💭⭐ SIN-Bench: Tracing Native Evidence Chains in Long-Context Multimodal Scientific Interleaved Literature
Published in Arxiv, 2026
Arxiv地址:https://arxiv.org/abs/2601.10108
1. 关键词 (Keywords)
- 证据链 / Evidence Chain
- 长上下文多模态理解 / Long-Context Multimodal Understanding
- 科学文献交错表示 / Scientific Interleaved Representation
- 大海捕鱼范式 / Fish-in-the-Ocean (FITO) Paradigm
- 无证据不评分 / No Evidence, No Score
- 基准构建流水线 / Benchmark Construction Pipeline
- 证据匹配-相关性-逻辑 / Matching–Relevance–Logic (MRL)
2. 背景与动机 (Background & Motivation)
问题定义
论文聚焦于一个被长期低估的评测难题:当多模态大模型面对超长、符号密集且图文强耦合的科学论文时,“答案正确”并不等价于“理解成立”。传统评测往往只衡量最终答案或用合成式 Needle-In-A-Haystack(干草堆找针)任务来测试长上下文能力,但这类设定难以验证模型是否真正完成了从原生文献中定位证据、组织多跳证据链、并在证据约束下推导结论的全过程。
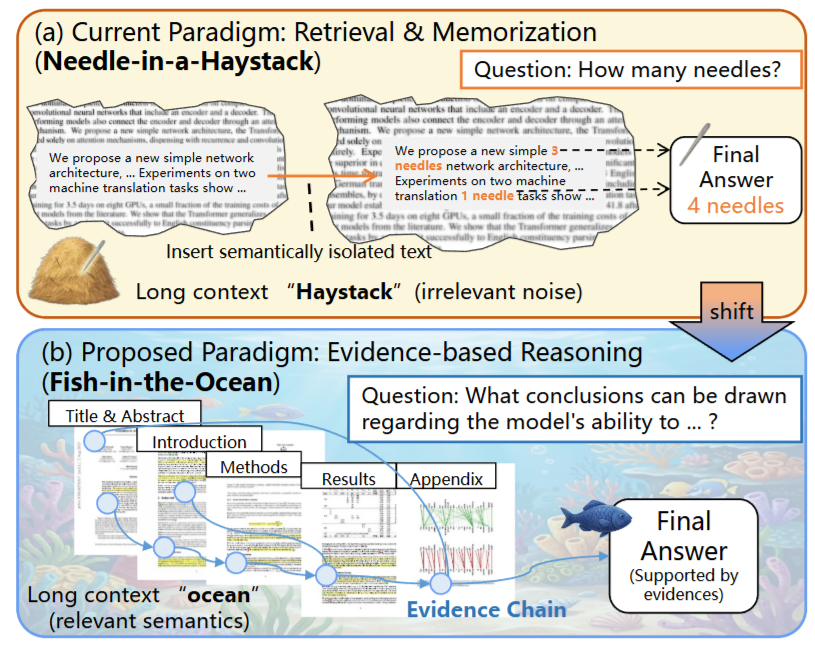
研究动机
科学文献的真实阅读理解具有三个关键属性:
- 原生性 (Nativeness):关键信息天然嵌在论文叙事结构中,而非人为注入的“针”。
- 互联性 (Interconnectivity):证据常跨图表、公式、段落、章节互相指涉。
- 长程依赖 (Long-range Dependency):有效推理依赖跨较远位置的信息整合与一致性维护。
