💭 VeriGUI: Verifiable Long-Chain GUI Dataset
Published in Arxiv, 2025
关键词
- 长链复杂性 (Long-Chain Complexity)
- 子任务可验证性 (Subtask-Level Verifiability)
- 图形用户界面代理 (GUI Agents)
- 多模态大语言模型 (Multimodal Large Language Models, MLLMs)
- 部分可观测马尔可夫决策过程 (Partially Observable Markov Decision Process, POMDP)
- 任务分解 (Task Decomposition)
- 深度研究代理 (Deep Research Agents)
- 浏览器交互代理 (Browser-Use Agents)
- 动作效率 (Action Efficiency)
- 成功率与完成率 (Success Rate & Completion Rate)
Arxiv地址:https://arxiv.org/abs/2508.04026
背景
近年来,自主GUI代理成为人机交互的重要研究方向。借助多模态大语言模型,研究者希望构建能够处理复杂计算机任务的智能体。然而,现有数据集主要存在两大挑战:
- 任务短期化:大多数基准仅涉及少量操作步骤(通常不足10步),缺乏对长程规划与复杂推理的考察。
- 验证粗粒度:多数采用结果级验证,仅检验最终页面或输出,无法定位中间环节错误,从而限制了代理的改进空间。
因此,如何获得覆盖真实交互场景、支持长链任务分解与细粒度验证的数据集,成为推动GUI代理发展的核心难题。
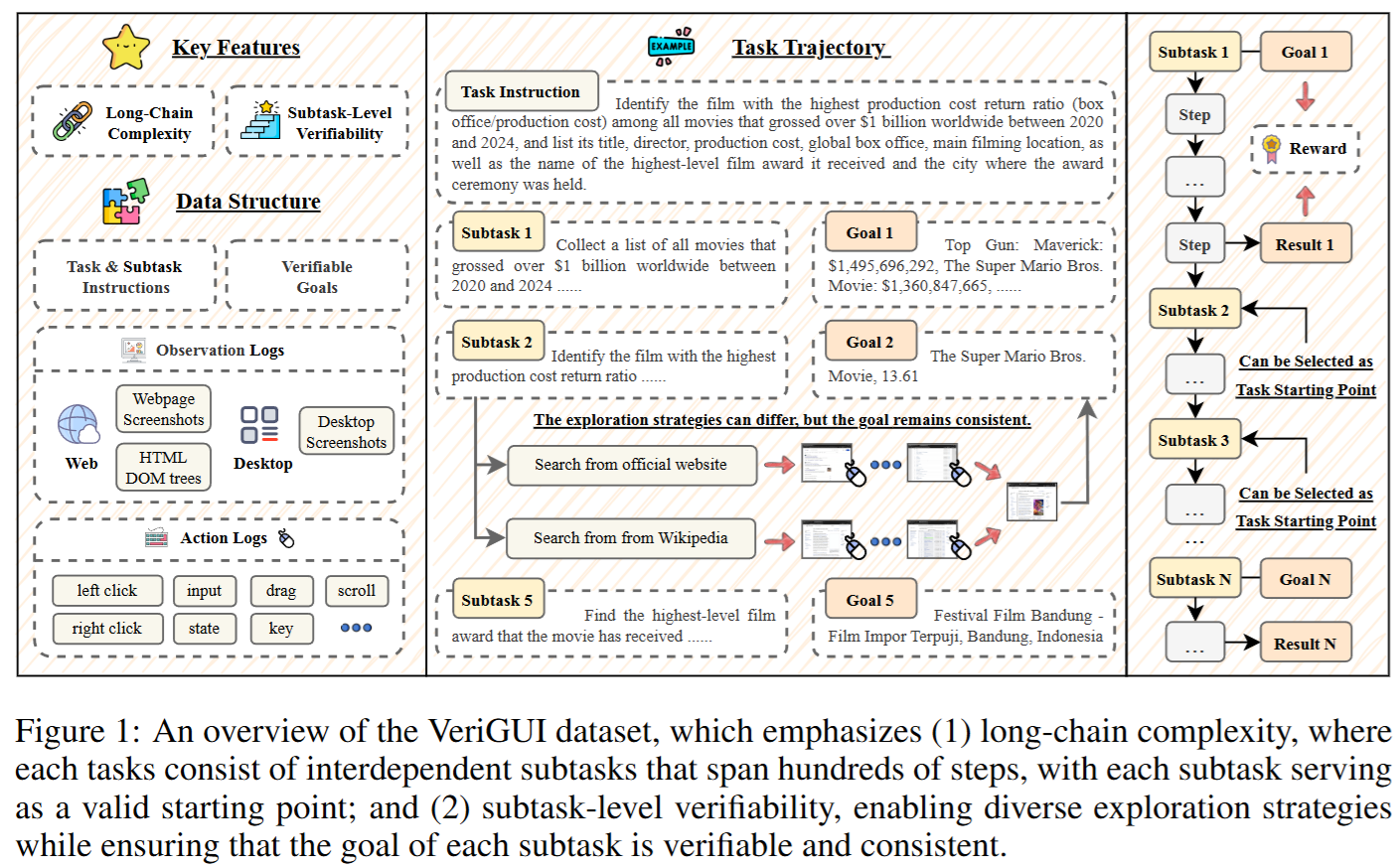
方法

任务建模框架
论文将 GUI 任务形式化为 部分可观测马尔可夫决策过程 (POMDP),由以下要素组成:
- 状态空间 (S):表示底层系统的完整配置。
- 观测空间 (O):包括网页截图、HTML DOM 树,或桌面GUI截图,模拟代理在部分可观测环境下的输入。
- 动作空间 (A):统一为通用的 GUI 操作(如点击、输入、滚动、拖拽、键盘操作等)。
- 状态转移函数 (P):描述 GUI 环境对操作的响应。
- 奖励函数 (R):基于子任务级可验证目标,为每个子任务提供二值监督信号。
通过该建模,VeriGUI 不仅支持完整任务的评估,还支持 子任务级别的独立验证。
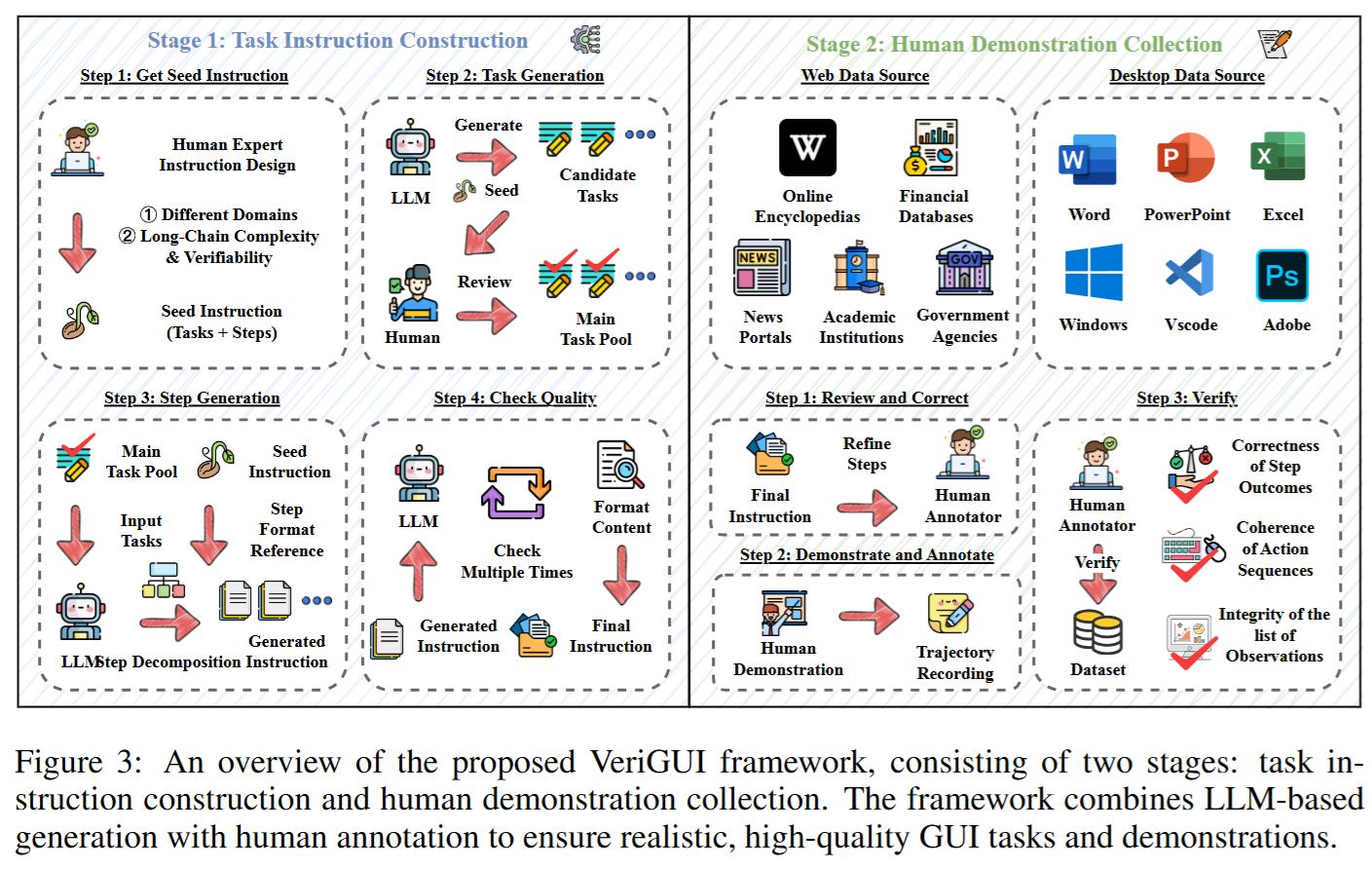
任务指令构建流程
任务指令的生成采用 “大模型生成 + 人类审查” 的多阶段流程:
- 种子任务选取
- 在每个主题领域(如科学、金融、社会、科技、艺术等)人工挑选一批种子任务,作为任务库的初始输入。
- 任务扩展与生成
