[COLM 2024] StructLM: Towards Building Generalist Models for Structured Knowledge Grounding
Published in COLM, 2024
关键词
- 结构化知识扎根 / Structured Knowledge Grounding (SKG)
- 指令微调 / Instruction tuning
- 通用模型 / Generalist model
- 表格/图/数据库 / Tables / Graphs / Databases
- 零样本泛化 / Zero-shot generalization
论文地址:https://arxiv.org/abs/2402.16671
背景(Background)
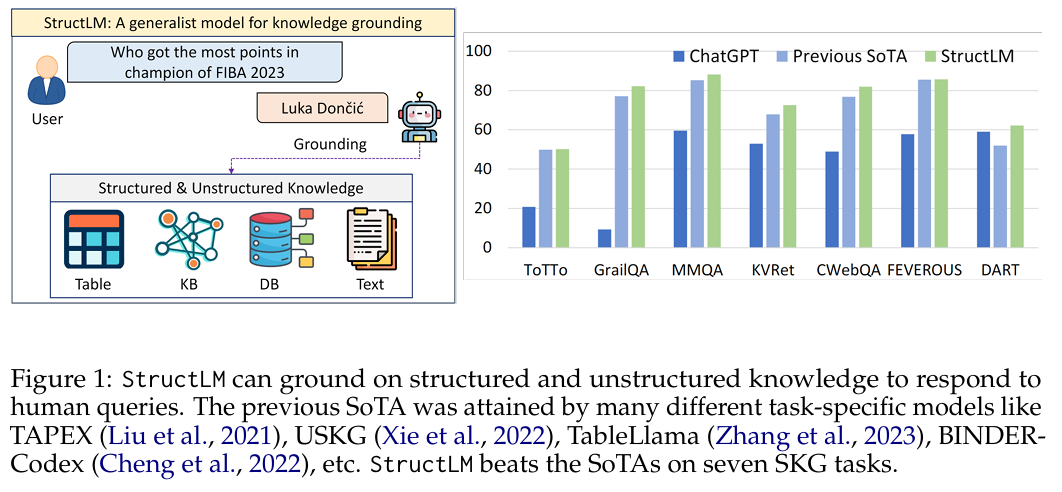
