⭐ [ACM TOIS 2024] SSR: Solving Named Entity Recognition Problems via a Single-stream Reasoner
Published in ACM TOIS, 2024
关键词
- Named Entity Recognition (NER)
- Information Extraction (IE)
- Machine Reading Comprehension (MRC)
- Single-Stream Reasoner (SSR)
- Reasoning Strategy
- Multi-choice Input Format
早期Arxiv地址:https://arxiv.org/abs/2305.03970
ACM TOIS:https://dl.acm.org/doi/10.1145/3655619
背景
命名实体识别(NER)是信息抽取(IE)任务的核心组成部分,目标是将非结构化文本转化为结构化知识,极大提升信息检索(IR)系统的检索和推荐精度。传统NER方法通常基于序列标注,需要大量额外数据,限制了其可持续性和应用范围。近年来将机器阅读理解(MRC)引入NER成为趋势,但现有MRC方法存在预测结果不规范、多流处理低效、缺乏有效推理等挑战。本文希望解决如何在无外部数据依赖的情况下,提升NER任务在多领域、多结构下的鲁棒性与效率。
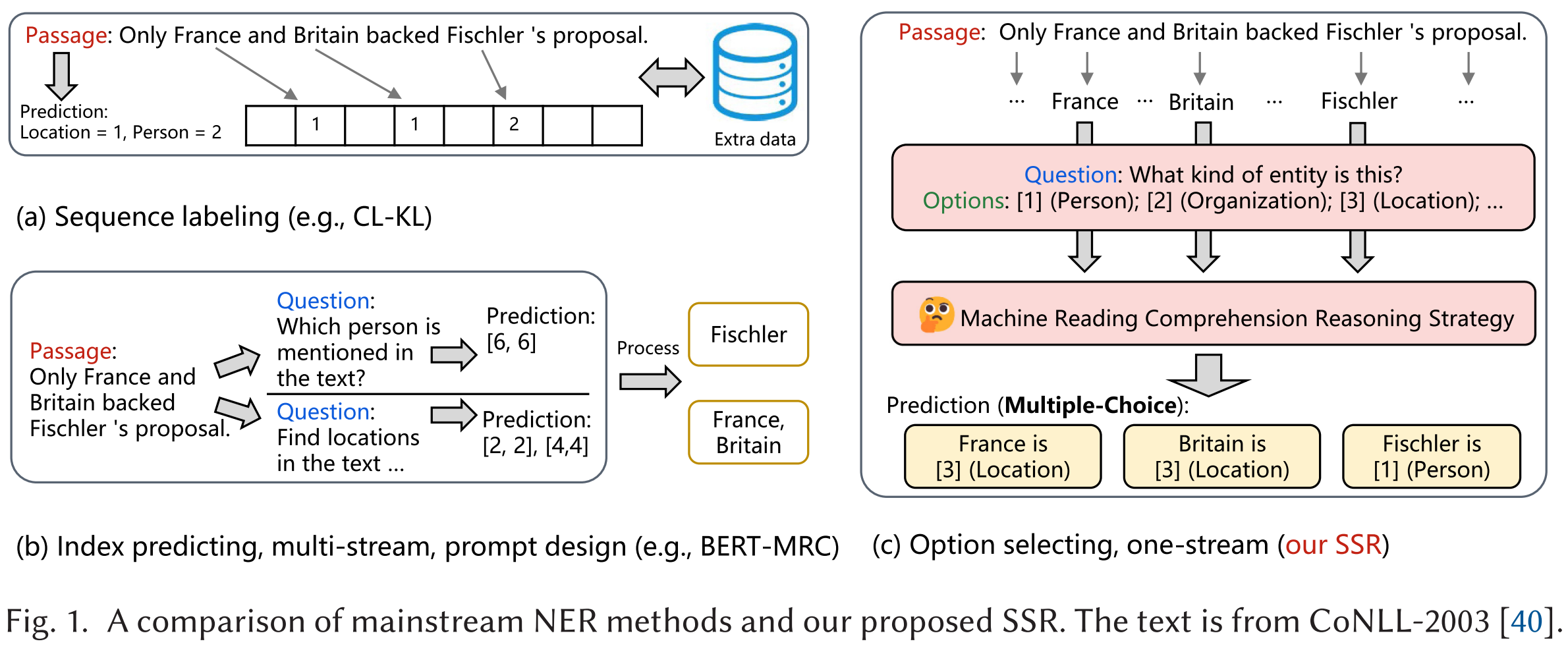
方法
论文提出了Single-Stream Reasoner(SSR)框架,将NER转化为多项选择型MRC任务,具体做法包括:
- 统一输入格式:所有样本均构造成“passage-问题-选项”三元组,问题统一设定为“这是什么类型的实体?”,选项为实体类型详细定义。
- 单流推理:所有实体类型、平坦与嵌套NER在同一流程内推理,避免多流(multi-stream)结构带来的冗余与效率损失。
- 集成推理策略:整合了HRCA、DUMA等先进MRC推理策略,提升复杂文本关系理解能力。
- 完全无外部数据:充分利用数据集本身及注释规则,无需额外标注、检索或增强数据,兼容不同领域和任务类型。

实验
- 数据集:在10个主流NER基准数据集上评测,覆盖社交媒体(WNUT-16/17)、新闻(CoNLL-2003/++、ACE-2004/05)、生物医学(BC5CDR、NCBI、GENIA)、通用(Few-NERD)等多领域。
- 实验流程:全部统一采用SSR框架和多项选择输入格式,无人工prompt工程,主干模型为DeBERTa-v3-large,评价指标为micro-F1,与BERT-MRC、LUKE、Locate&Label、CL-KL等多种SOTA方法全面对比。
