⭐ [SIGIR-AP 2024 最佳论文提名] Data-Efficient Massive Tool Retrieval: A Reinforcement Learning Approach for Query-Tool Alignment with Language Models
Published in SIGIR-AP, 2024
关键词
- Massive Tool Retrieval (MTR)
- Query‑Tool Alignment (QTA)
- MTRB 基准 (Massive Tool Retrieval Benchmark)
- Direct Preference Optimization (DPO)
- 低资源学习(Data‑Efficient)
- Sufficiency@k 指标
Arxiv地址:https://arxiv.org/abs/2410.03212
SIGIR-AP 2024:https://dl.acm.org/doi/10.1145/3673791.3698429
SIGIR-AP 2024 Best Paper Shortlisted Nominees: https://www.sigir-ap.org/sigir-ap-2024/bestpapers/
背景
随着大规模工具库的出现,如何从海量工具中检索出与用户查询相关的工具成为一种关键挑战。当前 LLMs(如 LLaMA‑2)无法直接处理数千工具的输入,因为上下文长超出限制。为此,需引入 预检索 机制,提前过滤出适合工具,即所谓的 Massive Tool Retrieval (MTR) 任务。
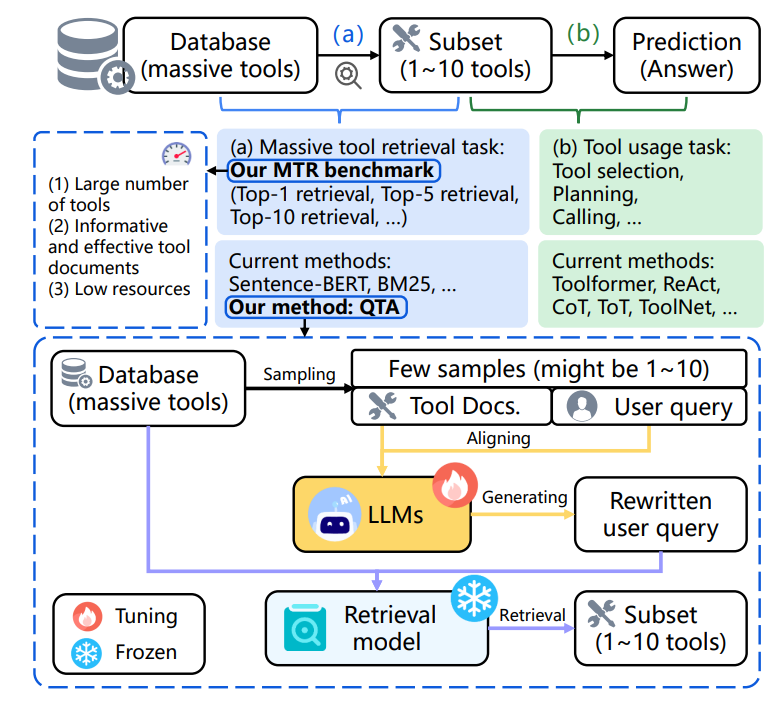
方法
论文提出了一种 Query‑Tool Alignment (QTA) 框架以提升检索效率:
1. 构建 MTRB 基准
- 整合 RestBench、MetaTool、ToolBench 数据集,覆盖数十到数千种工具及其说明文档
- 形成三个子集,每子集含 10 条训练样本、90 条测试样本,体现低资源场景
2. QTA 框架
- 查询重写:使用 LLM 重写用户原始查询,使其更贴合工具文档
- 检索 + 排序:根据重写后查询对工具文档排序
- Direct Preference Optimization (DPO):一种强化学习方法,通过生成“偏好(chosen)/不偏好(rejected)”样本,训练检索排序模型,减少标注依赖
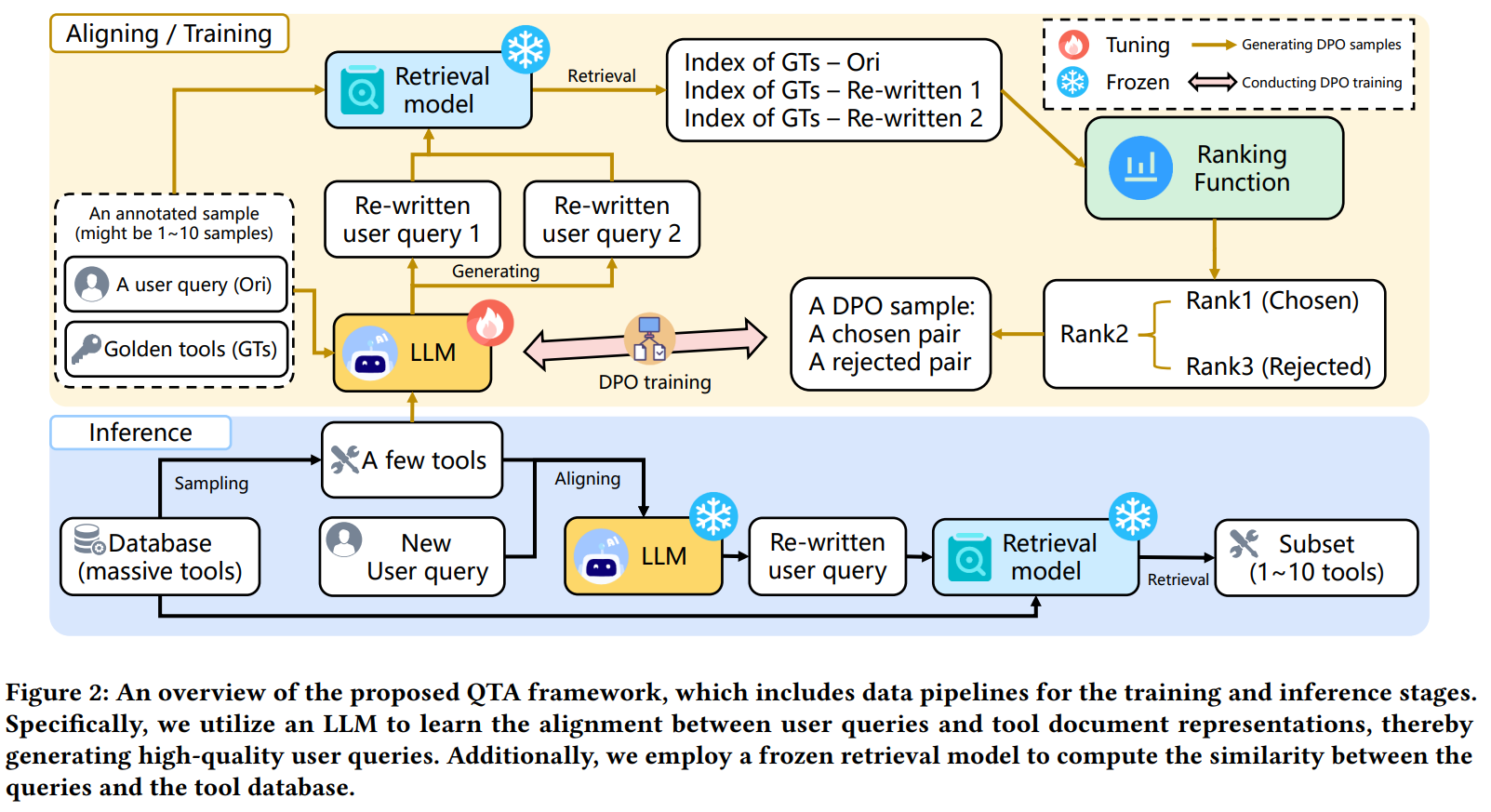
实验设计
