🚩 [AAAI 2026 (Oral)] O-DisCo-Edit: Object Distortion Control for Unified Realistic Video Editing
Published in AAAI, 2026
关键词 (Keywords):
- 视频编辑 / Video Editing
- 扩散模型 / Diffusion Models
- 统一控制信号 / Unified Control Signal
- 多任务学习 / Multi-Task Learning
- 目标失真控制 / Object Distortion Control
项目主页: https://cyqii.github.io/O-DisCo-Edit.github.io/
Arxiv地址:https://arxiv.org/abs/2509.01596
Accepted by AAAI 2026 (Oral)

1. 背景与动机 (Background & Motivation)
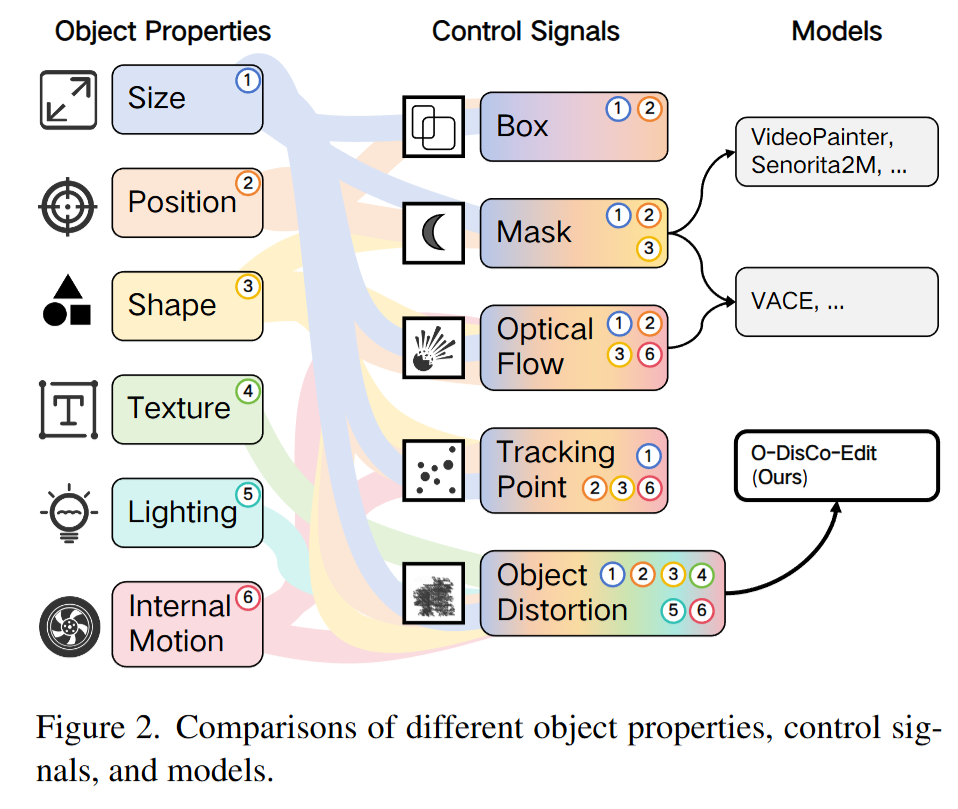
- 问题定义: 论文旨在解决现有视频编辑方法中的一个核心挑战:如何创建一个统一、高效且灵活的框架,以精确控制多样化的视频编辑任务(如对象移除、替换、风格迁移等),同时避免为不同任务设计复杂的、独立的控制信号和训练流程。
- 研究动机: 当前的视频编辑技术存在两大瓶颈:
- 单任务模型控制力有限: 依赖边界框、掩码等简单信号的模型,难以实现对纹理、内部运动等复杂属性的精细控制。而依赖光流、跟踪点等复杂信号的模型又受限于数据稀缺和提取困难的问题。
