🚩 [ACL 2026] ProFit: Leveraging High-Value Signals in SFT via Probability-Guided Token Selection
Published in ACL, 2026
Arxiv地址:https://arxiv.org/abs/2601.09195
1. 关键词 (Keywords)
- 概率引导的Token选择 / Probability-Guided Token Selection
- Token级硬掩码监督 / Token-Level Hard Mask Supervision
- 单参考SFT过拟合 / Single-Reference SFT Overfitting
- 核心语义信号 / High-Value Semantic Signals
- 梯度干扰 / Gradient Interference
- 训练稳定性与快速收敛 / Training Stability & Rapid Convergence
- 强化学习初始化 / RL Warm-Start Initialization
2. 背景与动机 (Background & Motivation)
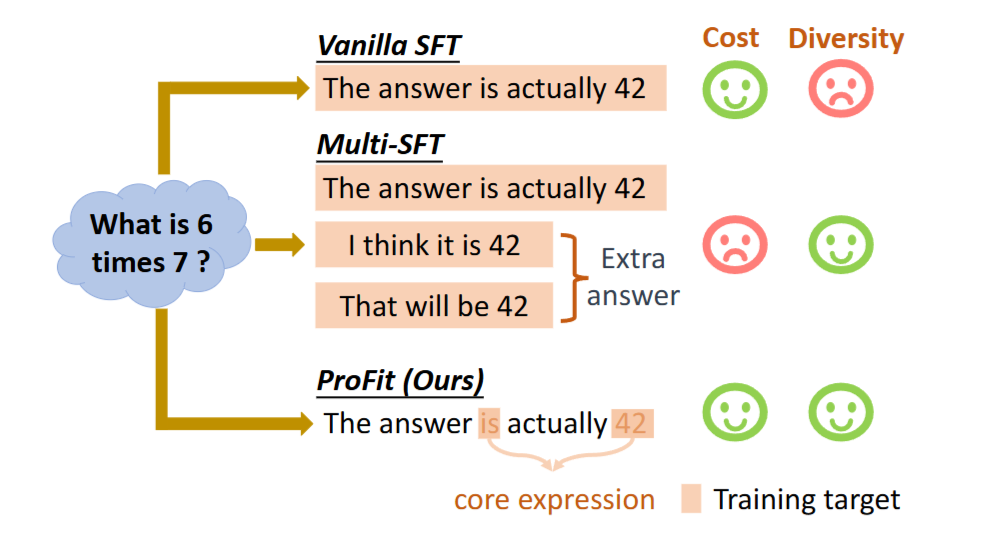
问题定义
论文要解决的核心问题是:在监督微调(SFT)中,使用单一参考答案进行逐token交叉熵训练,会把大量“可替换表述、风格碎片、非关键措辞”当作强监督目标,从而造成单参考过拟合,进而破坏模型的推理逻辑与泛化能力。换言之,训练目标把“表达一致性”错误地等同于“语义一致性”。