| 因此,需要一种更贴近真实阅读流程的评测范式,把评测目标从单纯的 (P(A | D,Q)) 推进为同时要求答案与证据链的 (P(A,E | D,Q)),并通过“无证据不评分”抑制“答对但无依据”的伪正确现象。 |
3. 核心方法 (Core Methodology)
整体架构:FITO → SIN-Data → SIN-Bench
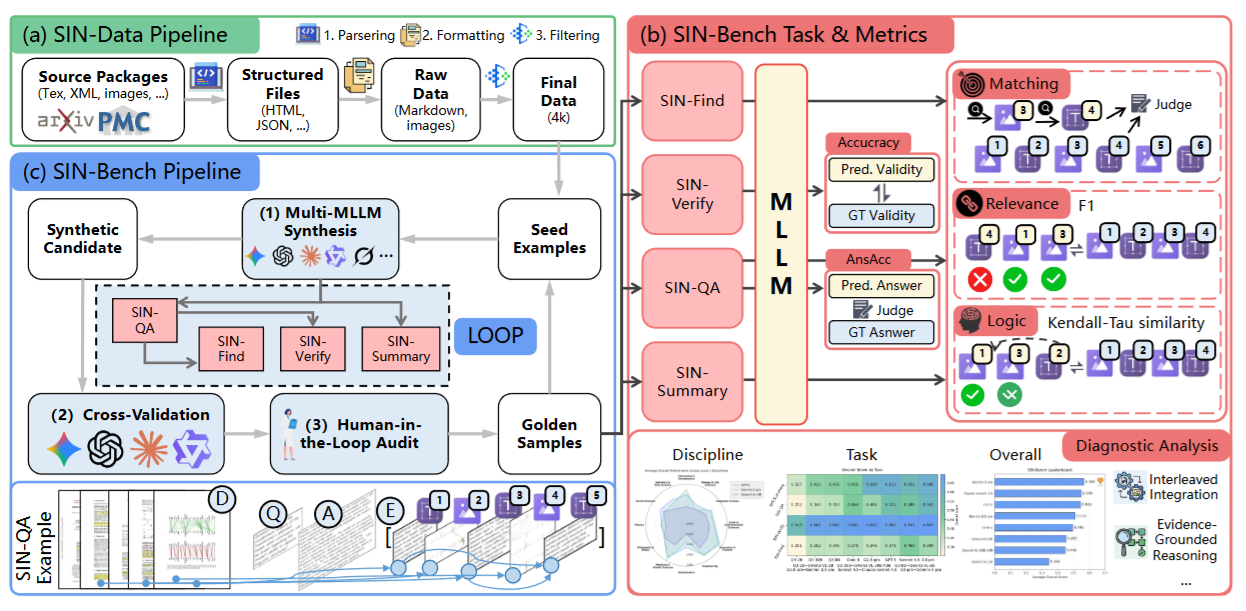
FITO 范式(Fish-in-the-Ocean) 用“海洋中的鱼”隐喻真实长文档,强调模型必须从原生文献中捕捉并串联“高价值互联知识单元”,形成可核验证据链,再在证据约束下作答: [ P(A,E|D,Q)=P(E|D,Q)\cdot P(A|E,D,Q) ]
SIN-Data(Scientific INterleaved 数据基础设施) 将 arXiv(LaTeX)与 PMC(XML/JATS)源包解析、线性化为“语义优先”的交错序列,目标是保留叙事逻辑与证据邻接关系,而不是复刻 PDF 的视觉版式。
SIN-Bench(证据链驱动基准) 在 SIN-Data 上设计分层任务、统一证据接口,以及配套的证据驱动评测指标体系,并提供可扩展的样本构建流水线与黄金样本集。
创新机制:关键技术点
引文驱动注入 (Citation-Driven Injection Strategy) 给每个视觉元素分配唯一占位符(如 ⟨x_k⟩),并将其插入到“首次被正文引用”的位置之前,从而使图表证据与文本叙事自然对齐,显式保留证据链的时间/逻辑顺序。
统一证据链接口 (Interleaved Evidence Chain Interface) 证据链 (E) 被表示为交错锚点序列:视觉锚点与文本跨度交替出现,最小证据单元由(视觉锚点,文本跨度)共同构成,便于评测“是否找到了正确证据、是否覆盖充分、顺序是否一致”。
四阶段层级任务(贴近真实阅读流程)
- SIN-Find(发现):给定文档与问题,输出证据链 (E)。
