⭐🚩 PIN: A Knowledge-Intensive Dataset for Paired and Interleaved Multimodal Documents
Published in Arxiv, 2024
关键词 (Keywords):
- 多模态数据集 / Multimodal Datasets
- 大模型预训练 / Large Model Pre-training
- 数据格式 / Data Format
- 知识密集型 / Knowledge-Intensive
- 成对与交错文档 / Paired and Interleaved Documents
论文地址:https://arxiv.org/abs/2406.13923
1. 背景与动机 (Background & Motivation)
- 问题定义: 论文旨在解决当前大型多模态模型 (LMMs) 在处理知识驱动型复杂任务时遇到的两大核心瓶颈:感知错误(Perceptual errors)和推理错误(Reasoning errors)。感知错误体现在难以准确理解专业的图表和表格;推理错误则表现为无法有效推断图文之间的深层关系,尤其是在涉及连续状态的场景中。
- 研究动机: 作者认为,这些错误的根源在于现有主流多模态数据集的局限性。具体而言:
- 图文对 (Image-Text Pairs) 格式: 文本描述通常过于简洁,缺乏上下文深度,无法支持复杂的推理学习。
- 交错文档 (Interleaved Documents) 格式: 虽然图文并茂,但现有数据集(如MMC4, OBELICS)存在数据源单一(多为网页)、缺乏文档全局信息、数据清洗后丢失关键版式和细粒度视觉细节等问题。
- 学术文档数据集: 此前的处理方式(如将每页PDF视为一张图片)会破坏文档的自然连续性,阻碍模型学习跨页的全局知识。
因此,研究界迫切需要一种新型的数据格式和相应的大规模数据集,它应兼具知识密集、可扩展、并能支持多样化训练策略的特点,以推动LMMs在感知和推理能力上的突破。
