💭 Nav-R^2 Dual-Relation Reasoning for Generalizable Open-Vocabulary Object-Goal Navigation
Published in Arxiv, 2025
关键词 (Keywords):
- 目标导向导航 (Object-Goal Navigation, ObjectNav)
- 思维链 (Chain-of-Thought, CoT)
- 双重关系推理 (Dual-Relation Reasoning)
- 相似度感知记忆 (Similarity-Aware Memory, SA-Mem)
- 开放词表 (Open-Vocabulary)
Arxiv地址:https://arxiv.org/abs/2512.02400
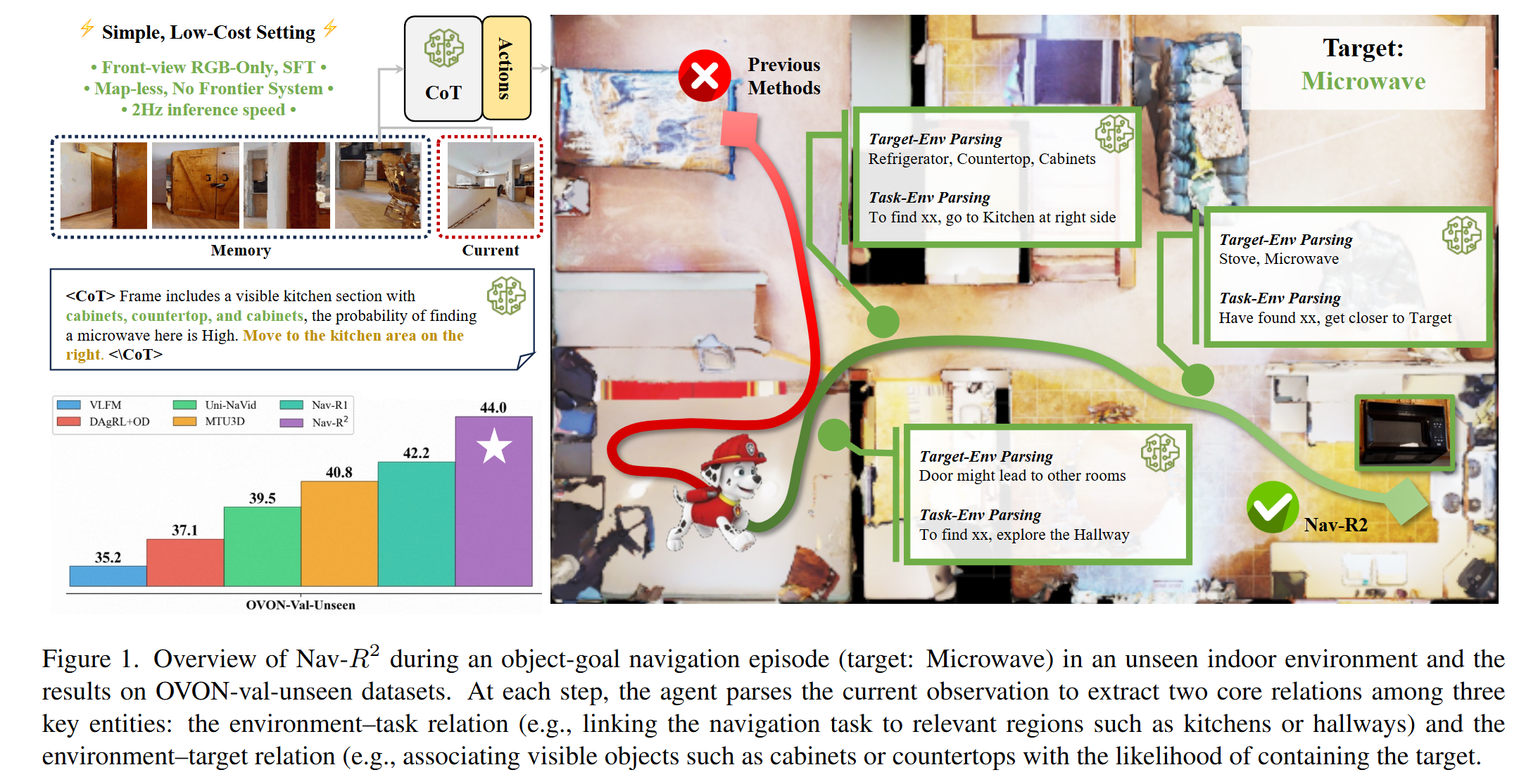
1. 背景与动机 (Background & Motivation)
问题定义
论文聚焦于具身智能中的核心挑战——开放词汇目标导向导航 (Open-Vocabulary ObjectNav)。该任务要求智能体在未见过的室内环境中,仅依据第一人称视觉输入,搜索并定位指定的目标物体。其难点在于,智能体不仅要处理熟悉的物体,还必须具备泛化能力,能够识别和定位训练期间从未见过的物体类别。
研究动机