研究动机
- 语言天然是一对多映射:同一语义可由多种表达实现,强制token级完全对齐会放大“表面差异”的训练信号。
多参考SFT看似可解,但现实中存在两类瓶颈:
- 数据成本随参考数量线性增长;
- 多参考带来分布冲突与优化不稳定,复杂任务上容易出现收敛困难或退化。
- 因此作者选择在“单参考”这一更常见、成本更低的训练设置下,通过机制性方法抑制非核心表达的干扰,使训练聚焦于真正决定正确性的高价值信号。
3. 核心方法 (Core Methodology)
整体架构
ProFit 的框架可概括为“在线概率评估 + 二值mask筛选 + 掩码交叉熵训练”:
- 在训练时,用当前模型对每个ground-truth token 的预测概率作为信号;
- 设定阈值 τ,将 token 分为“保留更新”和“屏蔽不学”两类;
- 仅对被保留 token 计算交叉熵并反向传播,实现训练信号的选择性放大。
创新机制
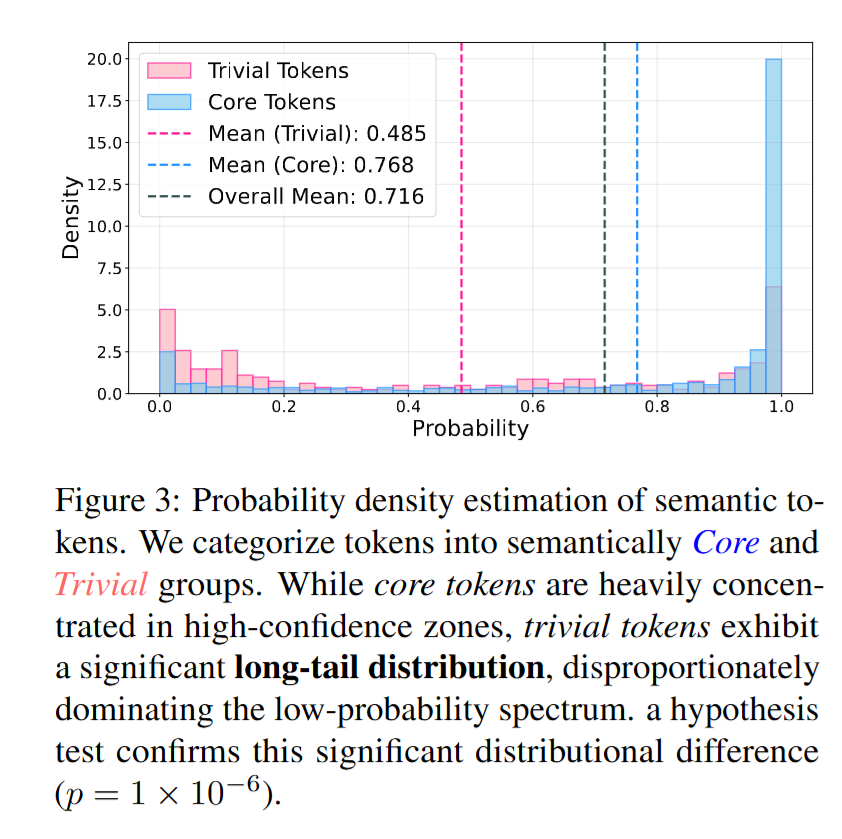
- 概率作为“语义重要性”的代理信号 作者通过语义标注实验将参考答案token分为“核心token”和“trivial token”,并统计两类token的概率分布:
- Trivial token 的平均概率约为 0.485
- Core token 的平均概率约为 0.768
- 两者分布差异显著(统计检验 p 值约为 1×10^-6) 由此提出关键经验结论:低预测概率往往对应语义非必要、可替换的表达碎片。