- 通过大模型(LLMs)扩展种子任务,生成大量候选任务。
- 人工对候选任务进行筛选,保留语义清晰、可执行的任务。
- 子任务分解
- 使用 LLM 进一步将完整任务自动分解为多个子任务(通常为 4–8个)。
- 每个子任务对应一个独立的目标函数 G(k),确保可验证性。
- 质量检测与多重审查
- 自动化过滤:检查格式、逻辑一致性。
- 人工多轮审核:确保指令的事实正确性、合理性与可执行性。
- 最终仅保留通过所有审查的任务,进入正式任务池。
人工示范收集
在任务指令准备好后,由人工标注员执行任务,并记录完整的操作轨迹:
- 任务执行与轨迹记录
- 人工在真实环境中操作(网页或桌面软件)。
- 使用屏幕录制和日志工具收集:
- 操作日志 (Action Logs):记录点击、输入、拖动等动作。
- 观测日志 (Observation Logs):记录任务过程中可见的界面截图或DOM树。
- 子任务目标 (Goals):定义每个子任务的成功条件。
- 人工优化与修正
- 在执行过程中,人工会根据可行性微调子任务顺序,保证操作的连贯性与可行性。
- 验证与质控
- 自动验证:检查操作序列的逻辑一致性。
- 人工复核:确保子任务结果正确、操作轨迹完整。
- 只有通过自动与人工双重验证的示范数据才被保留。
这样,VeriGUI 不仅包含了 长链的任务分解,还保证了子任务的可验证性,避免了传统数据集“只看最终结果”的缺陷.