- 多任务模型训练成本高昂: 为了兼容多种任务,现有统一模型通常需要设计复杂的训练流程、任务特定的模块以及庞大的可训练参数,导致训练资源消耗巨大。此外,这些模型在推理时通常一次只能处理一种控制信号,灵活性不足。 因此,研究界迫切需要一种既能实现多任务、精细化控制,又能显著降低训练成本的新范式,这便是 O-DisCo-Edit 诞生的驱动力。
2. 核心方法 (Core Methodology)
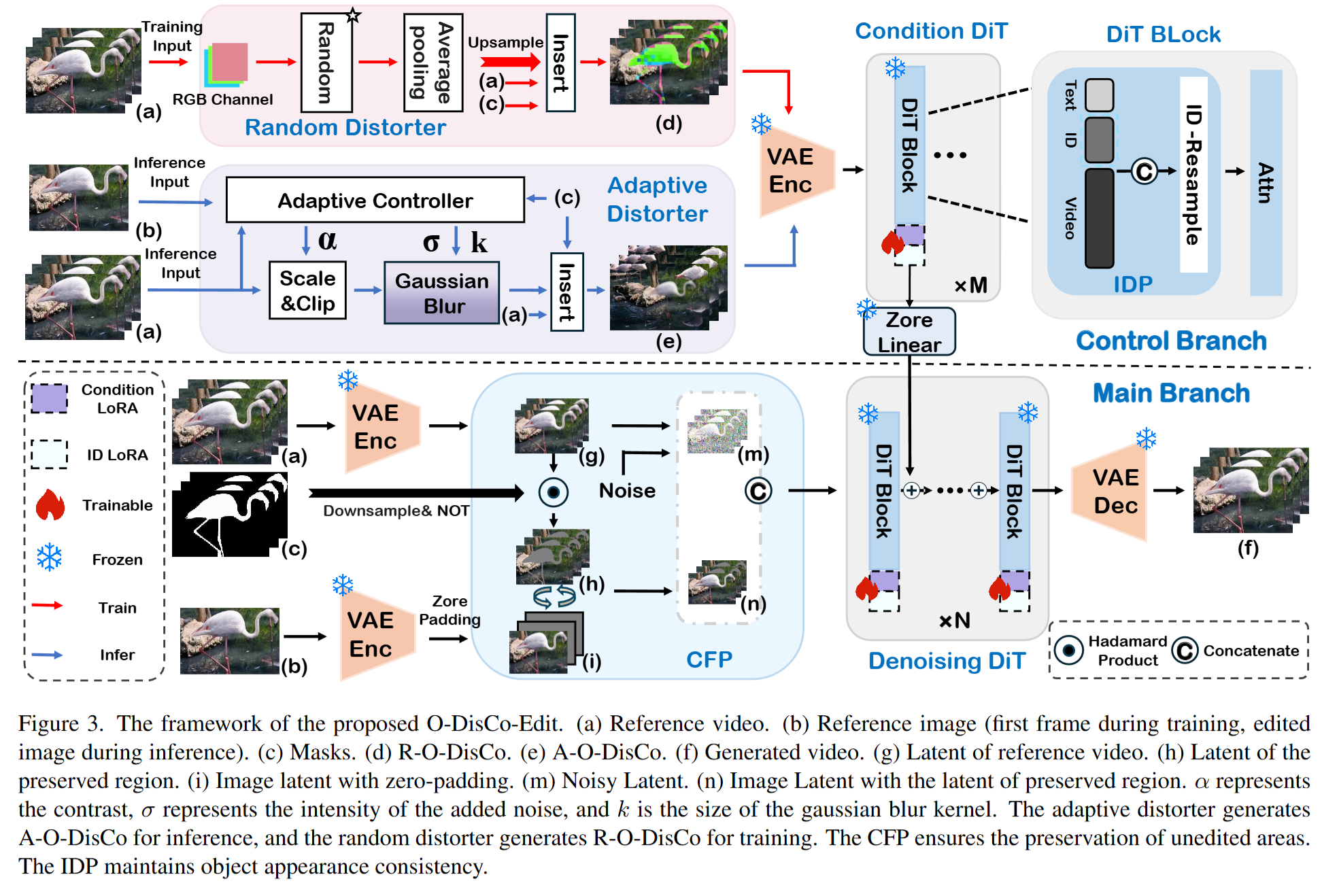
- 整体架构: O-DisCo-Edit 是一个基于首帧引导的视频编辑框架。其核心由三个关键模块构成:
- 目标失真控制器 (Object Distorter): 论文的最大创新,用于生成核心的控制信号 O-DisCo。它在训练和推理阶段使用两种不同策略。
- “复制形式”保留模块 (CFP Module): 负责将视频中的未编辑区域信息直接整合到网络主干中,以高保真度地保留背景内容。
- 身份保留模块 (IDP Module): 旨在提取编辑对象的身份(ID)信息,确保其在复杂运动或遮挡下仍能保持外观一致性。
- 创新机制: 本文最关键的创新是提出了目标失真控制 (Object Distortion Control, O-DisCo) 这一全新的统一控制信号。其核心思想是:所有编辑任务的控制信号本质上都可以被看作是对参考视频的一种“失真”。O-DisCo 通过对编辑区域注入可控的噪声,将多样化的编辑线索统一到单一的表示形式中。这种设计带来了两大优势:
