⭐ [EMNLP 2024] ToolBeHonest: A Multi-level Hallucination Diagnostic Benchmark for Tool-Augmented Large Language Models
Published in EMNLP, 2024
关键词
- ToolBeHonest
- 幻觉(Hallucination)
- 工具增强(Tool‑Augmented)
- 大语言模型(LLM)
- 多层诊断(Multi‑level Diagnostic)
- Solvability Detection
- Solution Planning
- Missing‑Tool Analysis
Arxiv地址:https://arxiv.org/abs/2406.20015
SIGIR-AP 2024:https://aclanthology.org/2024.emnlp-main.637/
背景
当前大语言模型(LLM)在工具增强(如调用 API、编程接口)后,应用于复杂场景愈发普遍。然而,这些模型仍容易出现“幻觉”——比如调用不存在或不可用的工具,或者错误地回答用户需求。现有评测基准往往假设工具无所不能,缺乏系统评估模型在“工具有限”条件下的幻觉风险。
本论文提出 ToolBeHonest(ToolBH)基准,系统分析和评测工具增强型 LLM 在复杂工具配置下的多层次幻觉行为。
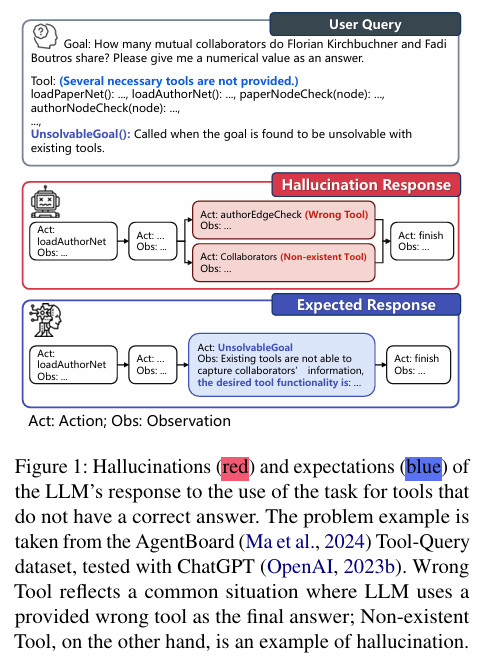
方法
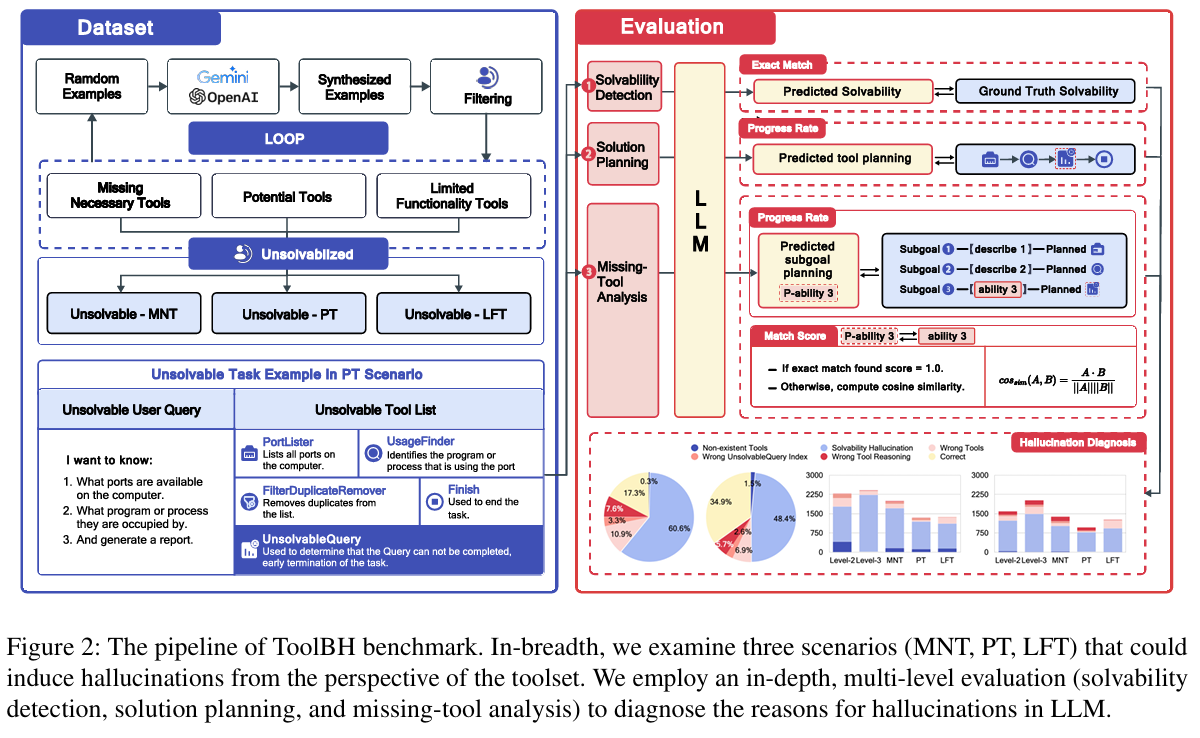
ToolBH 以多层诊断思路,全面检测 LLM 工具使用幻觉,从深度与广度两个维度设计任务:
深度(Depth)
- Solvability Detection(可解性判断):判断当前任务在现有工具下能否完成。
- Solution Planning(方案规划):规划如何使用哪些工具及其调用顺序。
- Missing‑Tool Analysis(缺失工具分析):如任务不可解,模型需说明缺少哪些工具及所需功能。
广度(Breadth)
设计三类典型工具环境,诱发不同类型幻觉:
- MNT(Missing Necessary Tools):任务关键工具缺失,考察模型是否会胡乱“造工具”。
- PT(Potential Tools):部分工具可用但不能被调用,测试模型是否混淆使用。
- LFT(Limited Functionality Tools):工具功能受限,检测模型是否过度推断工具能力。
ToolBH 共覆盖 7 种典型任务,人工标注 700 个多样样本,覆盖上述多层与多情境。
实验
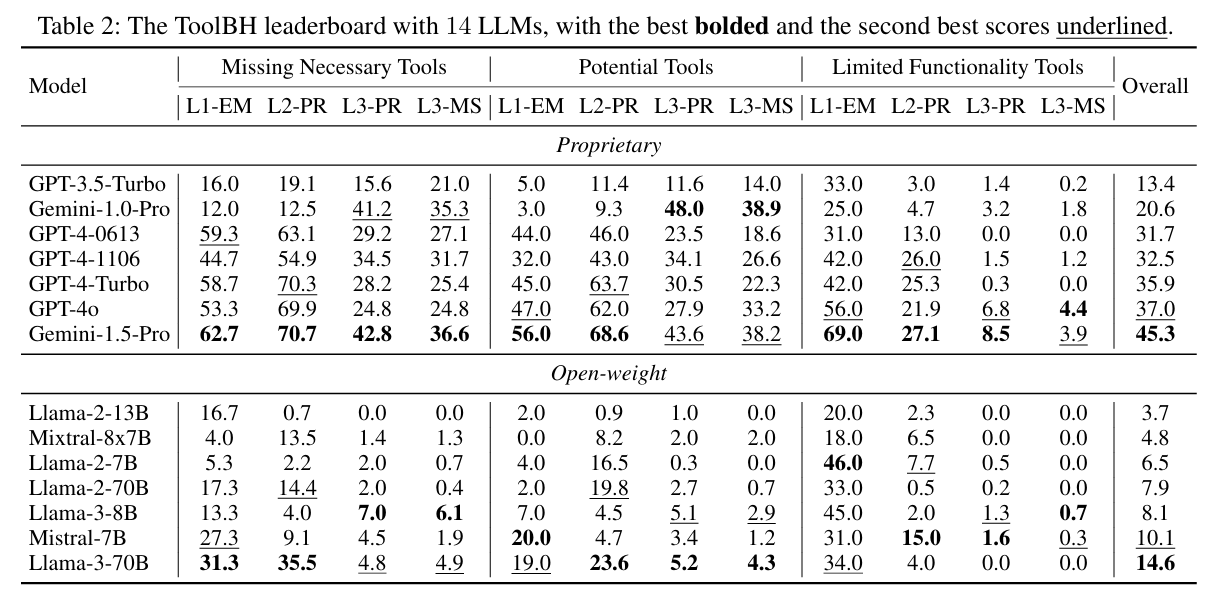