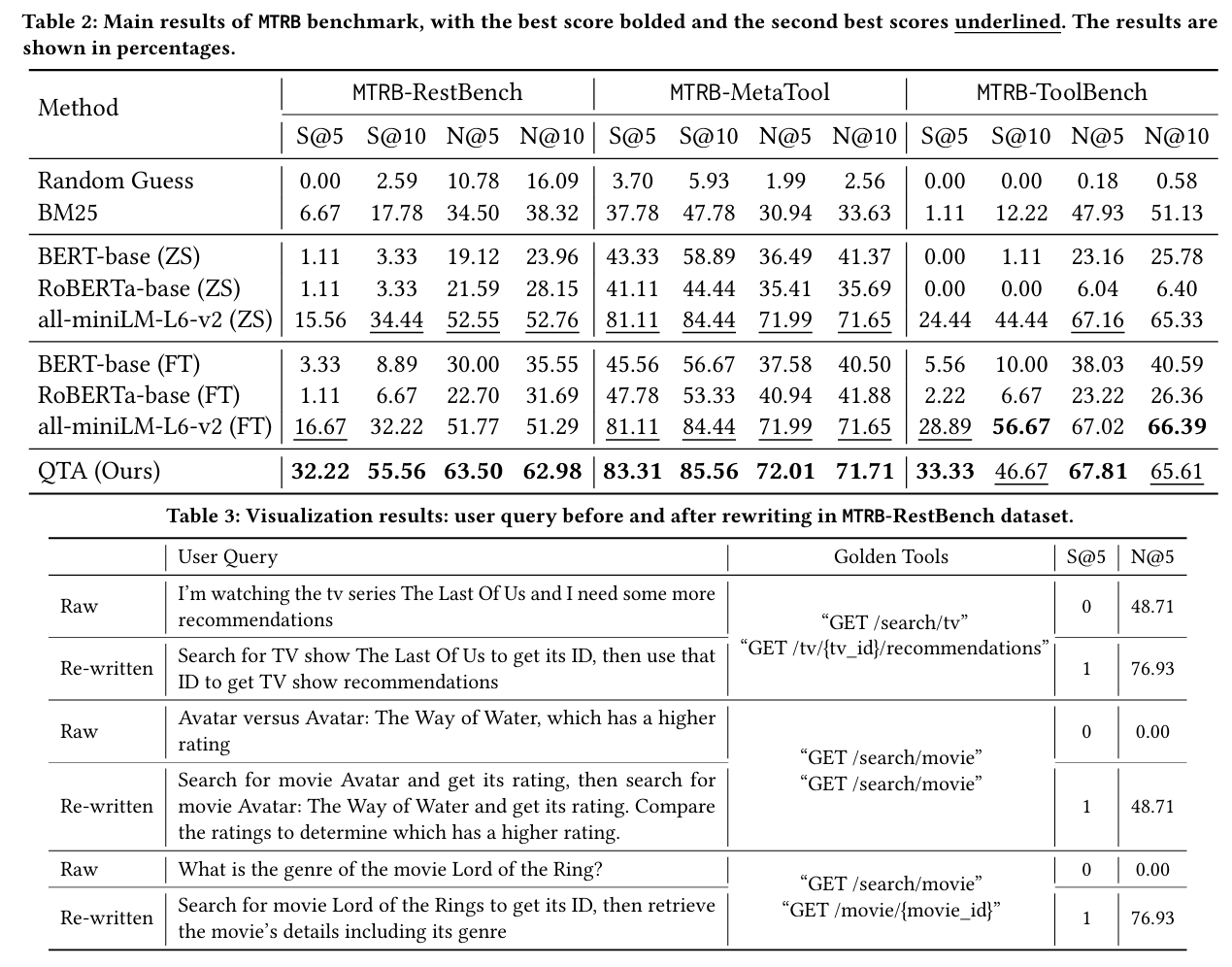
- 任务设置:在三个 MTRB 子集(RestBench、MetaTool、ToolBench)上进行 Top‑k(k=5,10)检索
- 训练样本极少:10 条样本仅用于微调,甚至进行 1‑shot 实验
- 评价指标:
- Recall@k、NDCG@k:传统检索指标
- Sufficiency@k:衡量前 k 个检索结果是否已覆盖所有“金标准”工具
结果
- 在 Top‑5 和 Top‑10 检索中,QTA 相比最先进的方法,Sufficiency@k 指标最高提升 93.28%
- 在极低标注场景(如仅 1‑Shot),仍能实现 78.53% 的 Sufficiency@k 提升
- 交叉子集合泛化表现良好:在一个子集上训练后,迁移到其他子集也表现稳定,体现了强泛化能力
总结
本文针对 “大规模工具检索” 的新兴问题,提出并验证了以下关键贡献:
- 构建了首个 大规模低资源工具检索基准(MTRB)
- 设计了高效的 QTA 框架 结合查询重写与 DPO 强化学习,显著提升检索质量
- 在标注极少的情况下仍展现强性能和跨任务泛化能力
该项研究为未来 LLM+工具生态中的检索模块设计提供了重要指引,尤其在资源有限时仍能通过“偏好学习”实现高效精准检索。