💭 AnyCap Project: A Unified Framework, Dataset, and Benchmark for Controllable Omni-modal Captioning
Published in Arxiv, 2025
关键词
- 可控字幕生成(Controllable Captioning)
- 全模态智能(Omni-modal Intelligence)
- 即插即用框架(Plug-and-play Framework)
- 基于偏好的数据集(Preference-based Dataset)
- 评估基准(Evaluation Benchmark)
- 关键点密度(Keypoint Density)
- 多模态大语言模型(Multimodal Large Language Models)
- 幻觉减少(Hallucination Reduction)
- 图像字幕生成(Image Captioning)
- 视频字幕生成(Video Captioning)
- 音频字幕生成(Audio Captioning)
Arxiv地址:https://arxiv.org/abs/2507.12841
背景
可控字幕生成是多模态对齐和指令跟随的关键技术,但现有模型在细粒度控制和可靠评估方面存在显著局限性。该论文针对这一问题,系统性地识别出三大挑战:首先,开源模型的可控能力有限,通常依赖于刚性控制信号(如软提示或边界框),难以灵活响应自然语言指令,且重新训练成本高昂,可能削弱模型的整体语言能力;其次,缺乏覆盖图像、视频和音频的全模态可控字幕数据集,手动标注成本高昂,而模型生成数据管道的质量保障不足,导致大规模数据生成困难;最后,现有的评估基准和指标(如BLEU和CIDEr)忽略内容准确性和风格遵守,LLM-based评分器则存在高方差、风格偏置和诊断能力弱等问题。