2. 核心方法 (Core Methodology)


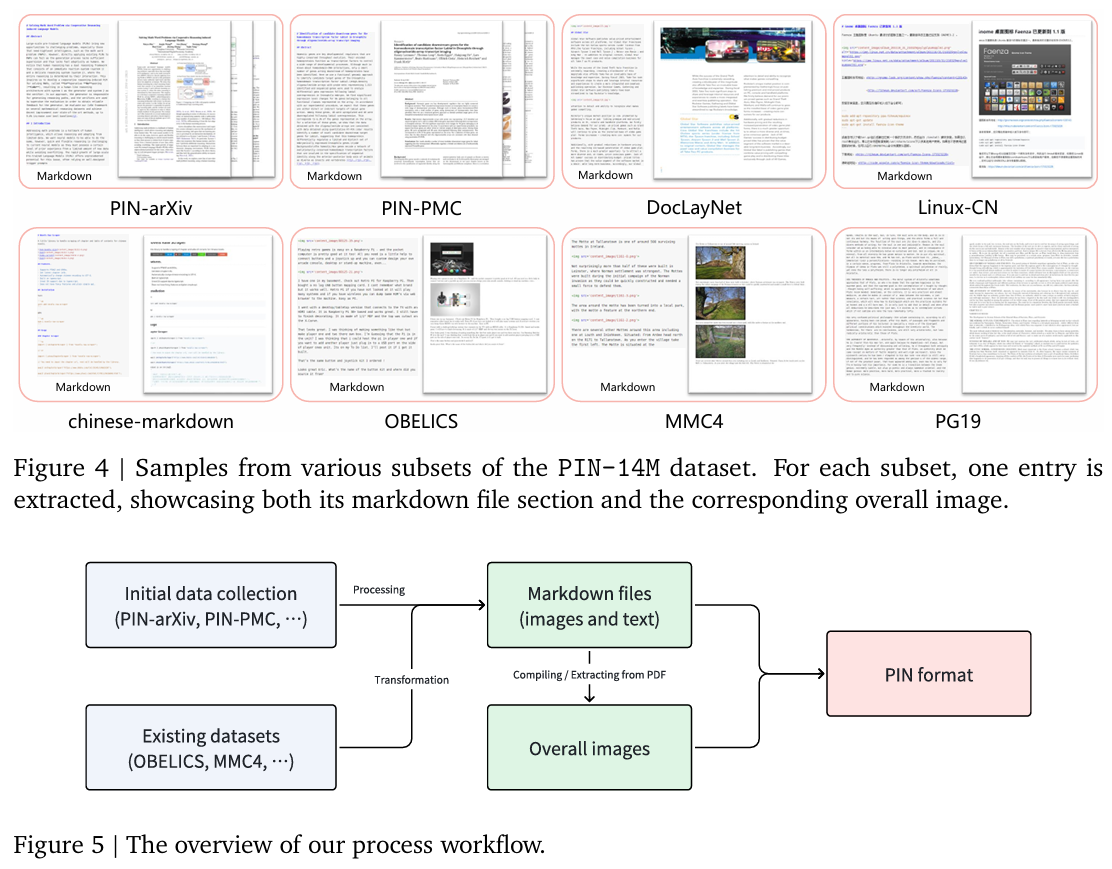
- 整体架构: 论文提出了一个名为 PIN (Paired and INterleaved multimodal documents) 的新型数据格式。其核心架构是一个双组分设计:
- (b.1) 交错的 Markdown 文件 (Interleaved Markdown Files): 这一部分以 Markdown 格式保存了文档的图文交错内容。Markdown 的使用保留了丰富的文本语义结构,如标题、粗体、列表、代码块等,这些都是重要的知识属性。
- (b.2) 配套的整体图像 (Paired Overall Images): 与 Markdown 文件相对应,每个文档都有一个或多个“整体图像”,即源文档(如网页、PDF页面)的完整视觉快照。这为模型提供了全局的版式布局、图文空间关系等高层视觉信息。
- 创新机制: 其最关键的创新点在于 “语义结构”与“视觉全局”的解耦与配对。不同于以往将文档页面“压平”成一张图片的方式,PIN 格式将精细的、结构化的文本知识(Markdown)与宏观的、全局的视觉布局知识(Overall Image)分开存储但又紧密配对。这种设计既避免了细粒度文本信息的丢失,又补充了以往交错文档格式所缺乏的全局上下文,系统性地满足了知识密集、可扩展和支持多样化训练策略三大要求。
- 实现细节: 数据集中的每个条目由一个 JSONL 文件定义,其中包含了元数据 (meta)、质量信号 (quality_signals)、指向内容图片 (content_image) 的路径列表、指向整体图片 (overall_image) 的路径,以及核心的 Markdown 文本 (
md)。这种结构化的组织方式使得数据易于解析、过滤和使用。
3. 实验设计 (Experimental Design)
