⭐ [ICLR 2025] ChartMimic: Evaluating LMM’s Cross-Modal Reasoning Capability via Chart-to-Code Generation
Published in ICLR, 2025
关键词
- 多模态大模型 / Large Multimodal Models (LMMs)
- 图表理解 / Chart Understanding
- 代码生成 / Code Generation
- 跨模态推理 / Cross-modal Reasoning
- 基准评测 / Benchmark Evaluation
- 可视化 / Visualization
Arxiv地址:https://arxiv.org/abs/2406.09961

背景
随着大规模多模态模型(LMMs)的发展,AI在复杂认知任务(如视觉、语言、代码生成等)上展现出巨大潜力。然而,传统代码生成评测只依赖文本输入,而真实编程往往需要结合视觉信息。尤其是在学术与科研领域,研究者常常需要根据已有的图表快速生成可复现的绘图代码,然而原始代码缺失或专业性不足的问题普遍存在。因此,如何评估和提升LMMs基于视觉输入进行代码生成与推理的能力,成为当前AI研究的重要方向。

方法
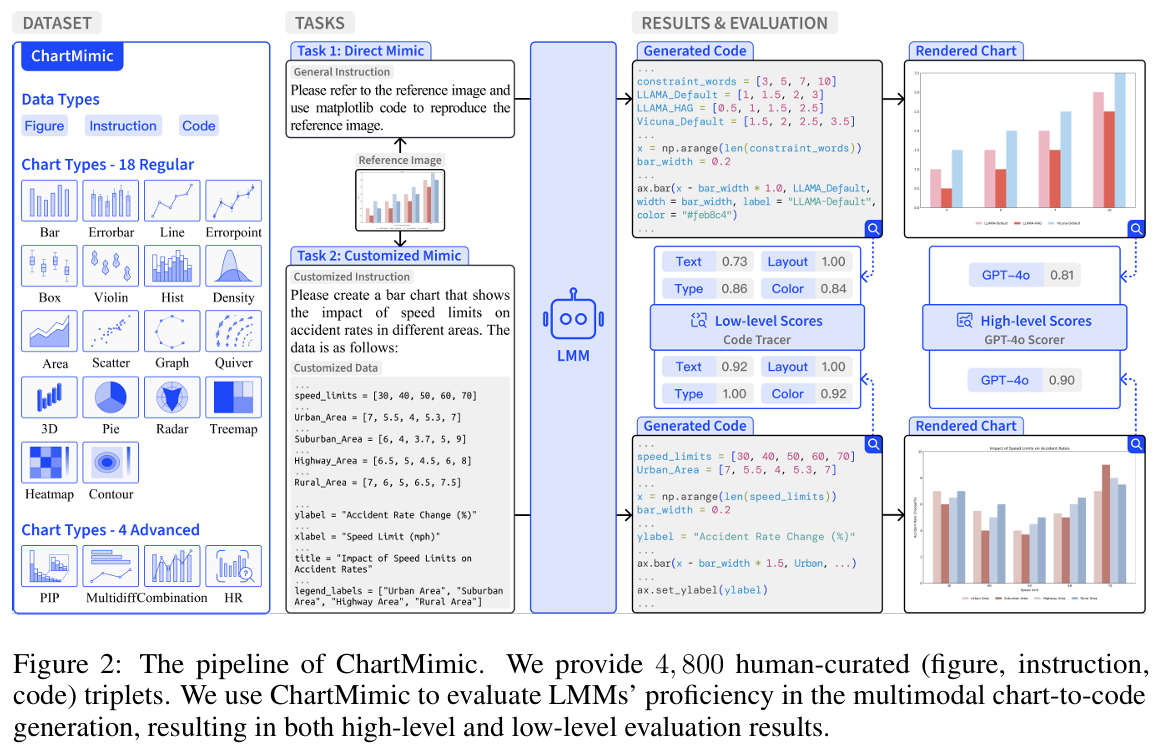
本论文提出了ChartMimic基准,用于系统评估LMM的图表理解与代码生成能力。其主要方法包括:
- 任务设定:
- Direct Mimic:模型需根据输入图表和指令,生成能够复现原图的代码,考察其视觉理解与推理能力。