现有方法在处理这一任务时存在显著局限。一类方法依赖黑盒强化学习或模块化建图(如 VLFM, Uni-Navid),这类方法决策过程不透明,缺乏细粒度的推理能力,导致在未见物体上的泛化性较差。另一类方法虽然引入了思维链(CoT),但其推理结构往往是隐式或混乱的,未能将“感知”与“规划”有效解耦。为了实现鲁棒的导航,作者认为必须显式且结构化地建模两个核心关系:即“感知”层面的目标-环境关系(Target-Environment)和“规划”层面的环境-动作关系(Environment-Action)。此外,针对长序列视频任务中容易出现的信息丢失问题,设计一种能保留细粒度视觉线索的高效记忆模块也至关重要。
2. 核心方法 (Core Methodology)
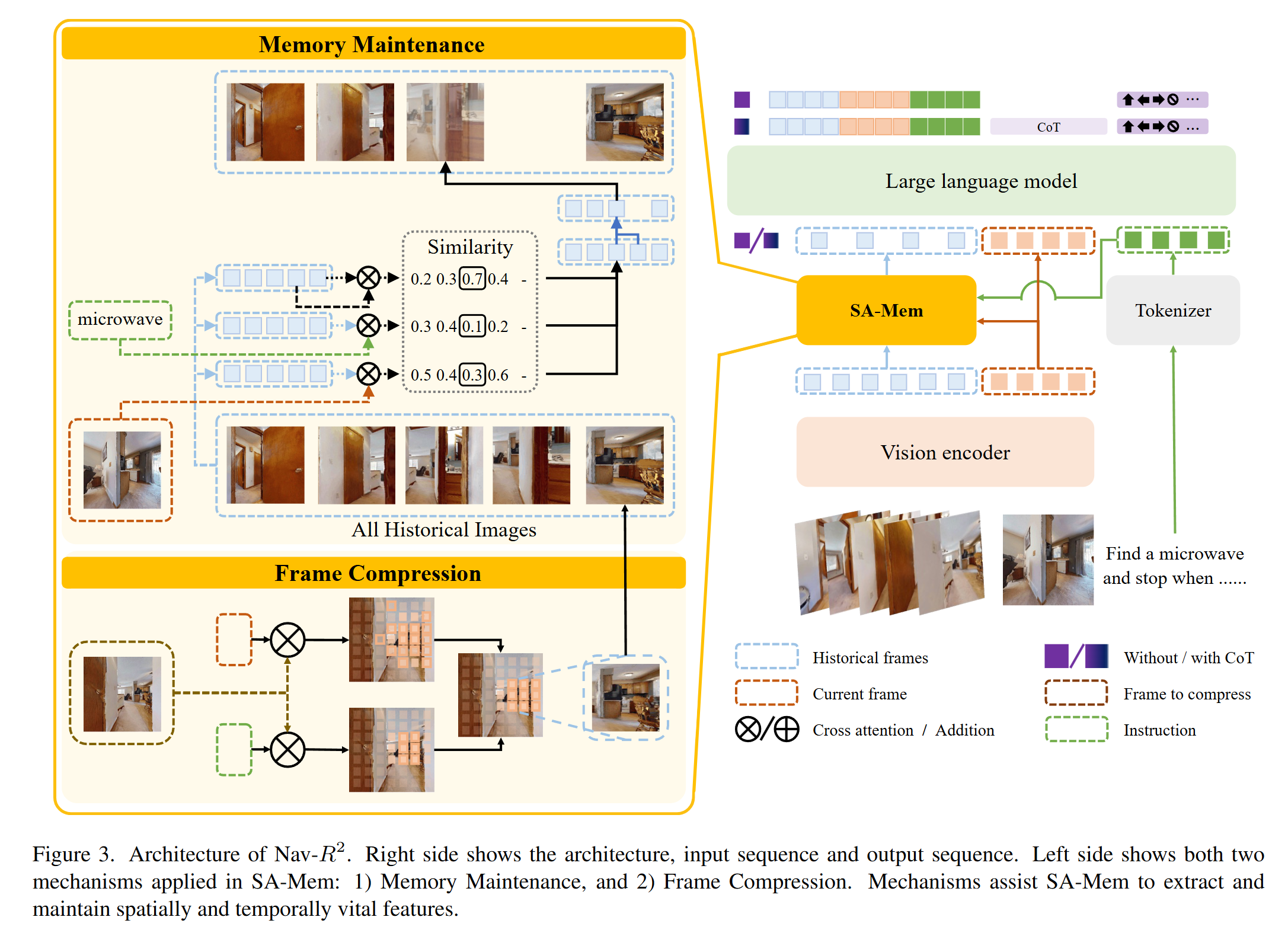
整体架构
论文提出了 Nav-$R^{2}$ 框架,这是一个完全基于视觉-语言模型(VLM)的端到端系统。该系统仅使用第一人称 RGB 图像作为输入,摒弃了对深度图或预建地图的依赖。架构主要由三个部分组成:视觉编码器、相似度感知记忆 (SA-Mem) 以及大语言模型骨干 (LLM Backbone)。
创新机制:双重关系推理