- 数据集与预处理:
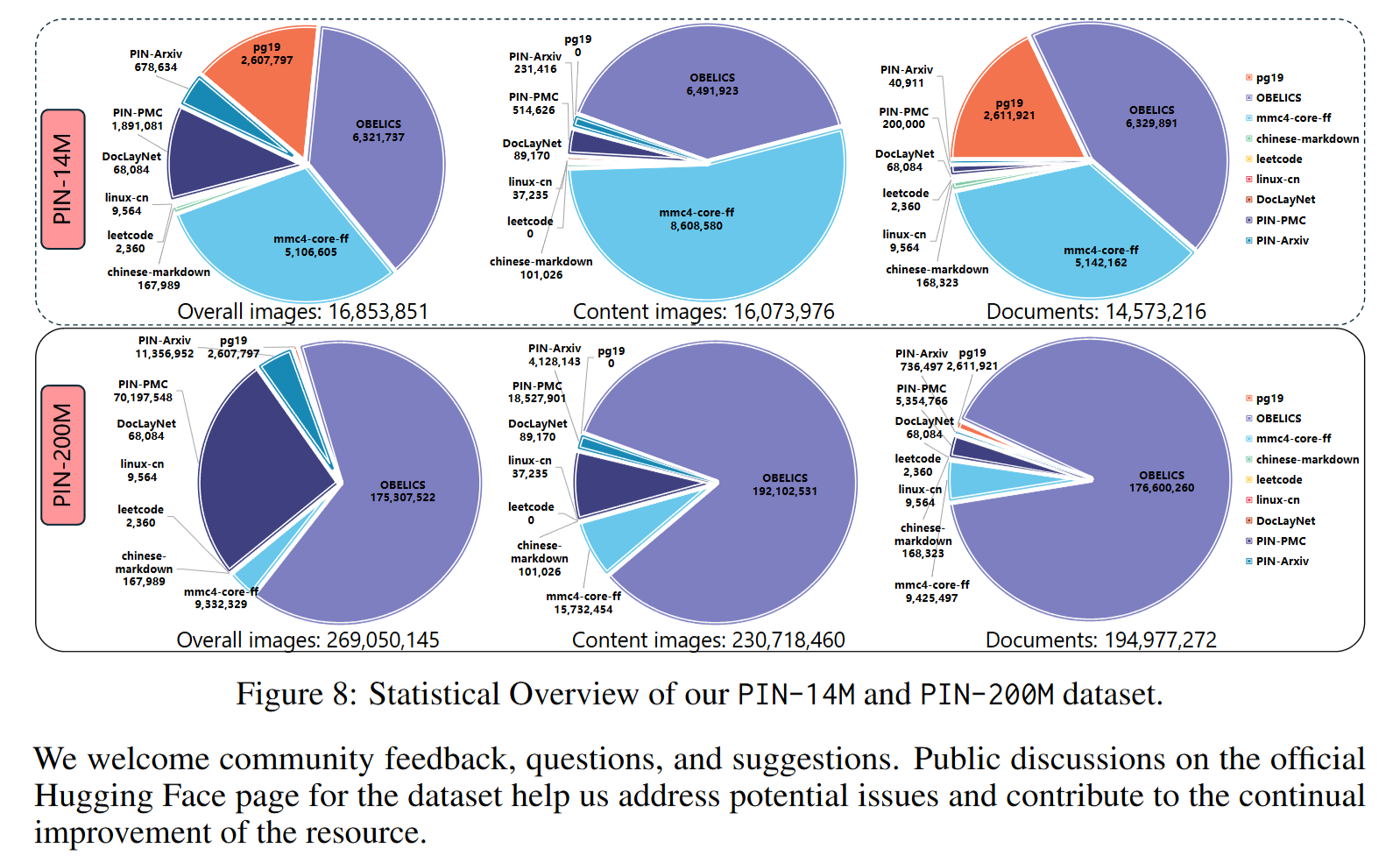
- 论文构建并发布了两个大规模数据集:PIN-14M (~1400万文档) 和 PIN-200M (~2亿文档)。
- 数据源极为多样,涵盖了 natively constructed 的科学文献(PIN-Arxiv, PIN-PMC)和 adapted 的第三方数据集,包括网页(OBELICS, MMC4)、技术社区(Linux-CN)、书籍(PG19)、代码(Leetcode)等中英文内容。
- 预处理流程标准化,包含预处理、内容标准化(统一转为Markdown)、视觉增强(生成”overall image”)和最终封装四个阶段,并针对不同数据源(如PDF、网页、纯文本)定制了具体的工作流。
- 对比模型 (Baselines): 作为一篇数据集报告,本文没有提出新的模型进行性能对比。其“对比”体现在对现有数据格式(如图文对、交错文档)局限性的分析上,并通过提出PIN格式来解决这些局限。
- 评估指标 (Metrics): 论文创新性地引入了 “质量信号 (Quality Signals)” 来评估和量化每个数据条目的特征。关键指标包括:
- 图文交错频率 (ITIF)
- 总词元数 (Total token count)
- 文档长度 (Document length)
- 标记语法统计(如粗体、斜体字符数) 这些指标使得研究者可以轻松地对海量数据进行筛选和二次开发。
4. 实验结果与分析 (Results & Analysis)
- 主要结果:
- 数据统计: 图8清晰展示了PIN-14M和PIN-200M数据集中各个子集的文档数、内容图片数和整体图片数的分布。数据显示,OBELICS子集在PIN-200M中占据主导地位,而PIN-14M的各子集分布则更为均衡。
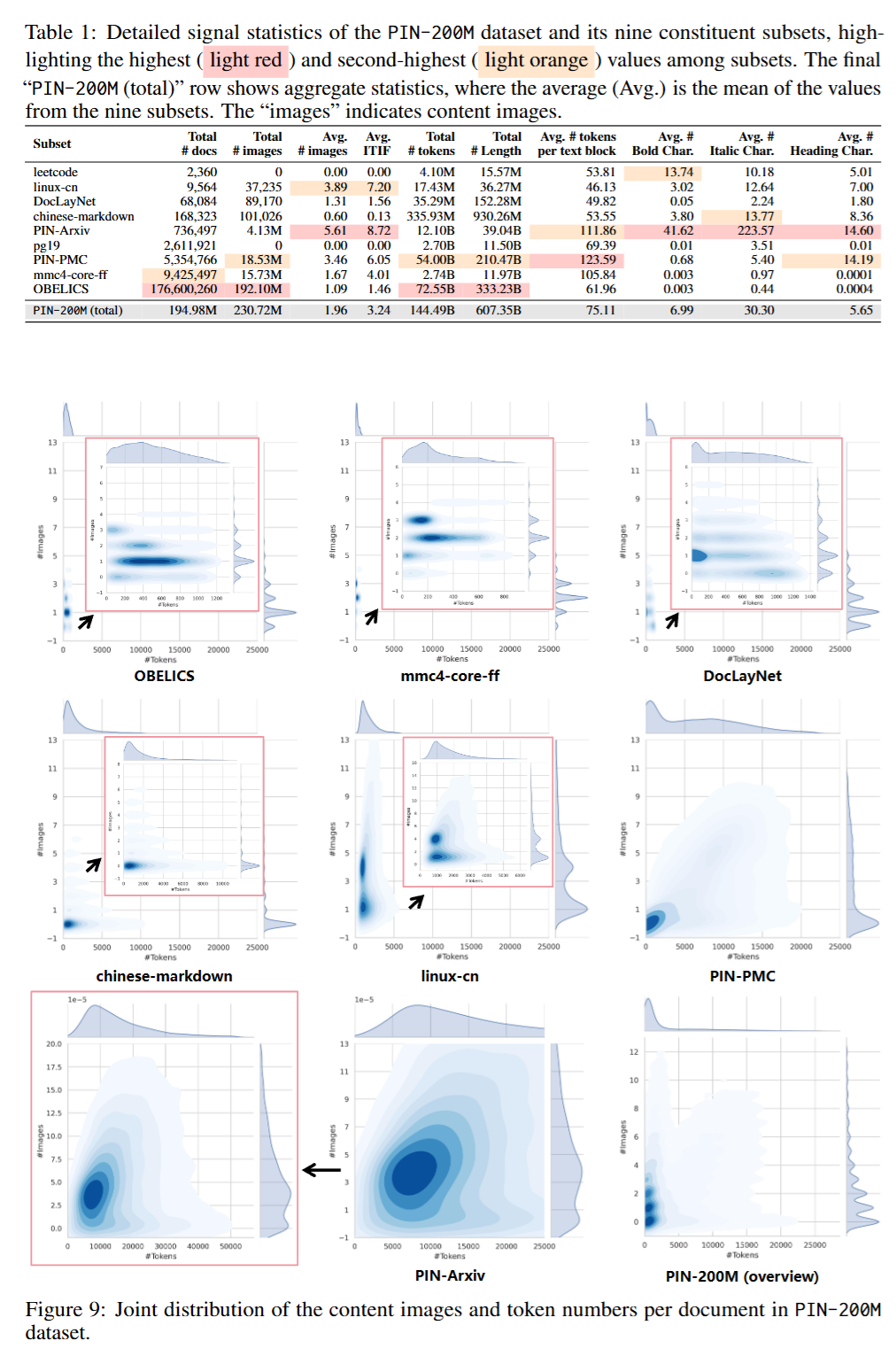