- 训练简化: 训练时使用随机失真 (R-O-DisCo),通过对颜色、结构进行随机破坏,迫使模型学习从首帧图像生成内容,而非简单复制,极大地简化了数据构建和模型设计,节省了训练资源。
- 推理灵活: 推理时使用自适应失真 (A-O-DisCo),通过动态调整噪声的强度和范围,模型可以灵活地执行从粗粒度到细粒度的各种编辑任务。
- 实现细节:
- 训练阶段 (R-O-DisCo): 对参考视频的编辑区域进行随机的颜色通道运算和马赛克化(下采样+上采样),生成失真信号。
- 推理阶段 (A-O-DisCo): 通过一个自适应控制器,根据参考图像与视频首帧的边缘相似度等信息,计算出合适的对比度、噪声强度和模糊核大小,从而生成任务特定的失真信号。
- CFP 模块: 将未编辑区域的视频隐层特征与参考图像的隐层特征拼接,作为去噪网络的主要输入之一,实现了类似“首帧复制”的高效保留效果。
3. 实验设计 (Experimental Design)
- 数据集与预处理:
- 训练数据: 使用了 Senorita-2M 数据集中的约18万个视频-掩码对。所有视频被处理为 720x480 分辨率、49帧的规格。
- 评估数据: 由于缺乏公开的、基于首帧编辑的基准,作者们从 DIVAS 和 VPData 中构建了一个新的、包含8个任务、134个视频样本的高质量基准。此外,在对象移除任务上使用了 OmnimatteRF 基准。
- 对比模型 (Baselines):
- 多任务模型: 选取了当时最先进的(SOTA)统一视频编辑模型,包括 VACE、VideoPainter 和 Senorita。