硬掩码与 stop-gradient 的训练门控 ProFit 使用二值mask:当模型对某个ground-truth token 的预测概率大于 τ 时才保留该token的损失;mask的计算采用 stop-gradient,使“是否保留”不参与梯度链路,从而让mask在反向传播中充当稳定的门控。
梯度干扰的理论解释 论文给出一个重要解释:在一定假设下,单token的参数梯度范数存在下界,与 (1 − 该token预测概率) 成正比。直观含义是:预测概率越低的token,可能诱发越大的梯度,从而更容易在优化中“压过”核心token的学习方向,导致训练被非核心表达主导。
实现细节
对每个位置 t,计算模型对目标token 的条件概率 p(y**t x, y**<t); - 若 p > τ,则该token参与loss与梯度;否则该token不产生训练信号;
- 训练目标等价于对序列中被mask保留的token求和交叉熵;
- τ 为静态阈值(论文中通过消融讨论其影响)。
4. 实验设计 (Experimental Design)
数据集与预处理
- 训练数据:从 BAAI-InfinityInstruct 中筛选 2000 条样本,并优先选择高reward分数样本(与 Shadow-FT 的筛选思路一致)。
- 训练框架:LLaMA-Factory。
- 训练资源:主SFT实验在 8×H20 GPU 上完成。