传统大模型在纯文本任务表现出色,但在结构化数据(如表格、知识图谱、数据库)理解与处理方面存在明显不足。作者评估发现,像 GPT‑3.5‑Turbo 在 18 个结构化知识任务上的表现平均落后约 35% 于专门模型。因此,如何让大模型更好地理解和利用结构化数据成为亟待解决的问题。
方法(Method)
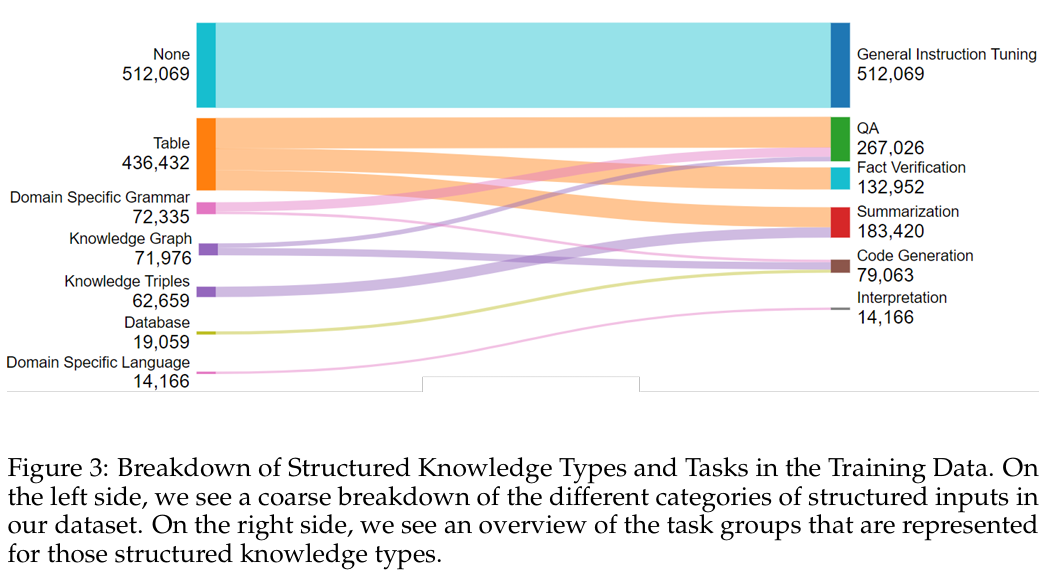
- 大规模 SKG instruction-tuning 数据集:构建了 1.1M 条数据,其中 ~700K 来自 25 个结构化知识任务,余下为通用指令数据。
- 模型选择与微调:基于 CodeLlama-Instruct(7B、13B、34B)和 Mistral 系列进行微调,训练 3 轮,每轮在 16–64 GPUs 上训练约 3–5 天,使用 DeepSpeed ZeRO‑3。
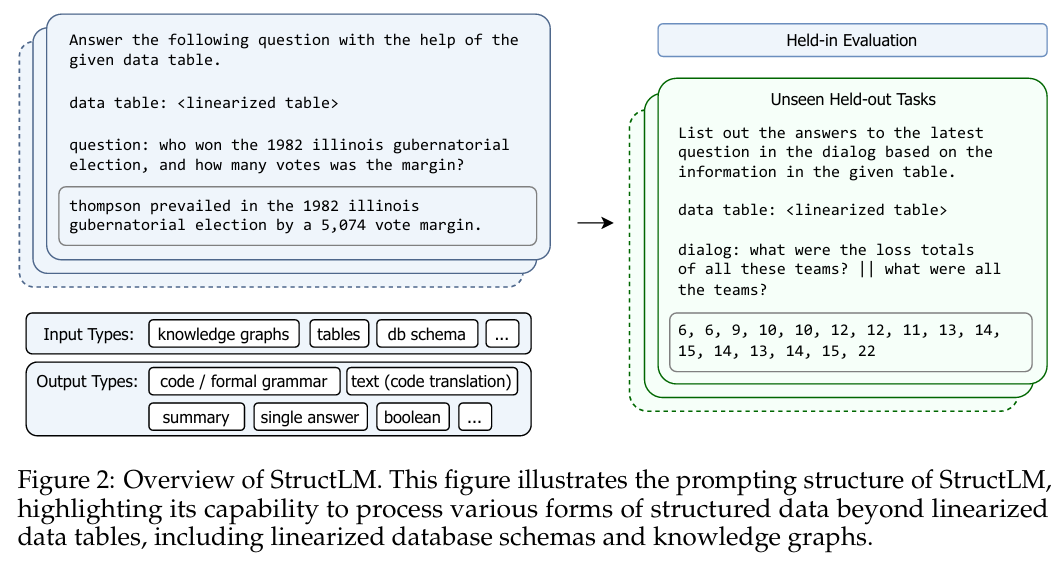