- Customized Mimic:模型需根据图表、定制化指令和新数据,生成保持原图美学和设计风格的新代码,考察其跨模态综合能力。
- 数据集构建:
- 收集和筛选来自arXiv等科学论文的图表,以及Matplotlib Gallery、Stack Overflow等平台的图表,涵盖22类、201个子类别。
- 人工标注4,800组“图表-指令-代码”三元组,涵盖物理、计算机、经济等多个学科领域。
- 数据样本包括多种复杂度(易/中/难),保证数据多样性和真实性。
- 多级自动化评测指标:
- 高层指标:用GPT-4o为代表的大模型对生成图与真值图的整体相似度评分(0-100分)。
- 低层指标:量化对图中文本、布局、类型、颜色等元素的还原度(通过F1分数)。
- 总分:高层与低层分均值,自动衡量模型整体表现。
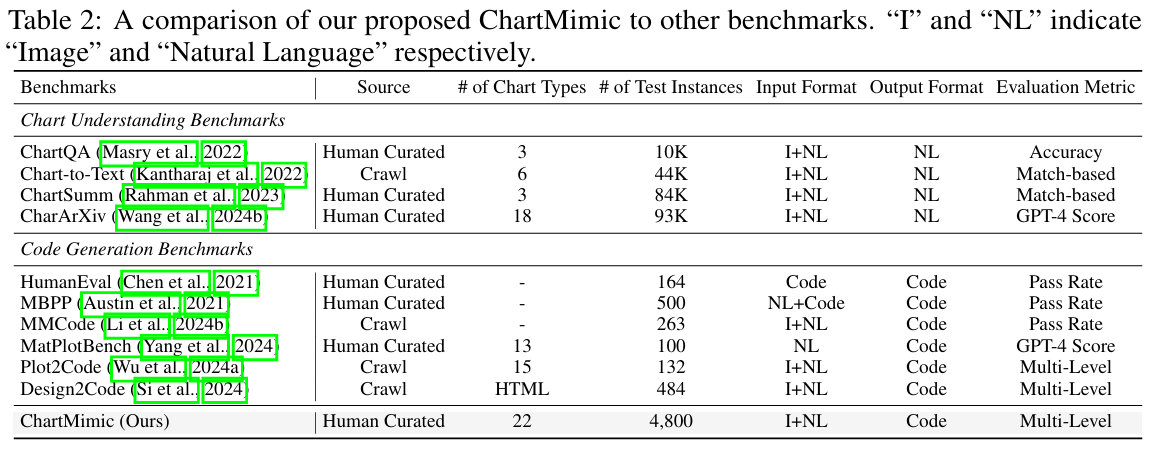
实验
- 模型评测:基准覆盖17个主流LMMs(包括GPT-4o、Claude-3-opus、GeminiProVision等商用模型,以及InternVL2-Llama3-76B、Phi-3-Vision等开源模型),参数规模从2.2B到76B。
- 任务流程:
- 输入图表和任务指令。
- LMM生成代码。
- 执行代码,渲染生成图表。
- 用多级自动化指标与人工打分比对结果。
- 分组与难度:测试集共4,800例,分为test和testmini(便于快速验证),并按类型和难度均衡分布。
结果
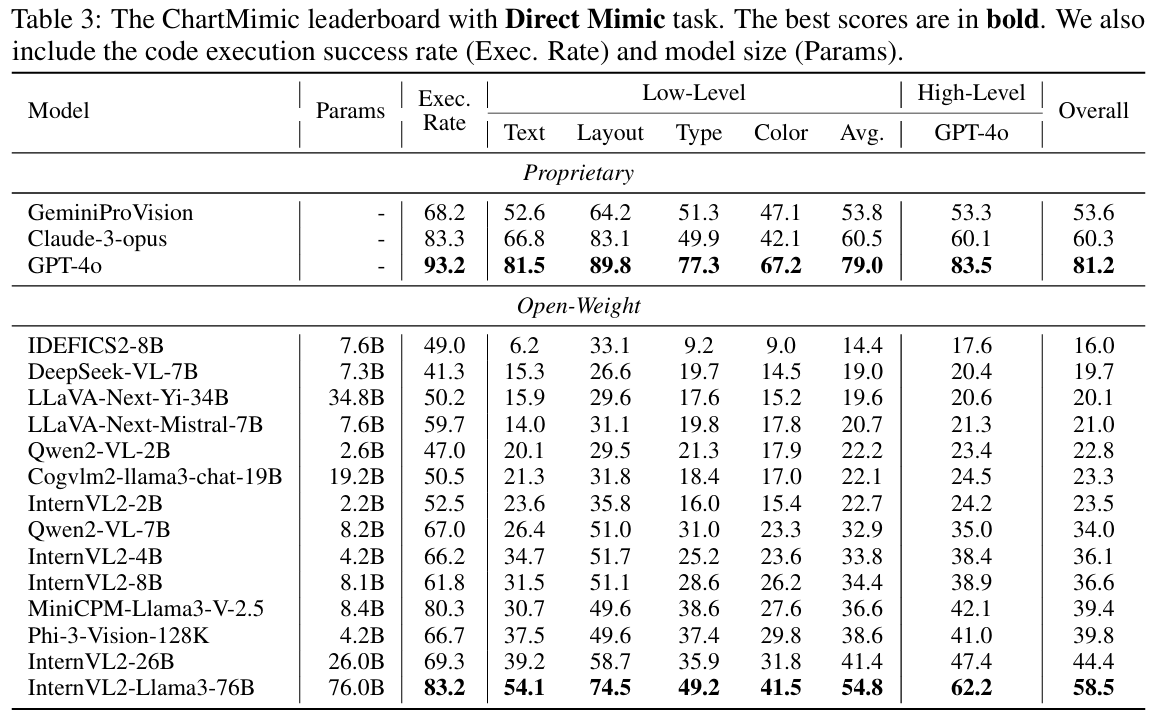