- SIN-Verify(核验):给定文档、问题、答案与证据链,判断证据是否足以支持答案,并通过系统扰动构造负例测试“证据辨别能力”。
- SIN-QA(证据问答):联合生成答案 (A) 与证据链 (E),强调解释必须可回溯到锚点以区分参数化幻觉。
- SIN-Summary(证据锚定综合):生成由多条可核验 claim 组成的总结,每条 claim 必须给出证据锚点与支持片段。
评测哲学:No Evidence, No Score 对需要证据链的任务(Find/QA/Summary),先评价证据质量,再评价答案/综合结果,避免“答案偶然正确”掩盖过程缺陷。
实现细节:从数据到基准的闭环
- SIN-Data 构建:从 50k 源包出发,经解析、交错注入、质量过滤后得到 4,000 篇高质量科学文献,覆盖广泛学科,并保留极长上下文范围(32k–1M tokens)。
- SIN-Bench 构建:多模型协同合成(以 QA/Summary 为枢纽反向派生 Find;Verify 通过扰动构造近似负例)、三模型交叉验证(Q/A/E 多维一致性打分并要求多数票且均达标)、人工审计校准锚点与支持关系;最终从约 3,200 候选收敛到 490 条 golden samples。
4. 实验设计 (Experimental Design)
对比模型 (Baselines)
论文评测了 8 个“广泛使用”的多模态大模型,涵盖闭源前沿与开源不同规模/架构(包括 dense 与 MoE):
- Gemini-3-pro、Gemini-2.5-pro、GPT-5、Grok-4、Claude-sonnet-4.5
- Qwen3-VL(2B/8B/30B-A3B)
这组基线在“能力上限、架构多样性、开闭源对照”上具有较好的代表性。
评估指标 (Metrics)
论文使用一组以证据为核心的指标体系(MRL),并与答案/判别指标结合:
- Matching(匹配):视觉锚点命中 + 文本跨度语义一致性(0–3 评分并归一化)。
- Relevance(相关性):以阈值将证据单元二值化,计算 Precision / Recall / F1。