- 线性化输入:将表格、图、数据库架构等结构化数据转为线性字符串供模型处理,遵循 USKG 格式。
实验(Experiments)
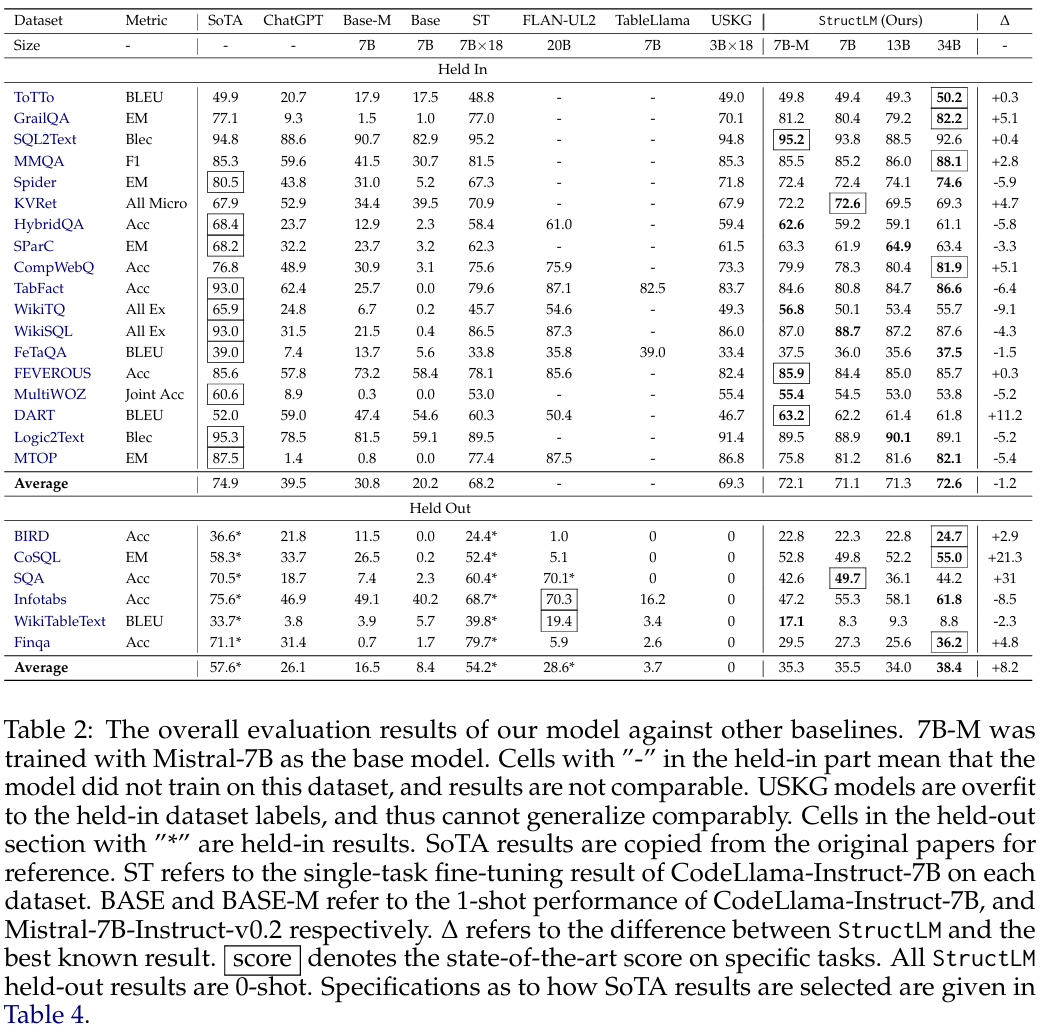
- 评估基线:对比 ChatGPT、CodeLlama‑7B‑Instruct(1-shot)、以及 task-specific 模型(如 USKG、TableLlama、Flan‑UL2)。
- Held-in 任务:18 个训练时见过的 SKG 任务,用于验证模型是否有效学习;
- Held-out 任务:6 个未见过的新任务测试泛化能力。
- 消融合实验:研究基础模型预训练数据(如 code/math)对性能影响,并与单任务模型对比,验证多任务训练优势。
结果(Results)
- Held-in 任务上,StructLM 系列超越 task-specific 模型(在 16 / 18 任务上表现更好),在 8 个任务中创下 SoTA;ChatGPT 平均落后 ~35%。