- 关键超参(论文给出一组核心配置):per-device batch size = 1,梯度累积 = 4,输入截断长度 = 8192;主对比设置为训练 1 个 epoch(并在后续章节展示 5 epoch 的演化曲线)。
对比模型 (Baselines)
- 标准SFT:全token统一最小化交叉熵。
- DFT:基于置信度对token loss做动态缩放(软重加权思路)。
- Entropy-based tuning:以不确定性(如高熵token)为触发条件选择更新token(选择式更新思路)。
基线选择总体合理:覆盖了“全token训练”“软重加权”“不确定性筛选”三类相邻方法谱系,能够验证ProFit的关键差异是否来自“概率阈值硬筛选 + 梯度隔离”。
评估指标 (Metrics)
- 主要评估基准:GPQA-Diamond、GSM8K、MATH-500、AIME’24、IFEval,报告准确率并汇总平均值(Avg)。
- 推理采样设置:AIME’24 使用 32 次采样平均,其余基准使用 8 次采样平均。
- 强化学习阶段:报告 Avg@4 与 Pass@4(在数学推理任务上更贴近“多次采样可得正确解”的能力)。
指标覆盖对“可判定推理/数学/指令遵循”较全面,但对开放式生成质量、多样性、风格控制等维度覆盖不足(见第7部分)。
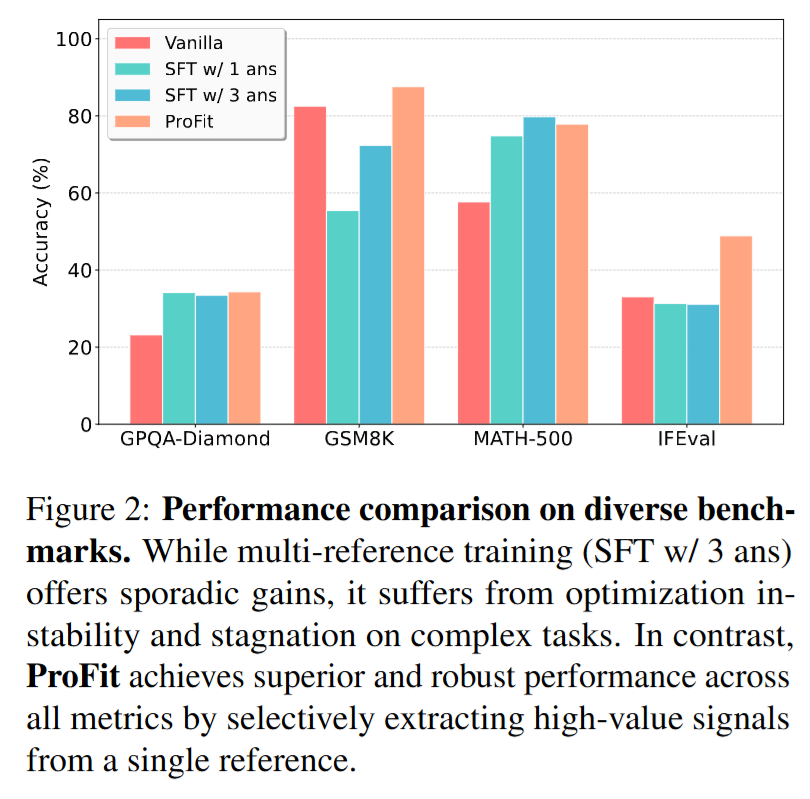
5. 实验结果与分析 (Results & Analysis)
主要结果(定量对比)
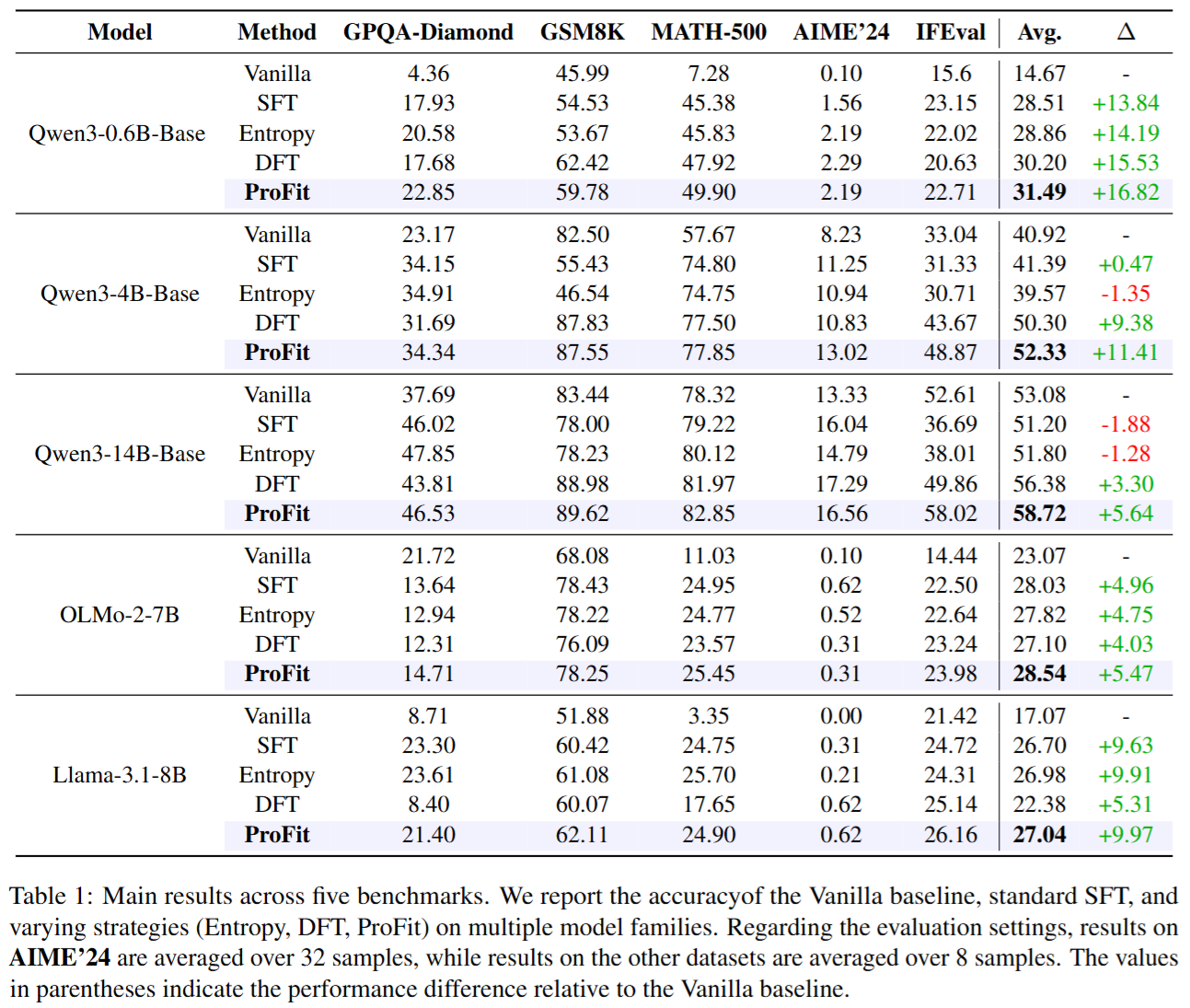