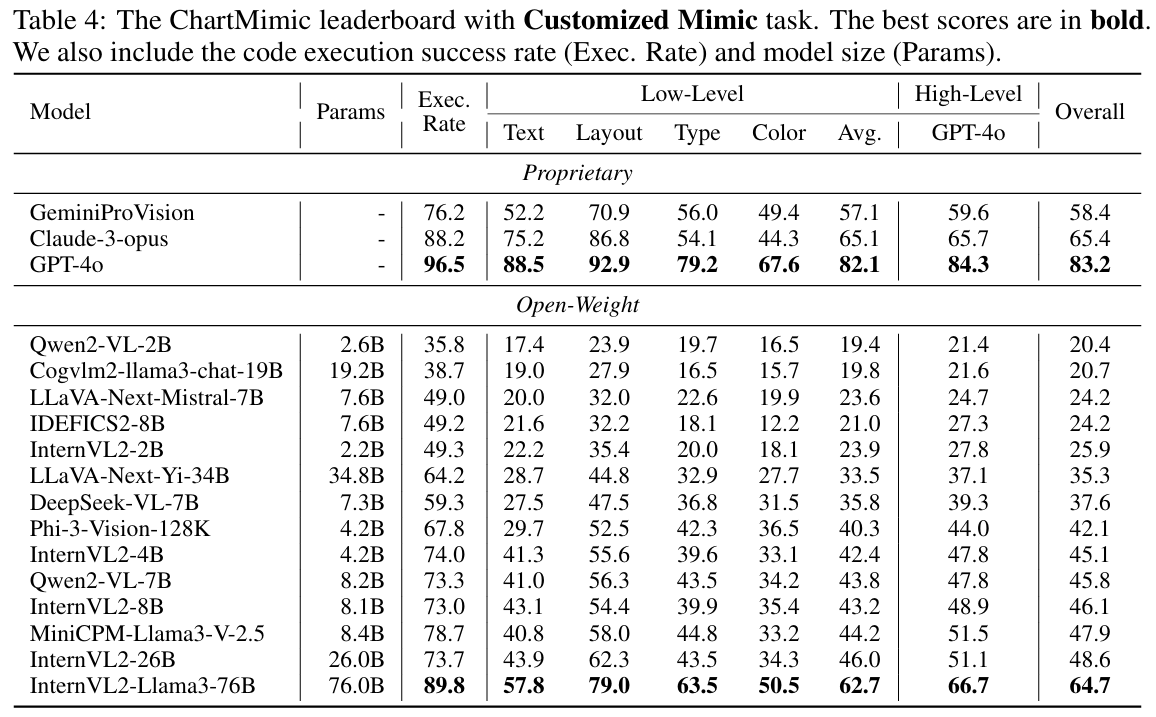
- 模型表现:
- GPT-4o等商用模型表现最佳,Direct Mimic与Customized Mimic任务总分分别为81.2和83.2分。
- 最强开源模型InternVL2-Llama3-76B,得分分别为58.5和64.7,仍与GPT-4o有较大差距。
- 低参数模型(如Phi-3-Vision-128K)在优化训练下也可获得有竞争力的成绩。
- Open-weight模型在代码可执行性和视觉理解上仍有提升空间,多数执行成功率低于75%。
- 影响因素与分析:
- 难度提升(从easy到hard)显著降低所有模型的得分。
- 定制化数据(Customized Mimic)能提升弱模型的易任务表现,但复杂任务仍需更强推理与生成能力。
- 不同提示(prompting)策略如Self-Reflection能有效提升强模型表现,反映了“系统2”推理的重要性。
- 误差分析显示,当前LMM易在数据维度、文本理解、图类型识别及颜色还原等方面出现问题,尤其是信息密集型图表。
- 多级评测指标与人工打分高度相关,验证了评测方法的有效性。

总结
ChartMimic为LMMs跨模态推理和代码生成能力的系统性评测提供了新基准。其高密度、多样化的数据集与细粒度、多层次的自动化评测指标,有效推动了AI模型在真实科研场景下的能力提升。当前,开源模型与顶级商用模型仍存在显著差距,主要体现在复杂图表的视觉理解、推理和代码生成能力上。未来研究可探索更高效的提示策略和数据增强方式,进一步缩小开源与闭源模型之间的差距,助力通用人工智能的发展。