这些挑战制约了可控全模态字幕生成在检索、问答和内容生成等下游任务中的应用。该论文通过提出统一的框架、数据集和基准,旨在全面解决这些痛点,推动多模态大语言模型向更精确、可靠的方向演进。
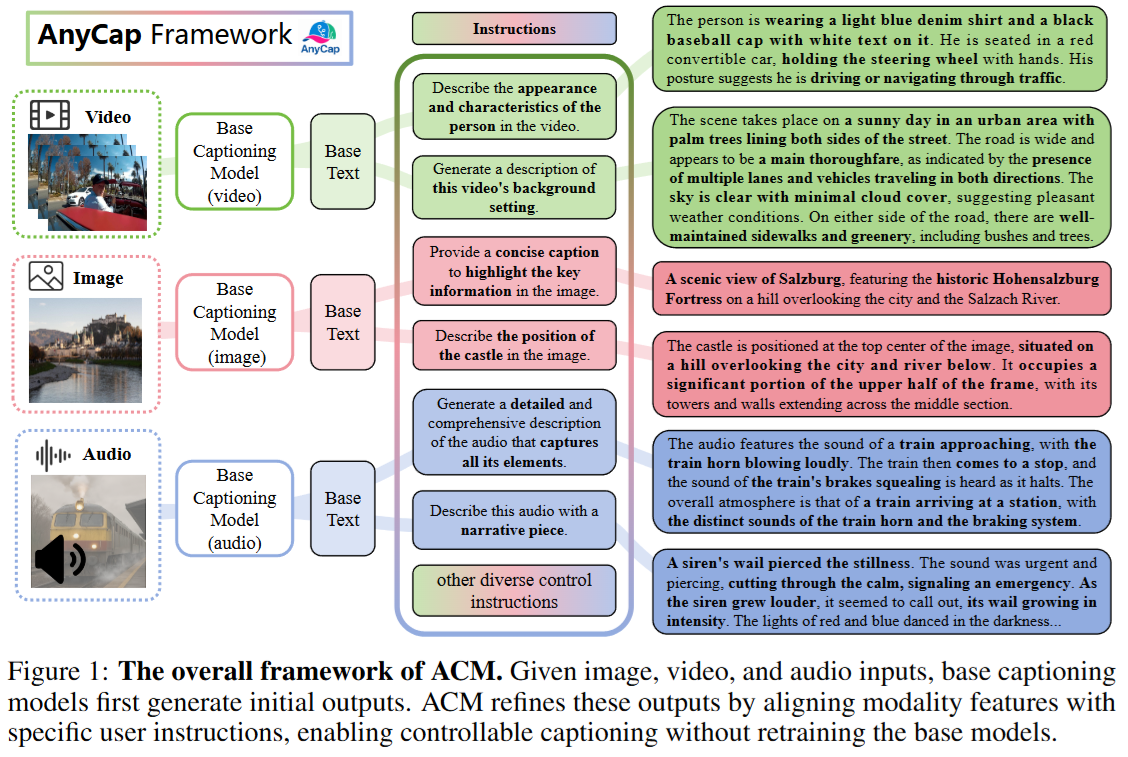
方法
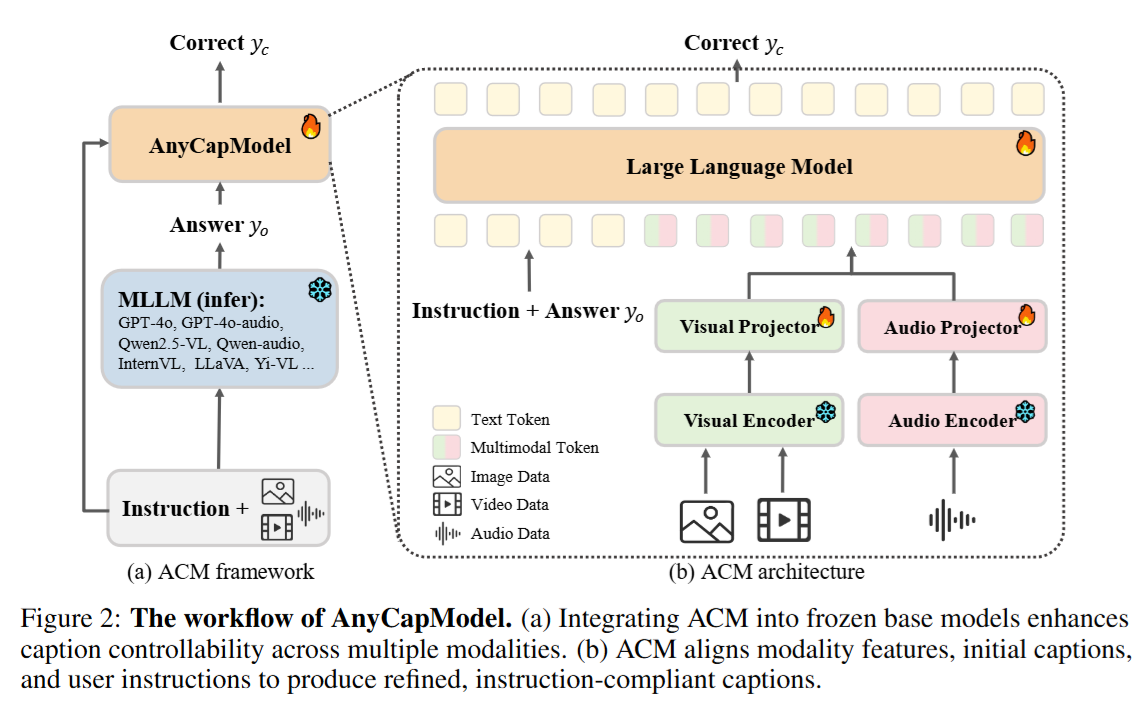
该论文提出AnyCap项目,包括模型框架、数据集和评估基准三部分。首先,AnyCapModel (ACM)是一个轻量级即插即用框架,用于增强现有基础模型的全模态字幕可控性,而无需重新训练基础模型。具体而言,ACM首先利用冻结的基础模型(如GPT-4o或InternVL)从模态输入(图像、视频或音频)生成初始字幕,然后通过对齐用户指令、模态特征和初始字幕来产生改进字幕。架构上,ACM采用模态特定编码器(如InternViT用于视觉,EAT用于音频)提取特征,并通过MLP投影到共享语义空间,与指令和初始字幕的文本嵌入拼接后输入自回归语言模型生成精炼字幕。训练采用残差校正策略,聚焦于修正无控或幻觉输出,同时包含40%的完全匹配数据以提升对齐能力。
其次,为解决数据不足,论文构建AnyCapDataset (ACD),一个大规模全模态数据集,覆盖图像(125k样本)、视频(100k样本)和音频(75k样本)三种模态,共300k条目和28种控制指令(包括内容控制如背景、实例位置,和风格控制如简洁、长度)。数据集采用偏好对形式(chosen优选字幕 vs. rejected次优字幕),通过精心设计的提示引导开源和专有模型生成数据,并经手动验证确保质量(合规率>95%)。