- 主结果(Table 1)显示跨模型规模与家族的稳定增益 以平均准确率 Avg 为例:
Qwen3-0.6B-Base:
- SFT = 28.51
- DFT = 30.20
- ProFit = 31.49(最高)
Qwen3-4B-Base:
- SFT = 41.39(几乎无增益)
- DFT = 50.30
- ProFit = 52.33(最高)
Qwen3-14B-Base:
- Vanilla = 53.08
- SFT = 51.20(出现退化)
- DFT = 56.38
- ProFit = 58.72(最高,且相对Vanilla提升约 +5.64)
这组结果的关键含义是:当模型规模变大或任务更复杂时,标准SFT更容易被非核心表达拖累甚至退化;ProFit通过筛选训练信号能更稳健地提升推理与指令遵循表现。
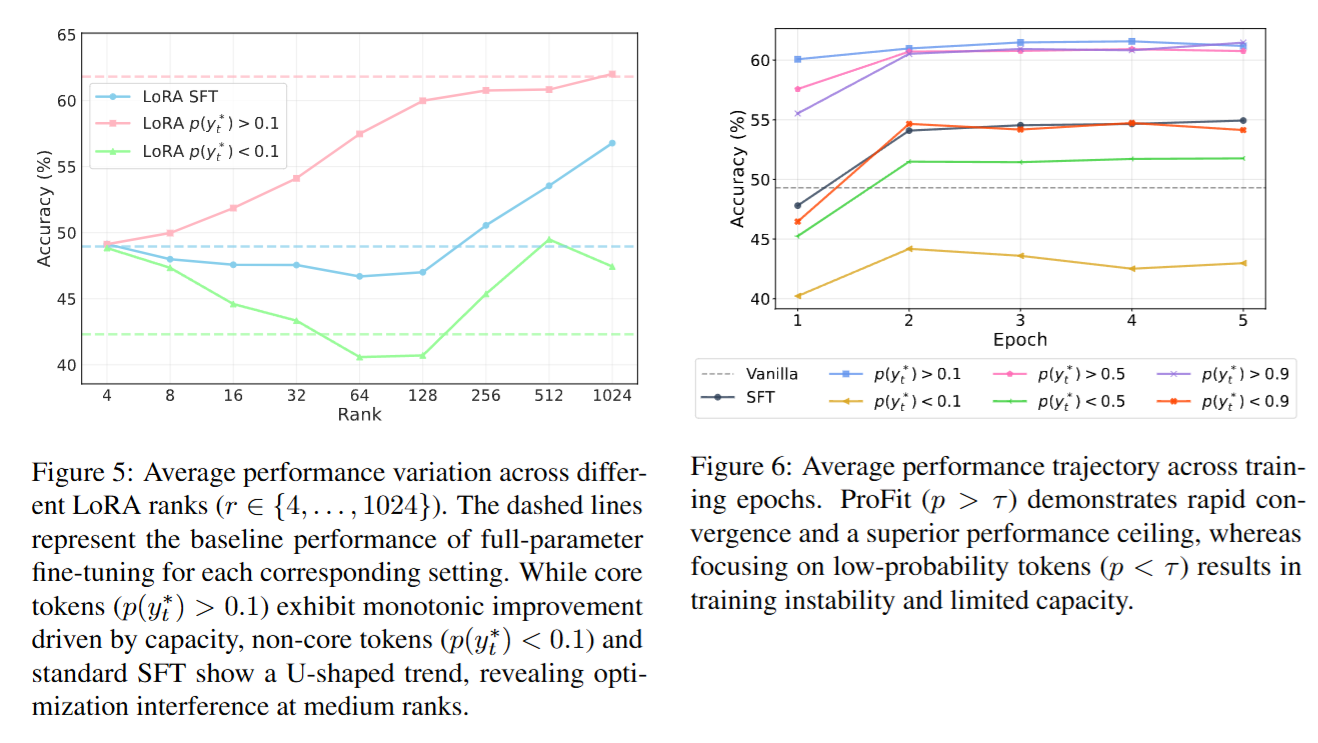
- 训练效率与收敛速度
- ProFit(保留高概率token,p > τ)在第 1 个 epoch 就达到约 60.1% 的准确率,已经超过 Baseline 的峰值约 54.9%。
- 只训练低概率token(p < τ)会在较低水平停滞,并表现出不稳定或“先升后降”的退化趋势。 这支持“去除低概率非核心信号后,训练更快、更稳、上限更高”的论断。
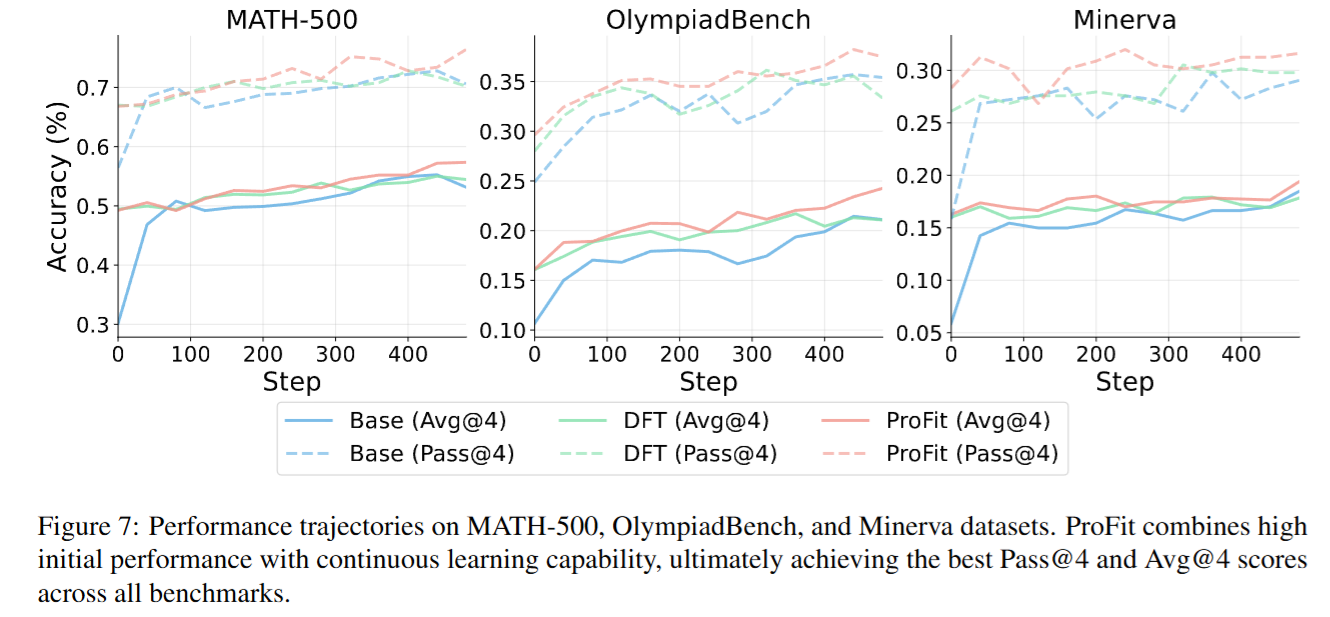
- 强化学习初始化收益 在 Qwen3-0.6B-Base 上做 GRPO 强化学习:
MATH-500 最终阶段:
- ProFit 初始化:Avg@4 = 57.3%,Pass@4 = 76.4%
- Baseline 初始化:Avg@4 = 53.1%,Pass@4 = 70.6% 说明 ProFit 不仅提升SFT阶段表现,还能作为更强的RL warm-start,提高最终可达性能。
消融研究 (Ablation Study)
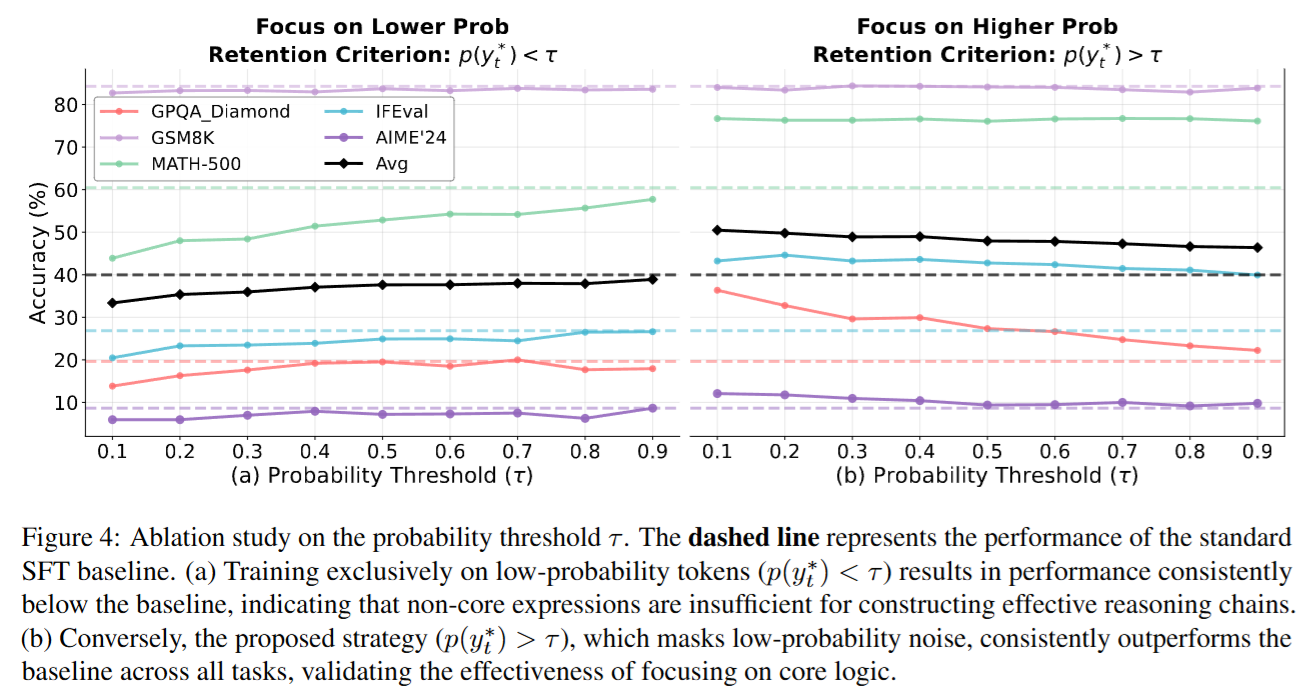
- 阈值 τ 与“保留高概率 vs 保留低概率” 消融图明确展示:
- 保留高概率token(p > τ)在各种 τ 设定下整体优于SFT;
- 反过来保留低概率token(p < τ)在各任务上显著劣于SFT,验证低概率token主导训练会损害核心推理。
- LoRA rank 扫描
- 核心token训练(例如 p > 0.1)随着LoRA rank增大呈单调受益,说明核心语义确实“需要容量”。
- trivial token训练(p < 0.1)与标准SFT呈 U 形趋势,中等rank出现优化干扰;且高rank LoRA 相对 full fine-tuning 更像一种正则化,抑制对非必要表达的过拟合。 该实验把“容量—干扰”与“非核心表达瓶颈”联系得比较紧密。
- 多epoch演化
- 对低概率token训练在 GSM8K、MATH-500 上出现“早期上升、后期下降”的 inverted-U 现象(尤其在第3到第5个epoch),符合“持续暴露于非核心表达导致过拟合并伤害推理逻辑”的解释。