- 质量信号分析: 表1对各子集的质量信号进行了详细统计。PIN-Arxiv子集在平均ITIF、平均加粗/斜体字符数等指标上表现突出,表明其知识密度最高。PIN-PMC虽然知识属性统计值稍低(可能源于XML解析损失),但其平均文本块词元数是所有子集中最高的,文本内容非常丰富。整体来看,PIN-200M数据集平均ITIF为3.24,具有丰富的知识密集属性。
- 消融研究 (Ablation Study): 本文没有传统意义上的模型消融研究。但其对 不同数据来源子集的详细统计分析(表1) 起到了类似的作用。通过对比PIN-Arxiv(学术)、Linux-CN(技术社区)和OBELICS(网页)等子集的信号差异,验证了不同来源的数据对知识密度、图文交错频率等维度的贡献各不相同,从而证明了数据源多样性的重要性。
- 案例分析 (Case Study): 图4直观展示了来自不同子集的数据样本,每个样本都包含Markdown文件部分和对应的整体图像。这清晰地呈现了PIN格式在不同类型文档(学术论文、技术博客、网页)上的应用形态,让读者能快速理解其核心思想。
5. 总结与贡献 (Conclusion & Contribution)
- 总结: 论文成功地提出了一种名为PIN的新型成对与交错数据格式,旨在解决LMMs在感知和推理方面的局限。通过结合保留精细语义的Markdown文件和提供全局上下文的整体图像,PIN格式克服了以往数据表示的缺点。基于此,论文构建并发布了两个大规模、多来源、带质量信号的开源数据集PIN-200M和PIN-14M。
- 核心贡献:
- 提出了一种创新的数据格式 (PIN): 为多模态文档的表示提供了一个兼顾细节与全局、内容与形式的强大范式。
- 发布了两个大规模开源数据集 (PIN-200M, PIN-14M): 极大地丰富了社区可用的高质量、知识密集型多模态预训练资源,支持中英文。
- 引入了质量信号和系统的分析方法: 提高了大规模数据集的可用性和透明度,为未来的数据管理和筛选工作提供了可复现的蓝图。