- 单任务模型: 在对象移除任务上,额外引入了专门的 SOTA 模型,如 DiffuEraser, MiniMax-Remover 和 Propainter,以进行更严格的比较。 模型的选择覆盖了多任务和专有任务的 SOTA,非常全面且具有说服力。
- 评估指标 (Metrics): 实验采用了非常全面的量化指标和人工评估:
- 量化指标: 覆盖了保留度 (PSNR_P, SSIM_P)、对齐度 (CLIP-T, CLIP-I_E)、视频质量 (FVD, ArtFID, TC) 和任务特定指标 (PSNR_E, SSIM_E 用于移除;CFSD 用于风格迁移)。
- 人工评估: 采用平均意见得分 (MOS),从编辑完整性 (EC) 和视频质量 (VQ) 两个维度进行打分。
4. 实验结果与分析 (Results & Analysis)
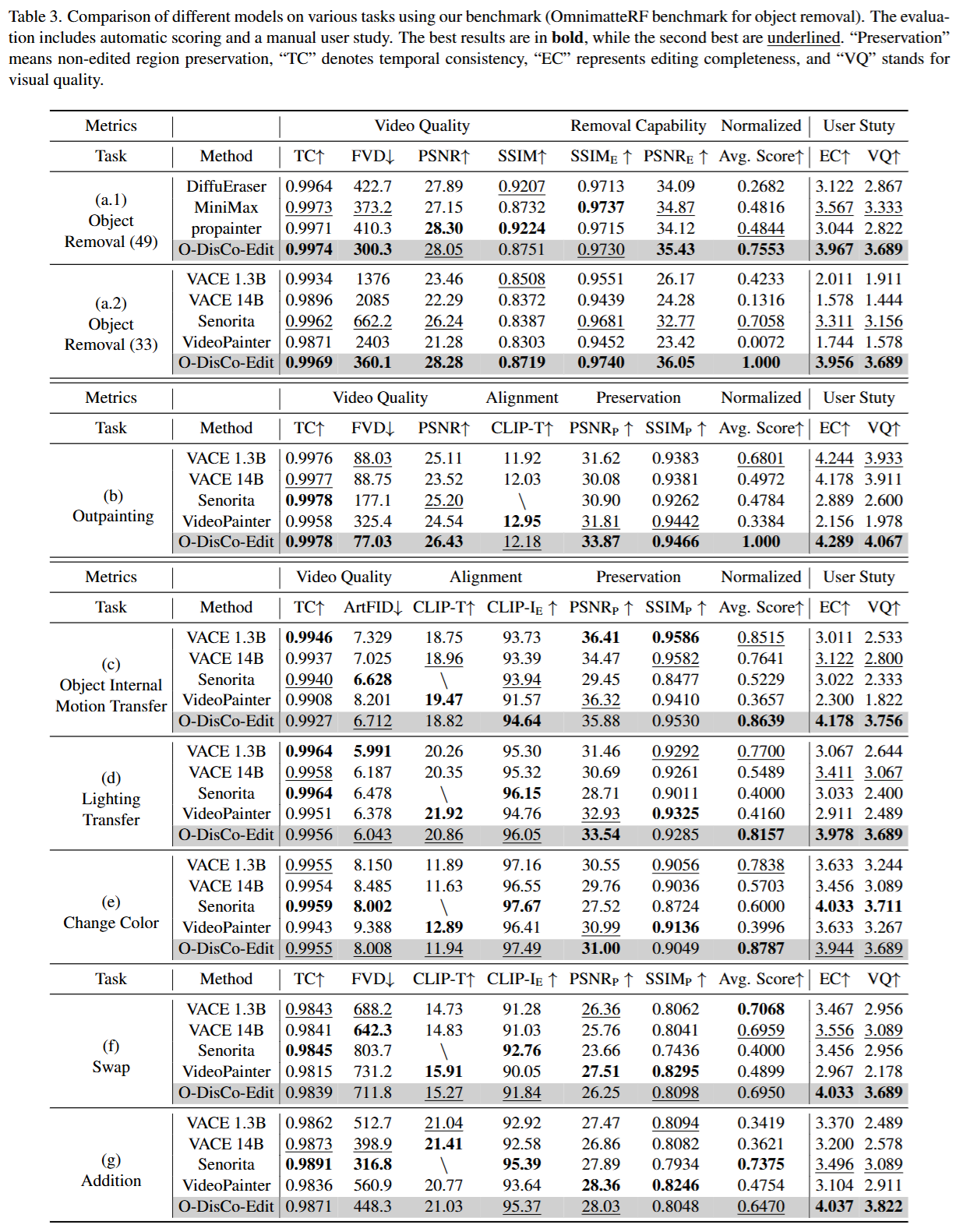
- 主要结果: O-DisCo-Edit 在几乎所有8个任务中都取得了SOTA或极具竞争力的性能。
- 在对象移除任务中,其归一化平均分达到1.000,大幅领先所有对比模型。
- 在外绘制 (Outpainting) 任务中,同样在所有指标上刷新了SOTA记录,生成的视频在视觉上更自然、无缝合痕迹。
- 在内部运动迁移和光影迁移等高难度任务中,其他模型普遍失败,而 O-DisCo-Edit 能够成功地捕捉和迁移这些精细的动态变化。
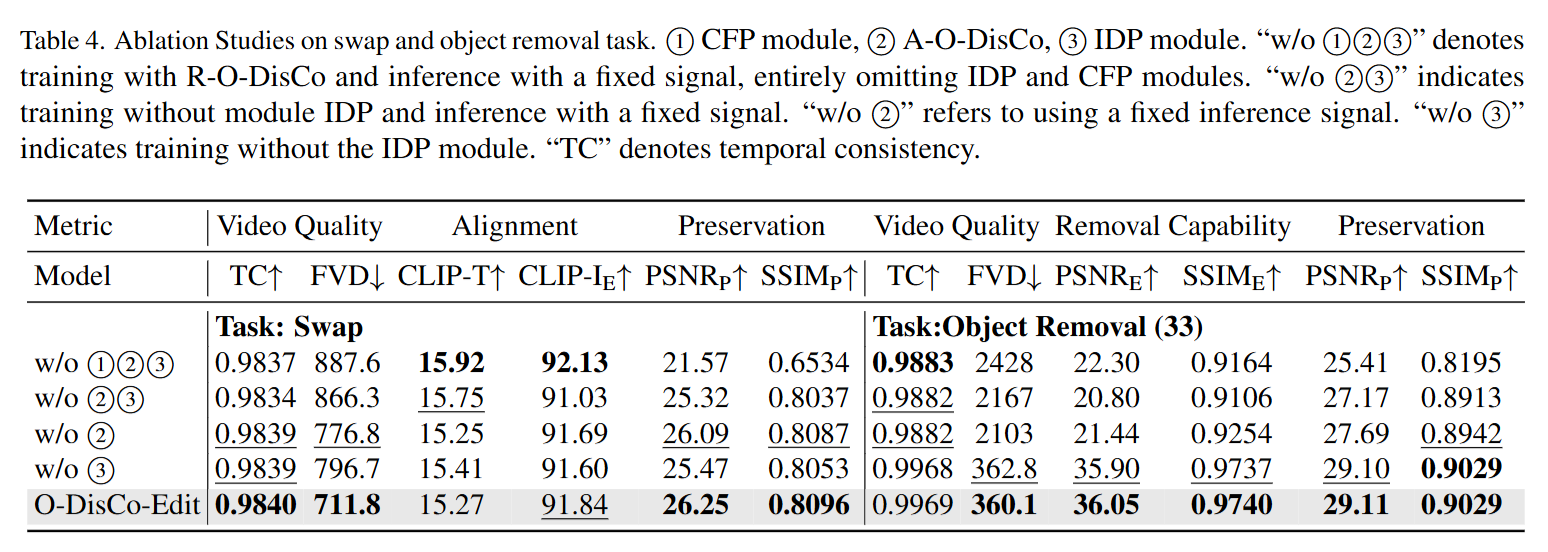
- 消融研究 (Ablation Study): 消融实验清晰地验证了各模块的贡献:
- 移除 CFP 模块: 导致未编辑区域的保留度指标大幅下降,证明了 CFP 在背景保留上的有效性。
- 移除 A-O-DisCo: 导致视频质量和任务表现显著恶化,验证了自适应控制信号的必要性。
- 移除 IDP 模块: 导致编辑区域的外观一致性下降,证明了 IDP 模块对维持对象身份的重要性。 实验结论是,三个模块的组合能够达到最佳性能。
- 案例分析 (Case Study): 论文中的图例提供了丰富的定性对比。例如,在“北极熊替换”任务中,其他模型出现了“三只耳朵”等解剖学错误或运动不连贯的问题,而 O-DisCo-Edit 的结果在形态和动态上都更为合理。这些案例直观地展示了其在生成质量和细节保真度上的优势。

5. 总结与贡献 (Conclusion & Contribution)
- 总结: 论文成功地提出了 O-DisCo-Edit,一个创新的统一视频编辑框架。其核心贡献 O-DisCo 信号将复杂的、多样的编辑任务统一为一种简单的、基于噪声的表示,在大幅降低训练成本的同时,实现了跨越8个不同任务的SOTA性能,并能稳健地保留未编辑区域。
- 核心贡献:
- 理论贡献: 提出了 O-DisCo 这一全新的统一控制信号范式,为视频编辑领域提供了一个“化繁为简”的新视角,证明了单一控制信号可以兼具通用性、精确性和高效性。
- 技术贡献: 设计了 CFP 和 IDP 等有效模块,分别解决了统一框架中背景保留和身份一致性的关键技术难题。
- 实践贡献: 实现了在多个主流视频编辑任务上的新SOTA,并构建了一个高质量的评估基准,为后续研究提供了有力的工具和参考。