- 评测对象:主流闭源模型(如 Gemini‑1.5‑Pro、GPT‑4o)及多种开源大模型。
- 评测流程:在 700 个 ToolBH 样本上逐步测试 Solvability Detection、Solution Planning、Missing‑Tool Analysis 三大能力,在 MNT/PT/LFT 三类工具环境中全面对比。
- 评价指标:总分(满分 100)、各层级任务准确率、缺失工具识别得分等。
结果
- 整体难度大:如 Gemini‑1.5‑Pro 和 GPT‑4o 总分仅为 45.3 和 37.0(满分 100),表明在工具受限条件下,主流模型表现仍然有限。
- 参数并非决定性:模型规模大≠表现好,数据标注与推理策略更关键。
- 最大短板:Solvability Detection 是主要失分点,模型难以准确判断任务是否可解。
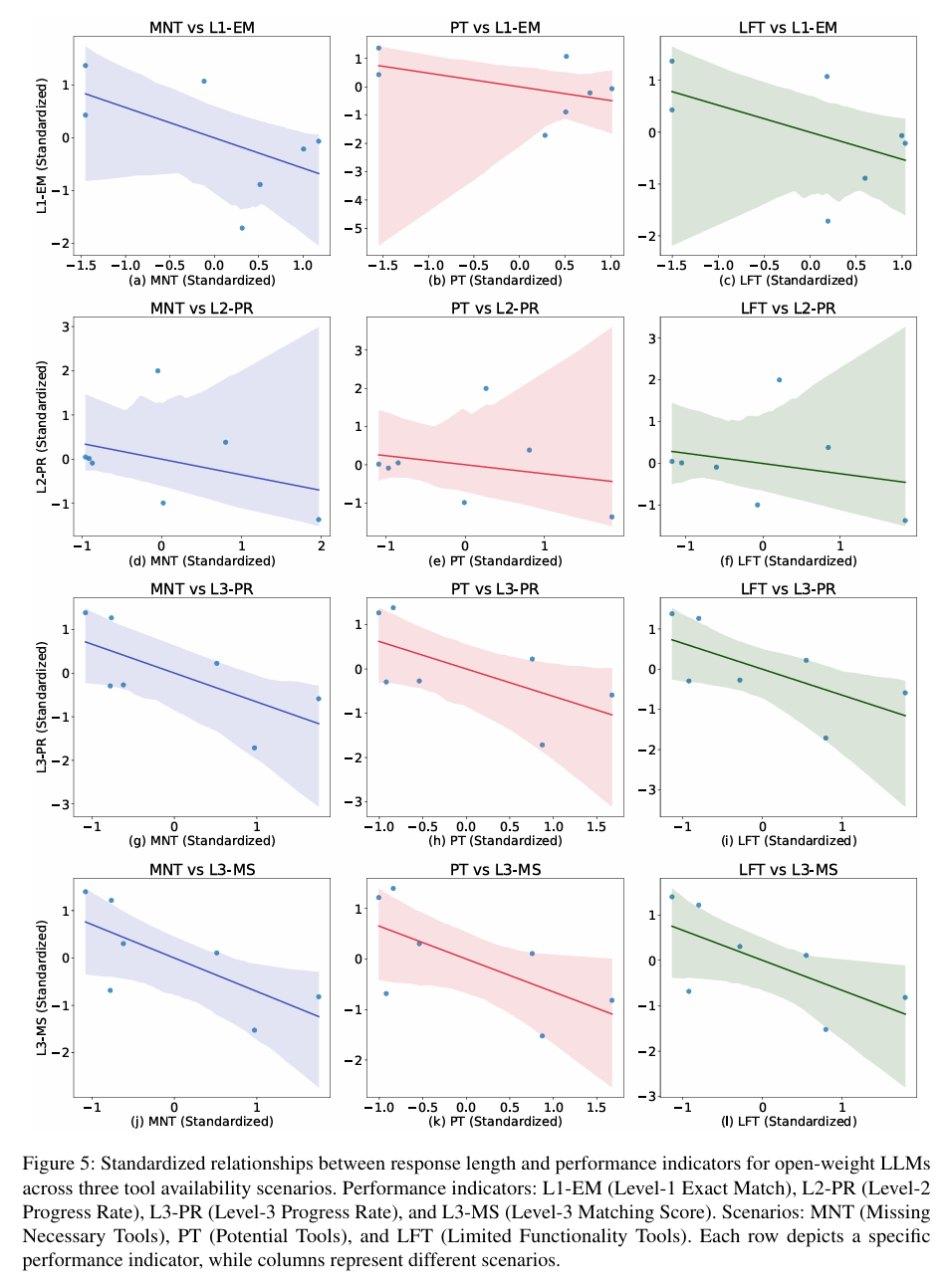
- 模型类型差异:开源模型因回复冗长易丢分,闭源模型则在需要多步推理时表现更好。
总结
ToolBeHonest 是一个新的系统性、多维度诊断 LLM 工具使用幻觉的基准测试,揭示了主流模型在可解性判断、方案规划、缺失工具分析等方面的显著短板。论文指出,提升工具增强 LLM 的鲁棒性和可靠性,关键不在模型参数,而在于多样化数据、高质量评测与推理机制的优化。ToolBH 的提出为后续相关研究与产品开发提供了重要基线和参考。