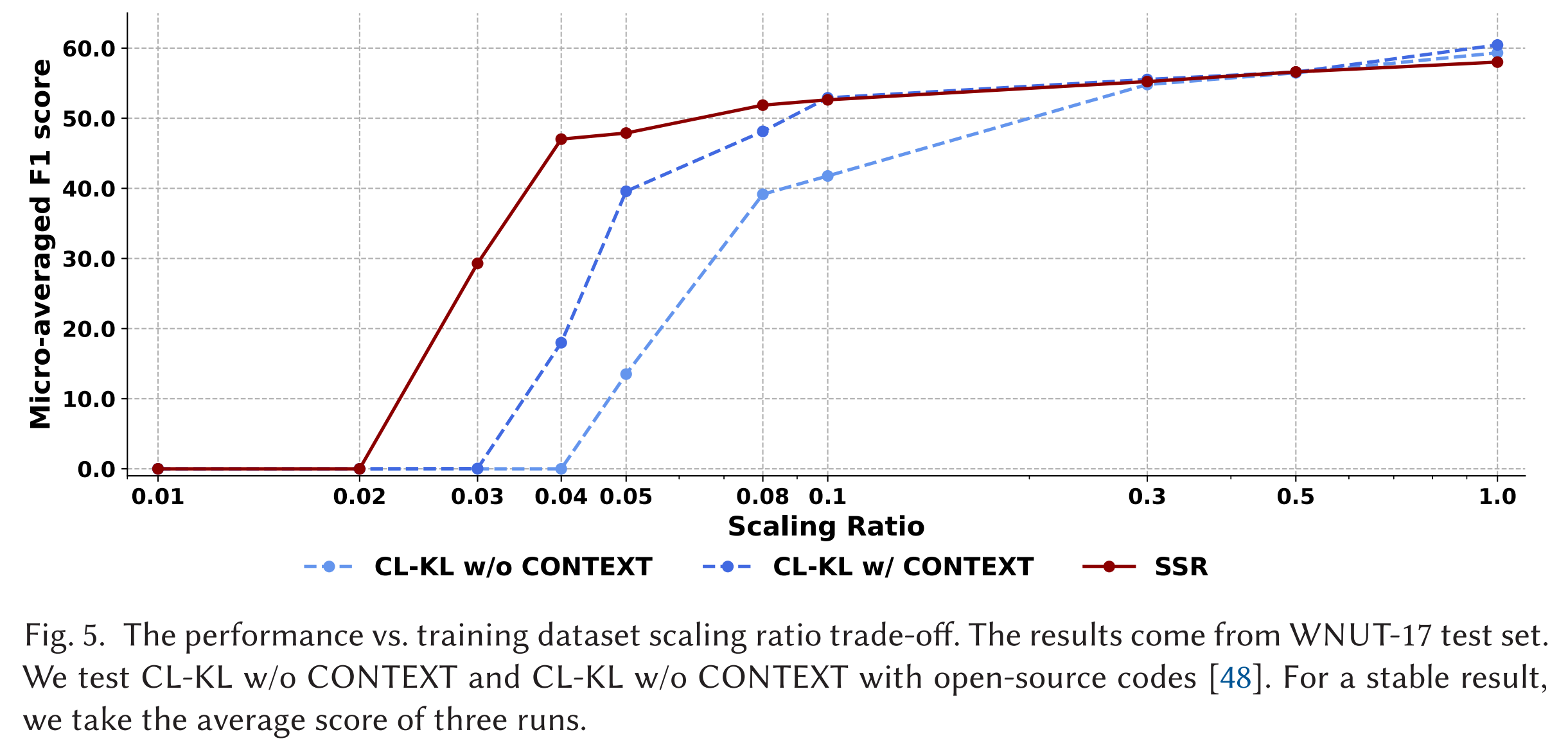
- 低资源实验:系统性评测在小样本条件下的模型鲁棒性。
- 推理/收敛效率:分析SSR与其他主流模型在推理速度和收敛速率上的表现。
结果
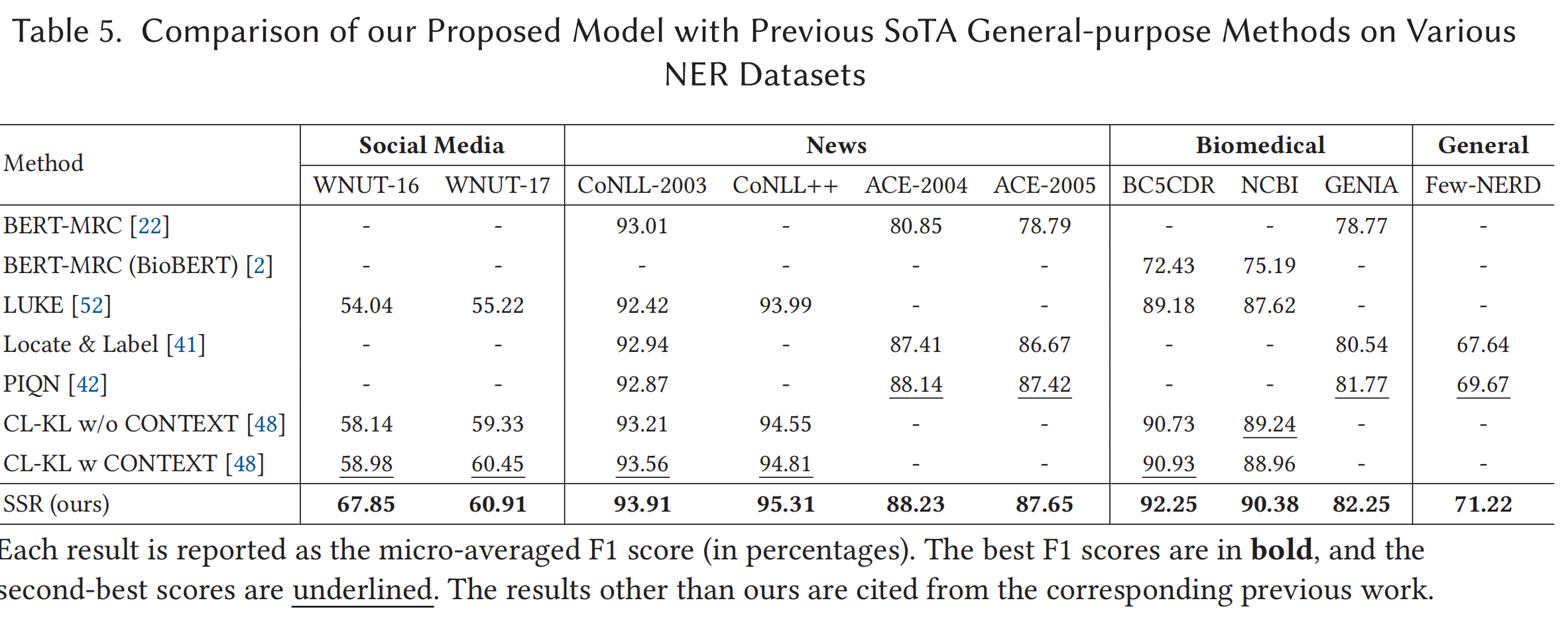
- SOTA性能:SSR在全部10个主流数据集上实现了当前最优(SoTA)F1分数。例如WNUT-16提升超11%,在新闻、生物医学等多领域数据集也大幅领先前代方法。
- 泛化与对比:SSR即使在与ChatGPT(5-shot COT)对比下,也能大幅领先(如CoNLL-2003上SSR为93.91%,ChatGPT仅74.63%)。
- 低资源表现:在极低训练样本比例(如3%)时,SSR仍能提取有价值信息,F1显著高于对比模型,展现了极强鲁棒性。
- 推理速度:SSR采用单流推理显著提升推理效率与模型收敛速度,适合实际大规模与实时应用。
总结
SSR 框架深度融合了NER和MRC,通过统一的多项选择输入格式、单流推理流程和灵活的推理策略,有效克服了传统NER方法在数据依赖与推理效率上的瓶颈,在多领域基准任务上取得了显著性能提升。SSR无需额外数据,兼容多种预训练语言模型和推理算法,具备广泛实际应用和迁移潜力。未来有望拓展到更多信息抽取与自然语言处理任务中。