最后,为实现可靠评估,论文设计AnyCapEval基准,将内容准确性和风格保真度解耦评估。内容评估引入关键点密度 (KPD),从参考字幕和指令中提取关键点集,通过GPT-4o匹配候选字幕中的覆盖率,并归一化为每100词的关键点数,以量化信息有效率;风格评估使用0-4分细粒度评分准则,基于语义相似性、幻觉严重度和风格一致性,减少LLM评估的方差和偏置。
实验
实验设置聚焦于验证ACM的性能提升、泛化性和下游效用。训练数据来源于ACD数据集,使用AdamW优化器进行3个epoch训练,学习率为1×10^{-6},余弦调度(0.03预热比例),权重衰减0.01,全局批次大小256,采用bfloat16混合精度;模态骨干冻结,仅更新ACM内部组件。模型变体包括ACM-2B和ACM-8B,使用32张NVIDIA A100 (80GB) GPU,训练时长分别为6小时和21小时。 评估基准包括AnyCapEval(内容用KPD,风格用0-4分)、MIA-Bench(多指令图像字幕)、VidCapBench(视频字幕,指标如准确性、精确性、覆盖率和简洁性)和AudioCaps/Clotho(音频字幕,指标如SPICE和Sentence-BERT)。基线模型涵盖专有模型(如GPT-4o)和开源模型(如InternVL2.5-8B、Qwen2.5-VL-7B)。消融实验比较SFT、DPO和自评方法,并探索数据比例(如(q, a, c) vs. (q, c, c))的影响。下游实验评估ACM在视频生成(如Wan2.1-T2V)和图像生成中的效用,使用指标如视觉质量和事实一致性。
结果

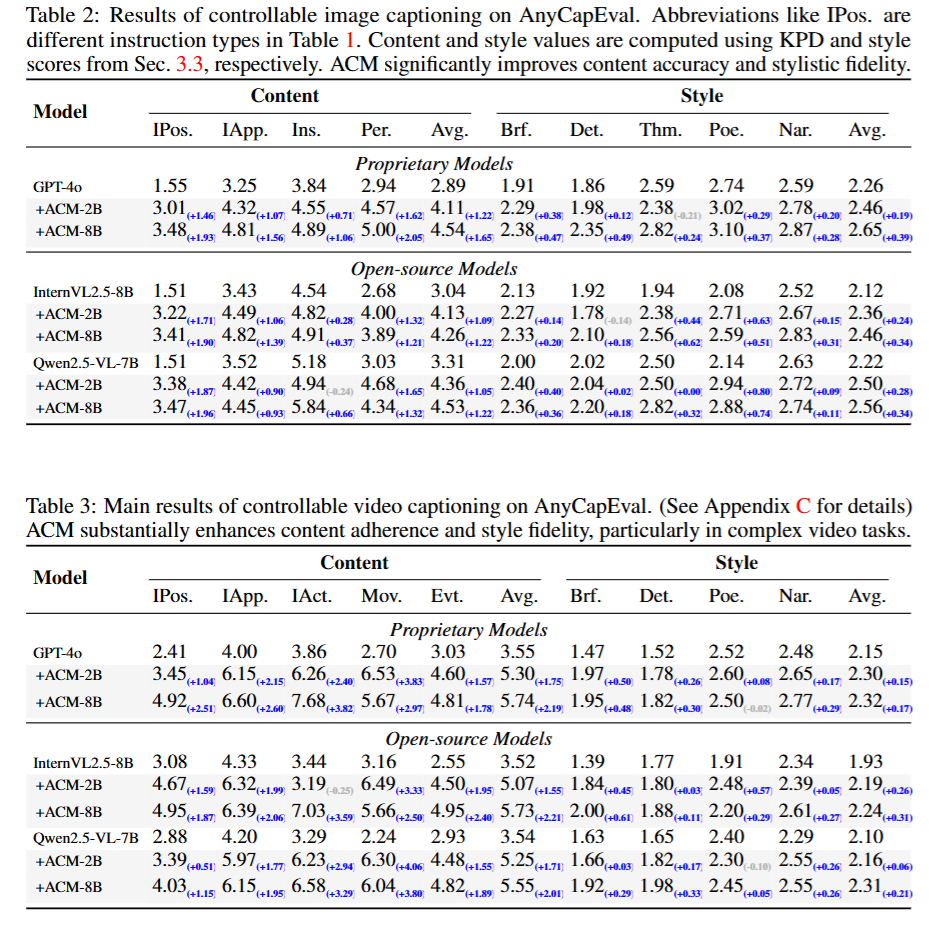