为了赋予智能体清晰的推理能力,模型通过结构化的 CoT 强制在每一步进行两个维度的思考。首先是目标-环境解析 (Target-Env Parsing),即感知层面的推理,分析当前视野中的物体特征是否与目标在语义或空间上相关(例如:看到“炉灶”推断“微波炉”可能在附近);其次是环境-动作解析 (Env-Action Parsing),即规划层面的推理,基于对环境的理解决定下一步的搜索方向(例如:为了找到目标,应该前往右侧区域)。
创新机制:相似度感知记忆 (SA-Mem)
这是一个无需额外参数的显式记忆模块,旨在解决长序列视觉信息的存储效率问题。它包含两个关键策略:
- 帧压缩: 对于历史帧,仅保留与“当前指令”和“当前帧”相似度最高的 Top-K tokens,去除冗余信息。
- 记忆维护: 当记忆长度达到上限时,不简单丢弃旧帧,而是计算相邻帧的加权融合概率,将最相似的相邻帧进行特征融合。这种机制既保留了关键的时间上下文,又有效减少了噪声。

数据构建与实现细节
为了训练该模型,作者构建了 NavR2-CoT 数据集。利用 HM3D-OVON 数据集中的专家轨迹,配合 Qwen2.5-VL-7B 生成结构化 CoT 注释,并实施了严格的数据清洗(如去除表示不确定的词汇),最终获得约 30 万条高质量样本。在实现上,模型基于 Qwen2.5-VL-7B 进行全量监督微调 (SFT),推理速度可达 2Hz,实现了高效的实时导航。
3. 实验设计 (Experimental Design)
数据集与评估体系