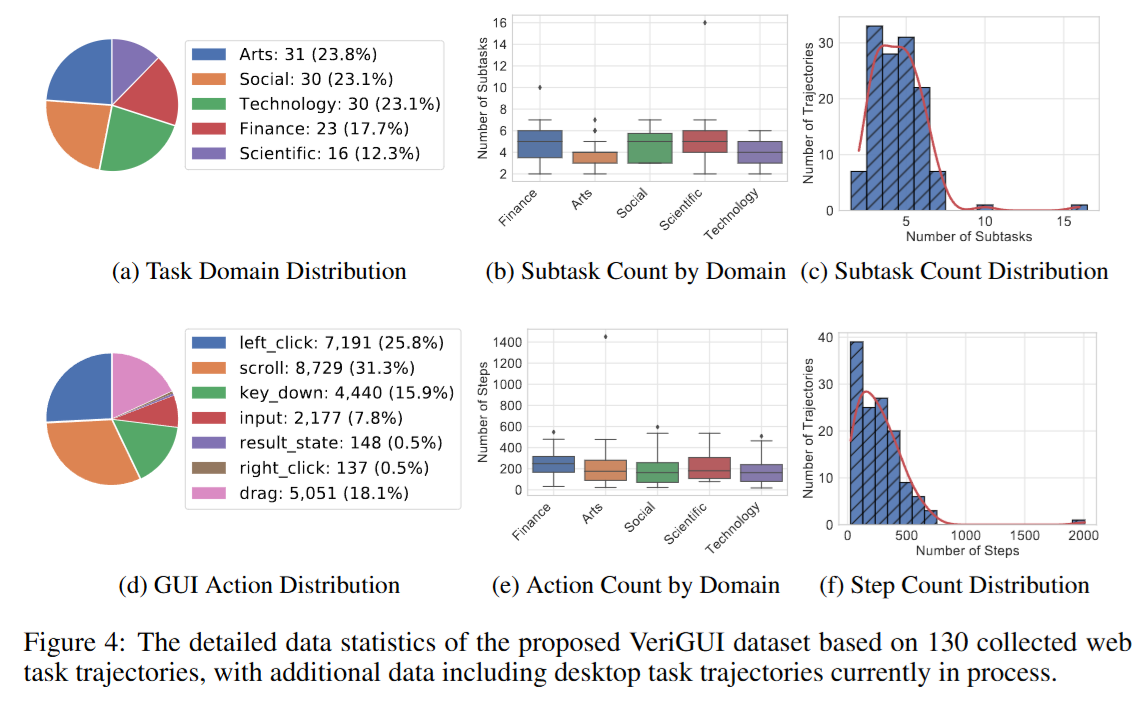
- 数据统计特征
基于当前已完成的 130个网页任务:
- 平均每个任务含 4.5个子任务、214步操作。
- 总计包含 27,873个步骤、587个子任务。
- 行为分布涵盖点击、滚动、输入、键盘操作等常见GUI行为,其中滚动 (31.3%) 和点击 (25.8%) 最为常见。
- 任务主题分布均衡,覆盖科研、金融、社会、艺术与科技。
实验
实验部分主要集中在 130个网页任务上,未来将扩展至桌面环境。
- 任务建模:基于 POMDP 框架,定义状态、观测、动作空间与奖励函数。
- 数据源:网页任务涵盖科研、金融、科技、艺术、社会等五大领域;桌面任务涉及办公软件、系统工具与专业软件。
- 动作空间:统一为常见GUI操作(点击、拖动、输入、滚动、按键等)。
评价指标:
- 成功率 (SR):是否完成整体任务目标。
- 完成率 (CR):输出正确元素占比。
- 动作效率 (AE):完成任务所需操作步数(仅对成功任务定义)。
此外,实验还引入了 SR@k 指标,用于分析在前k个子任务被正确执行的前提下,代理的整体完成情况。
实验在多类代理与基础模型上进行:
- 深度研究代理(如 OpenAI Deep Research、Gemini Deep Research)
- 搜索引擎型代理(结合大模型与开源搜索工具)
- 浏览器交互型代理(直接操作网页元素)
- 多智能体系统(如 Camel OWL 与 OpenAI-o3)
结果
总体表现
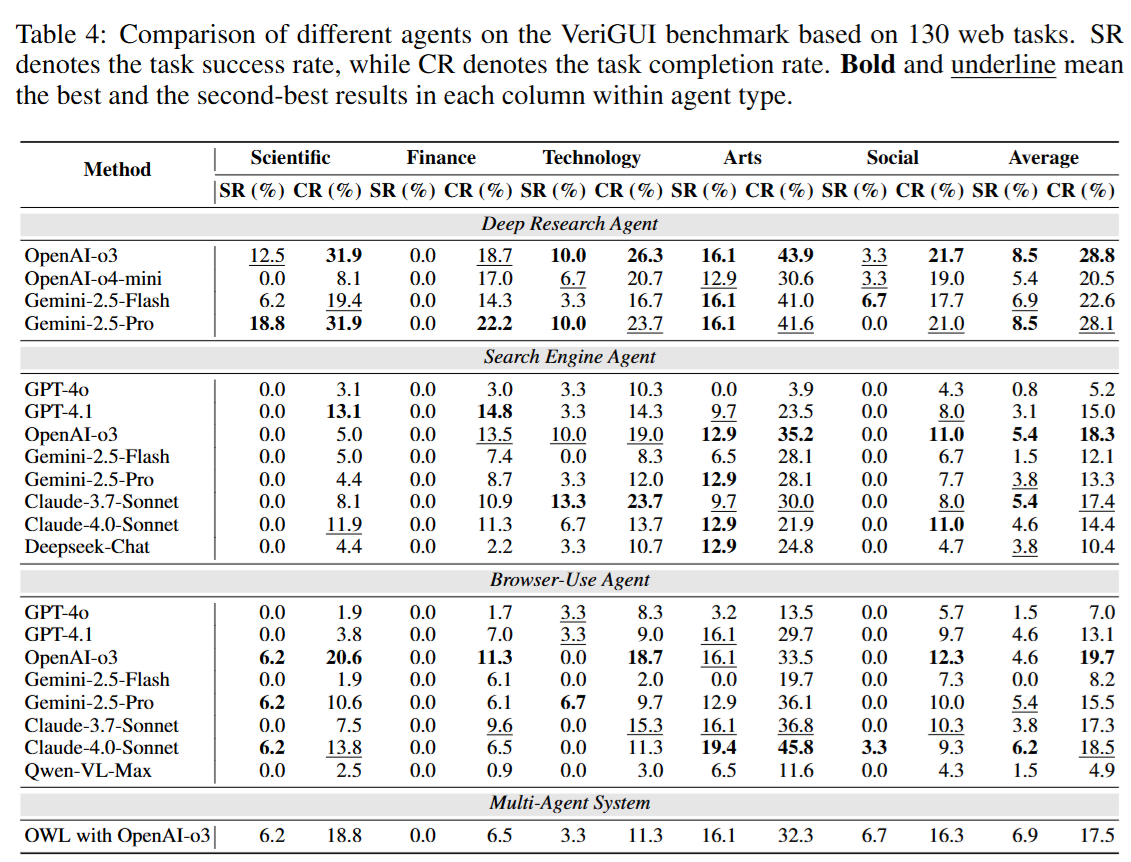
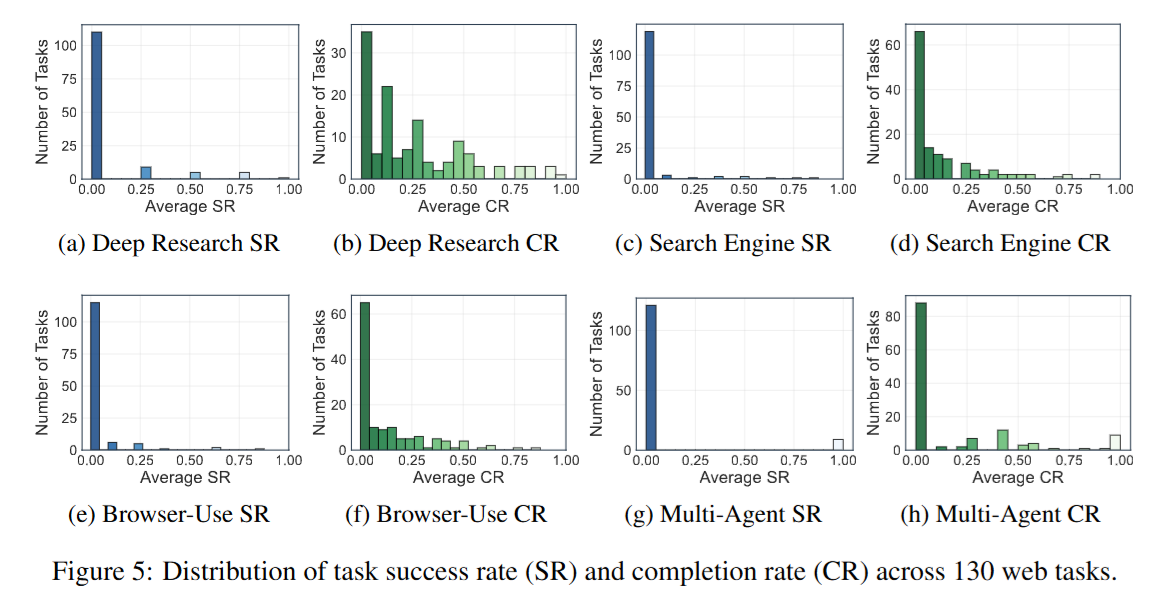