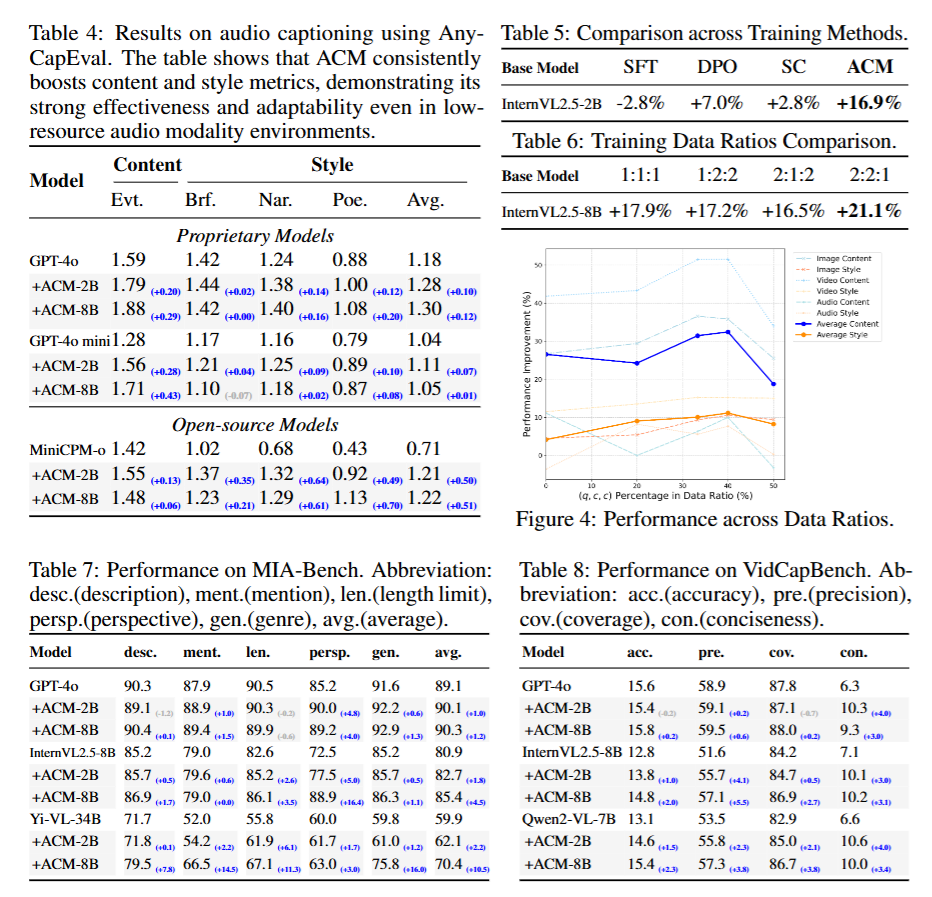
实验结果显示,ACM显著提升了全模态字幕的可控性。在AnyCapEval上,ACM-8B将GPT-4o的内容分数提升45%(从2.89到4.54),风格分数提升12%(从2.26到2.65);开源模型如InternVL2.5-8B的内容平均提升1.22,风格提升0.34,甚至超越未增强的GPT-4o。视频模态提升更显著(如动作控制提升3.59),音频模态虽资源有限但内容提升0.29。公共基准上,ACM改善MIA-Bench平均分数1.0-10.5(视角控制提升16.4%),VidCapBench精确性提升5.5,AudioCaps/Clotho SB分数提升0.04。 消融实验表明,ACM优于SFT (+16.9% vs. -2.8%)和DPO (+7.0%),无需模型特定训练;数据比例实验显示,(q, c, c)比例为40%时性能最佳(>50%导致下降),适度次优数据提升对指令偏差的敏感性。下游应用中,ACM精炼字幕提升视频生成平均分数0.36-0.59,改善视觉-语义对齐。分析显示,内容提升大于风格(因学习信号更明确),视觉任务优于音频(因预训练密度更高);少数回归归因于多维优化权衡。总体而言,ACM在控制性和幻觉减少方面表现出色,验证了其鲁棒性和实用性。
总结
本论文通过AnyCap项目,提供了一个统一的解决方案,解决了可控全模态字幕生成的框架、数据和评估挑战。其贡献包括轻量级ACM框架、大规模ACD数据集和可靠AnyCapEval基准,在实验中证明了显著性能提升和下游效用。该工作为多模态模型的精确控制铺平道路,但局限性在于对新兴模态(如3D结构)的扩展依赖高质量数据,且需防范数据滥用风险。未来可探索更多模态扩展和伦理保障,以进一步增强其影响力。