案例分析 (Case Study)
论文给出一个多项式因式分解/系数比较任务:
- 参考解通过代数关系将高次幂化简并比较系数,得到 (p, q, r) = (6, 31, −1)。
- SFT 解答出现典型错误:在展开乘积时“凭空引入约束”或忽略交互项(例如把某些系数独立设为0),导致最终输出错误三元组。
- ProFit 解答采用更一致的系数比较链条,最终得到正确答案 (6, 31, −1)。 该案例直观说明:ProFit 的核心收益不是“减少监督”,而是避免非核心、低概率表达诱发的大梯度扰动破坏关键推理链。

6. 总结与贡献 (Conclusion & Contribution)
论文的主要结论是:在单参考SFT中,模型对ground-truth token 的预测概率可作为“语义重要性”的有效代理;通过对低概率token进行硬掩码屏蔽,训练可聚焦高价值核心信号,从而提升推理/数学/指令遵循任务的准确率、训练稳定性与收敛效率,并进一步改善强化学习阶段的初始化质量。
核心贡献可概括为四点:
- 经验发现:用语义标注与概率分布统计论证“核心token更高概率、trivial token占据低概率长尾”。
- 方法贡献:提出简单、可复用、低成本的概率阈值硬筛选训练目标(含stop-gradient门控)。
- 理论解释:从梯度下界角度解释低概率token为何更易主导优化并造成干扰。
- 实证收益:跨模型族与规模的稳定提升,并展示对RL warm-start的额外价值。