实验主要在标准的开放词汇 ObjectNav 基准——HM3D-OVON 数据集上进行。评估指标采用任务成功率 (SR) 和路径长度加权成功率 (SPL),前者衡量任务完成情况,后者兼顾导航效率。
对比模型选择
为了全面评估性能,论文选取了两类具有代表性的基线模型。一类是无深度图方法(RGB-only),如 Uni-Navid 和 VLFM,这是与本文方法最直接的竞品;另一类是依赖深度图或地图构建的方法,如 Nav-R1 和 MTU3D,这类方法通常被认为通过引入几何信息具有先天优势,用于对比本文纯视觉方案的潜力。
4. 实验结果与分析 (Results & Analysis)
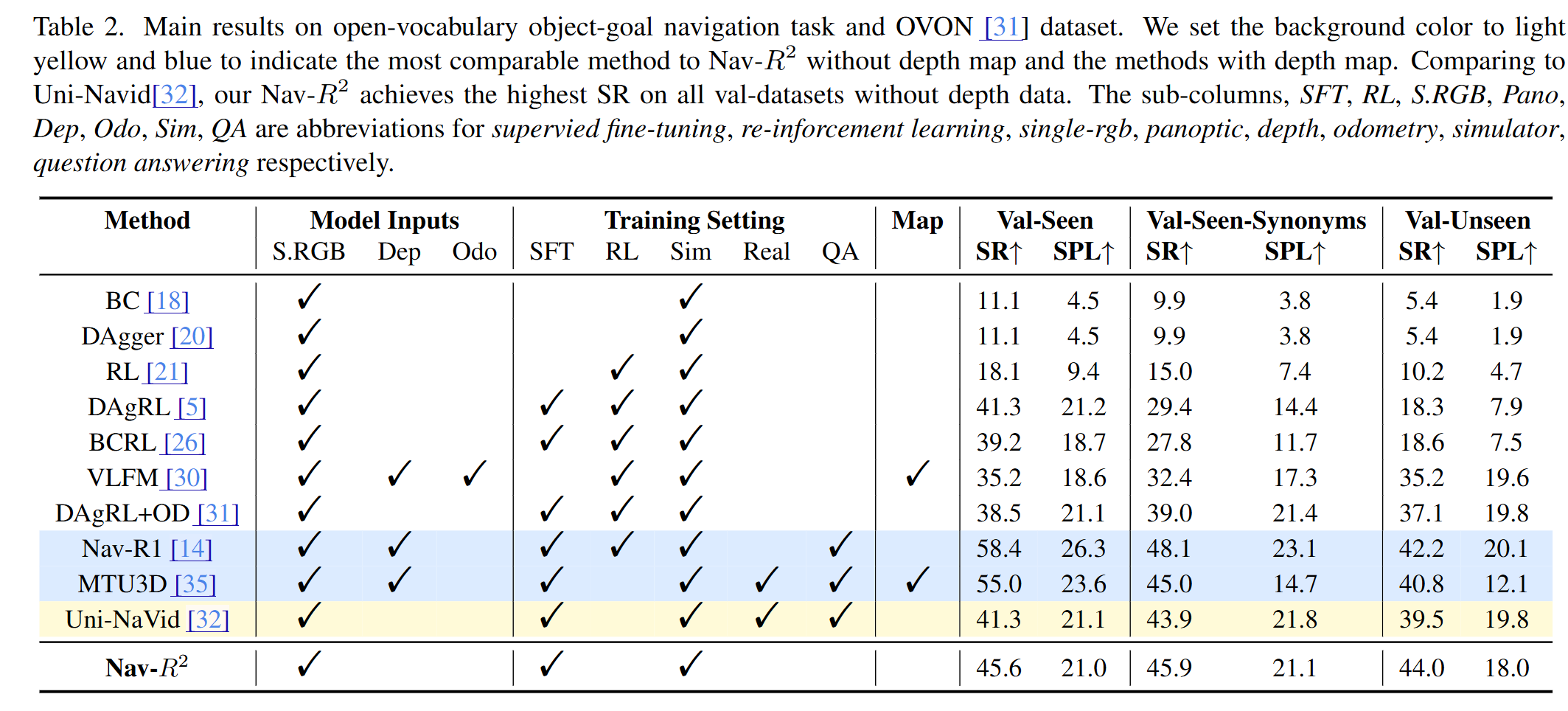
主要结果
Nav-$R^{2}$ 展现了卓越的性能。在最具挑战性的 OVON-Val-Unseen(未见场景、未见物体)测试集上,取得了 44.0% 的成功率 (SR),显著优于之前的 SOTA 方法 Uni-Navid (39.5%)。值得注意的是,相比于依赖深度图的方法(如 Nav-R1, SR 42.2%),Nav-$R^{2}$ 仅使用 RGB 图像就在未见测试集上取得了更高的成功率。作者分析认为,这是因为摒弃深度图避免了模型对特定场景几何结构的过拟合,从而提升了泛化性。