在 VeriGUI 上评测的所有主流 大模型与GUI代理(包括 OpenAI-o3、Gemini-2.5-Pro、GPT-4o、Deep Research Agents、Camel OWL 等)整体表现都不理想:
- 成功率 (SR):整体平均 低于 10%。
- 完成率 (CR):整体平均 低于 30%。
- 动作效率 (AE):成功任务中,平均操作步数普遍远高于人类示范。
说明现有 GUI 代理在长链复杂任务中的表现远未达到可用水准,特别是在跨子任务的长期规划和错误恢复方面存在明显不足
不同代理范式的对比
论文比较了三类典型的 GUI 代理:
- 深度研究代理 (Deep Research Agents)
- 代表:OpenAI Deep Research、Gemini Deep Research。
- 优势:在需要多轮搜索与文档综合的任务中表现最好。
- 局限:面对需要精确 GUI 操作的任务(如复杂表格、金融计算)时容易失败。
- 浏览器交互代理 (Browser-Use Agents)
- 优势:能直接操作网页 DOM,适合需要多步精确交互的任务。
- 局限:缺乏对任务全局规划的能力,容易卡死或遗漏步骤。
- 多智能体系统 (Multi-Agent Systems)
- 代表:Camel OWL、OpenAI-o3。
- 优势:在任务分解和子任务并行方面更有优势。
- 局限:不同子代理之间的协调仍然存在瓶颈,容易出现信息丢失和冗余操作。
实验结果显示:深度研究代理在信息检索类任务中表现最好,而 浏览器交互代理在处理 GUI 操作时更具优势;多智能体系统在复杂任务中有潜力但稳定性不足。
跨领域表现差异
VeriGUI 的任务覆盖五大主题领域(科研、金融、科技、社会、艺术娱乐),结果显示出明显差异:
- 艺术与娱乐 (Art & Entertainment):任务相对简单,代理平均完成率最高。