- Logic(逻辑顺序):对命中锚点的相对顺序用 Kendall–Tau 相关系数衡量,并映射到 [0,1]。
- 答案正确性(QA):语义正确性打分(0–3,归一化为 AnsAcc)。
- 验证准确率(Verify):Accuracy。
- Overall:对该任务包含的指标取平均,确保“证据差”会显著拖累总体分。
整体上,这套指标能够把“伪正确”具体分解为:找错证据、证据不充分、顺序不一致、或答案本身不成立。但其代价是引入了评测器偏差与单参考证据链的覆盖风险(见第 7 节)。
5. 实验结果与分析 (Results & Analysis)
主要结果(量化对比)
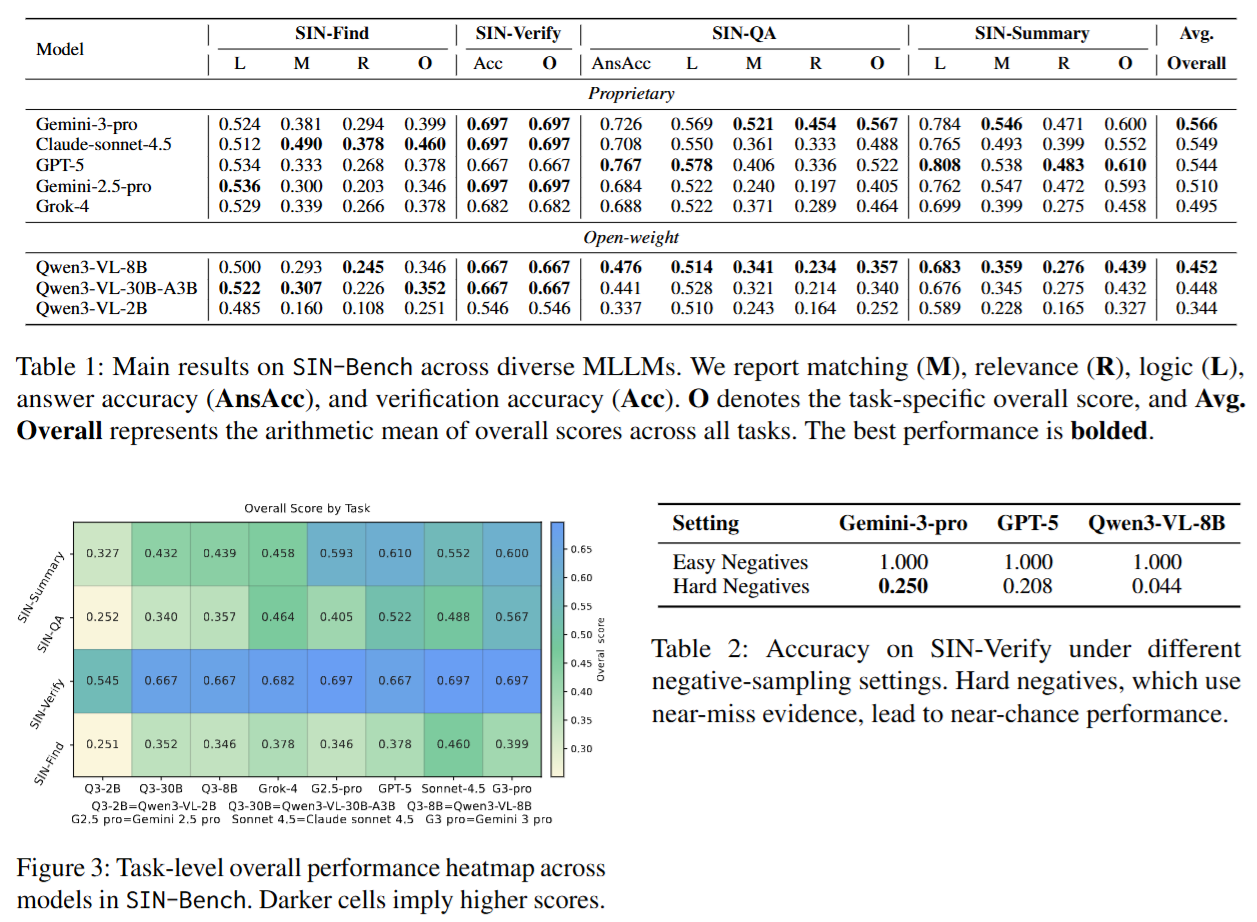
- 跨任务平均总体分(overall):Gemini-3-pro 最高,为 0.566;GPT-5 为 0.544;Claude-sonnet-4.5 为 0.549。
- 答案正确性与证据对齐的张力:在 SIN-QA 上,GPT-5 的 AnsAcc 达到 0.767(最高),但其 SIN-QA overall 为 0.522,低于 Gemini-3-pro 的 0.567。这表明“答对”并不必然意味着“证据链对齐得更好”。
- 开源模型差距明显:Qwen3-VL-8B / 30B-A3B / 2B 的平均 overall 分别为 0.452 / 0.448 / 0.344。
这组结果共同指向一个核心结论:当前最强模型的优势并不只体现在“会答”,而更体现在“更可能在证据链上少犯错”;但即便顶级模型也远未解决“证据充分性与排他性”的困难。
消融研究 (Ablation Study)
交错输入 (Interleaved Input) 的决定性作用 将文档改为“非交错”(如把图后置、文本集中)会显著降低性能。以 Gemini-3-pro 为例:
- SIN-QA overall 从 0.465 → 0.567(+0.102)
