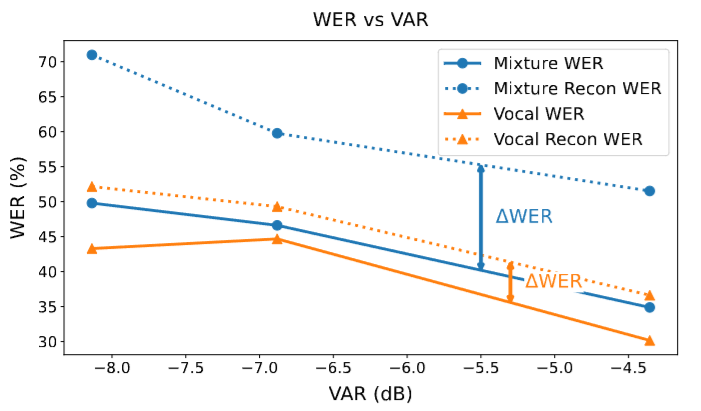
6. 总结与贡献 (Conclusion & Contribution)
主要结论
通过“tokenizer/codec 选择 + Dual-NTP 解耦建模 + 段落级结构条件化(CoT)+ ICL/CFG 推理技巧 + 大规模多阶段训练”,开放模型可以在长音频整首歌生成上达到高水准体验,并在结构与编配方面具备明显竞争力;但声学质量(尤其人声与伴奏质感)仍是与最强闭源系统的主要差距来源。
核心贡献
- Dual-NTP:显式解耦人声/伴奏建模,提升歌词可懂度与建模效率。
- 结构化渐进条件化(CoT):以段落结构先验组织样本,改善长程歌词跟随与结构稳定性。
- 系统化 scaling 路线:从数据、训练阶段、控制注入到推理技巧给出可复现范式,并用大规模人评校准结论。
- 记忆/复制风险分析:针对 ICL 可能放大记忆风险给出检索式相似度分析,尝试论证未出现大规模复制(但开放部署仍需更强策略)。