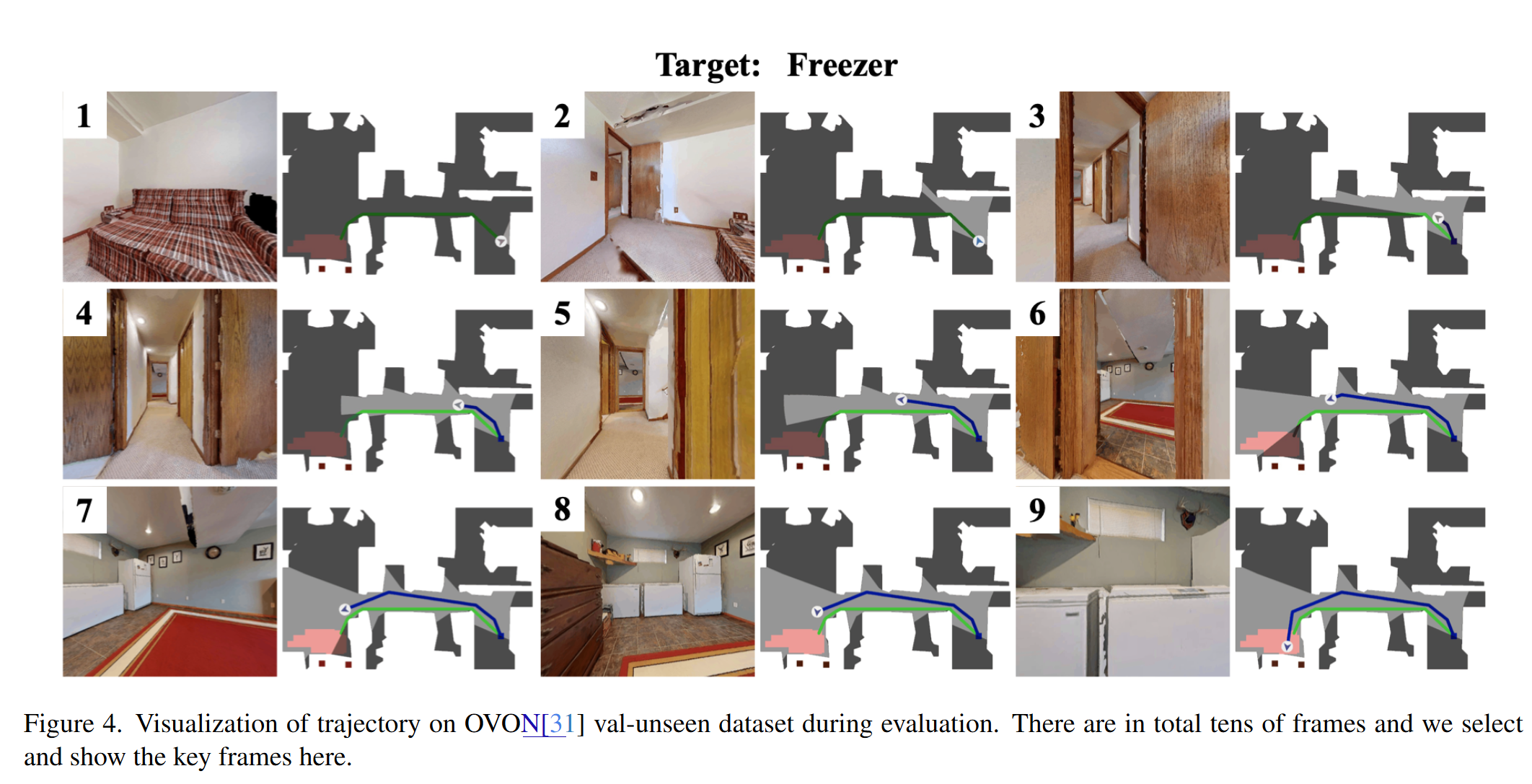

消融研究与案例分析
消融实验证实了核心组件的有效性。仅引入 CoT 训练,模型在 Unseen 数据集上的 SR 就从 14.8% 提升至 28.4%;而同时包含双重关系推理的配置取得了最高性能。针对 SA-Mem,实验显示采用基于相关性的“融合”策略比简单的移除旧帧效果更好。定性分析展示了一个寻找“洗碗机”的案例,Nav-$R^{2}$ 准确推理出“背景中的厨房区域可能包含洗碗机”并规划路径,其生成的思维链与实际行动高度一致,证明了模型具备真正的推理能力。
5. 总结与贡献 (Conclusion & Contribution)
总结
Nav-$R^{2}$ 成功地将类似于人类的“双重关系推理”机制引入到端到端的视觉导航模型中。配合高效的 SA-Mem 记忆机制和专门构建的 NavR2-CoT 数据集,该模型在不依赖深度传感器和预建地图的情况下,实现了开放词汇目标导航的 SOTA 性能。
核心贡献
这项工作的主要贡献包括:
- 提出了显式解耦感知与规划的双重关系推理框架。
- 构建并开源了高质量的 NavR2-CoT 数据集,填补了该领域结构化思维链数据的空白。
- 设计了非参数化的 SA-Mem 记忆机制,通过特征融合高效保留时空信息。
- 实现了仅需 RGB 输入的 2Hz 实时推理,具备极高的工程落地价值。