- SIN-Summary overall 从 0.471 → 0.600(+0.129) 这验证了“保持原生阅读顺序”不是格式细节,而是决定证据定位与跨模态邻接对齐的关键约束。
要求输出证据链会反向提升 QA 性能(Evidence-chain effect) 对 Gemini-3-pro 强制生成证据链,SIN-QA 表现从 0.694 → 0.726。这表明“先找证据再作答”本身是有效的推理约束,可降低无依据猜测。
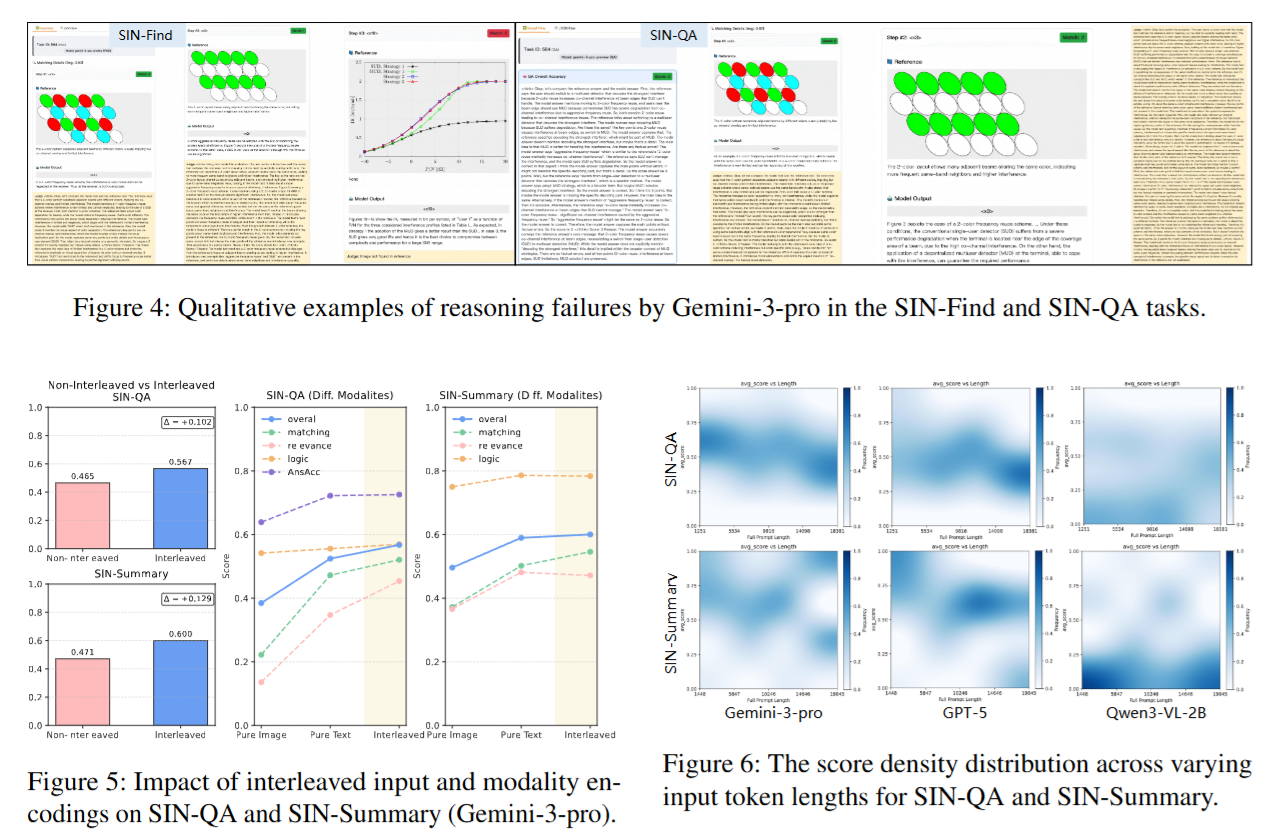
案例分析 (Case Study)
论文总结了典型失败模式,尤其具有诊断价值的是两类:
- Information Deficiency:证据链缺关键前提或覆盖不足,导致答案虽“看似合理”但无法被证据严格支持。
- Spurious Reasoning:出现“散弹式引用/shotgun citations”等现象,证据数量多但不相关,污染精度并掩盖真实推理链条。
此外,验证任务在近似负例(hard/near-miss negatives)下的断崖式性能下降进一步说明:模型往往缺乏对“证据是否真正构成支持”的细粒度辨别能力,容易被“看起来相关”的证据欺骗。
数据样本

6. 总结与贡献 (Conclusion & Contribution)
主要发现与结论
论文证明:在长上下文科学文献理解中,关键瓶颈常常不在“能否给出正确答案”,而在“能否构建可核验、顺序一致、跨模态对齐的证据链”。实证上,最强模型在总体分上领先,但答案正确性高并不必然转化为证据对齐质量高,从而揭示了“正确性–可追溯性”之间的结构性缺口。
核心贡献
- 提出 FITO:从合成检索边界转向原生长文档证据链理解的评测范式,并形式化联合建模答案与证据链。
- 构建 SIN-Data:面向科学文献的语义优先交错格式,利用引文驱动注入保留图文逻辑邻接。
- 发布 SIN-Bench:四级任务 + 统一证据接口 + 证据驱动指标(MRL)与“无证据不评分”原则,实现可诊断评测。
- 提供 可扩展构建流水线:多模型合成、交叉验证、人工审计结合,使高质量证据链样本构建从纯人工走向半自动化可扩展路径。