- Held-out 任务上,在全新的结构任务中,StructLM 平均超过 TableLlama ~35%,高于 Flan‑UL2‑20B 约 10%,ChatGPT 在 5 / 6 上被领先。
- 模型扩容效应弱:从 7B 增至 34B,对性能提升有限,强调结构化知识扎根任务仍具挑战性。
- 预训练类型影响明显:code-pretrain 模型优于仅训练文本或数学模型,进一步增强 SKG 能力。
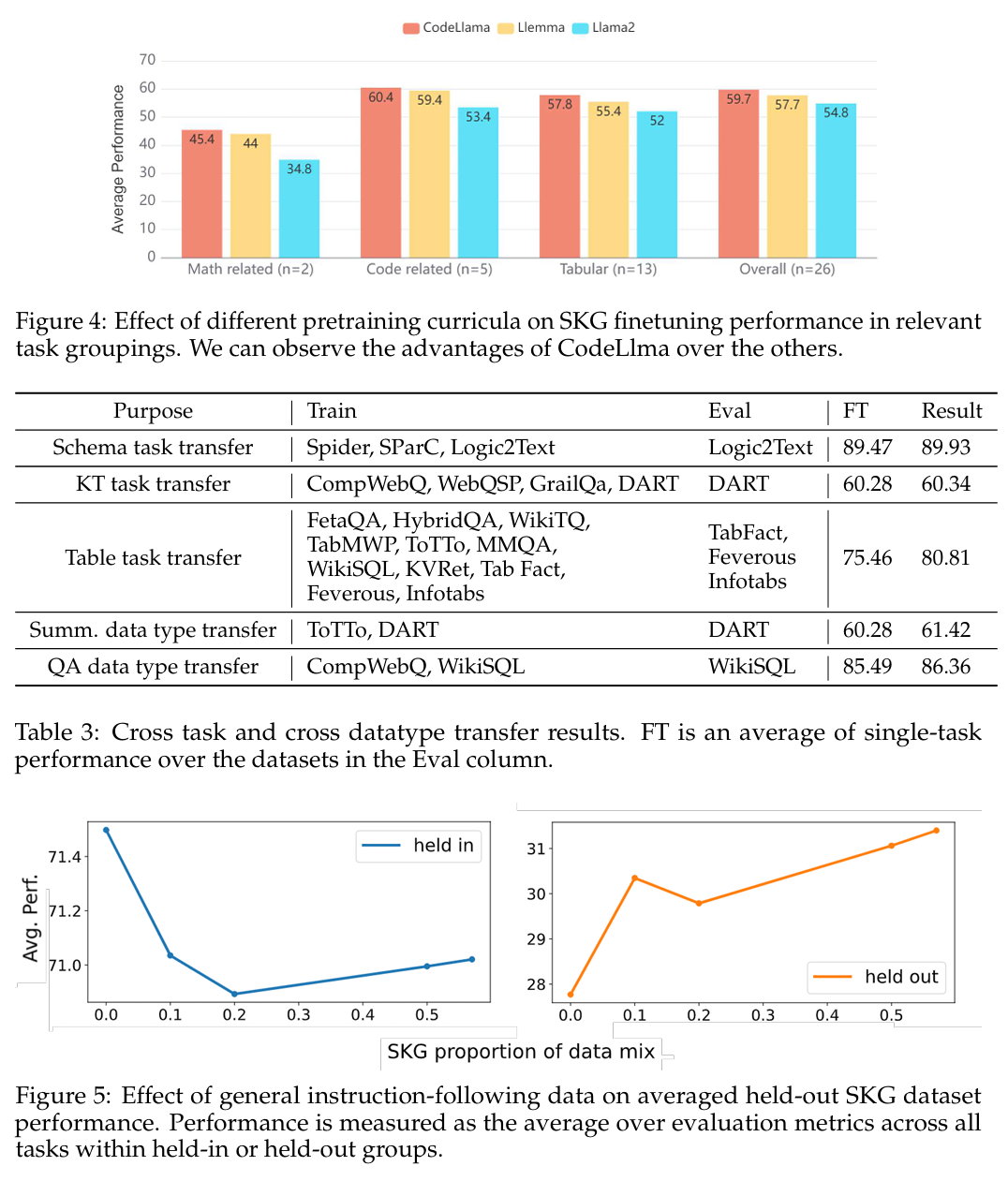
总结(Conclusion)
StructLM 通过大规模 SKG 指令微调构建了一个能处理多种结构化知识的通用模型系列。它不仅在训练集任务上超过当前专门模型,还能很好地泛化到全新结构任务,体现了强大的零样本能力。同时发现:「结构化知识」仍是大模型的一项薄弱领域,未来需更多创新设计。论文团队已公开模型权重、训练数据与代码,推进该领域研究。