- 科学与科技 (Science & Technology):中等难度,完成率有一定波动。
- 社会政策 (Society & Policy) 与 金融 (Finance):表现最差,原因在于:需要跨多步骤的精确推理(如计算、信息整合);任务目标往往存在歧义,需要外部知识支持。
说明领域知识与任务复杂性对代理性能有强烈影响,尤其是金融与政策类任务对模型推理与稳健性要求更高。
子任务可验证性与 SR@k 结果
论文引入了 SR@k 指标(即在前k个子任务正确执行的前提下的成功率),结果表明:
- 当前几个子任务完成时,整体任务成功率显著提升。
- 说明代理主要在 中后段任务执行中失败,暴露出在长程规划与状态跟踪上的不足。
- 子任务验证机制可以帮助定位错误发生的位置,有助于未来改进。

错误类型与失败原因分析
实验还对代理的失败原因进行了分类:
- 任务理解错误:无法正确解析指令,导致一开始就走错方向。
- 子任务边界错误:跨子任务时无法正确衔接,导致逻辑断裂。
- GUI交互错误:点击错误元素、滚动错位、输入错误等。
- 状态遗忘:在长链任务中丢失关键信息,导致后续操作错误。
- 效率低下:执行大量冗余操作,超出合理步数范围后失败。
这些结果表明,未来的研究需要在 任务分解、长期记忆、错误恢复机制 上进一步优化
总结
VeriGUI 的提出在以下方面具有重要意义:
- 突破短期任务限制:引入长链、多子任务结构,更贴近真实应用需求。
- 强化可验证性:通过子任务级验证,能够明确定位失败环节,指导模型优化。
- 揭示现有局限:实验表明,当前GUI代理在长程推理、错误恢复与多步骤决策方面仍存在显著不足。
- 研究价值:VeriGUI 不仅是一个数据集,更是推动通用型交互智能体研究的重要基准,为未来发展更健壮的规划与决策能力提供了测试平台。