CMMMU: A Chinese Massive Multi-discipline Multimodal Understanding Benchmark
Published in Arxiv, 2024
关键词
- 多模态理解 / Multimodal Understanding
- 中文评测基准 / Chinese Benchmark
- 学科知识推理 / Subject Knowledge Reasoning
- 高校考试题 / University Exam Questions
- LMM性能评估 / LMM Performance Evaluation
论文地址:https://arxiv.org/abs/2401.11944
背景
随着大型多模态模型(LMMs)能力的快速发展,评估其在中文语境中进行高级知识和推理能力变得尤为关键。已有的评测如 MMMU 主要集中在英文任务,缺乏对中文多学科图文理解能力的系统测评。CMMMU (Chinese Massive Multi‑discipline Multimodal Understanding benchmark) 应运而生,旨在填补这一空白,对 LMMs 在中文语境下的复杂知识与感知推理能力进行严格测评。

方法
该论文设计并构建了一个覆盖广泛的中文多模态评测集,包括:
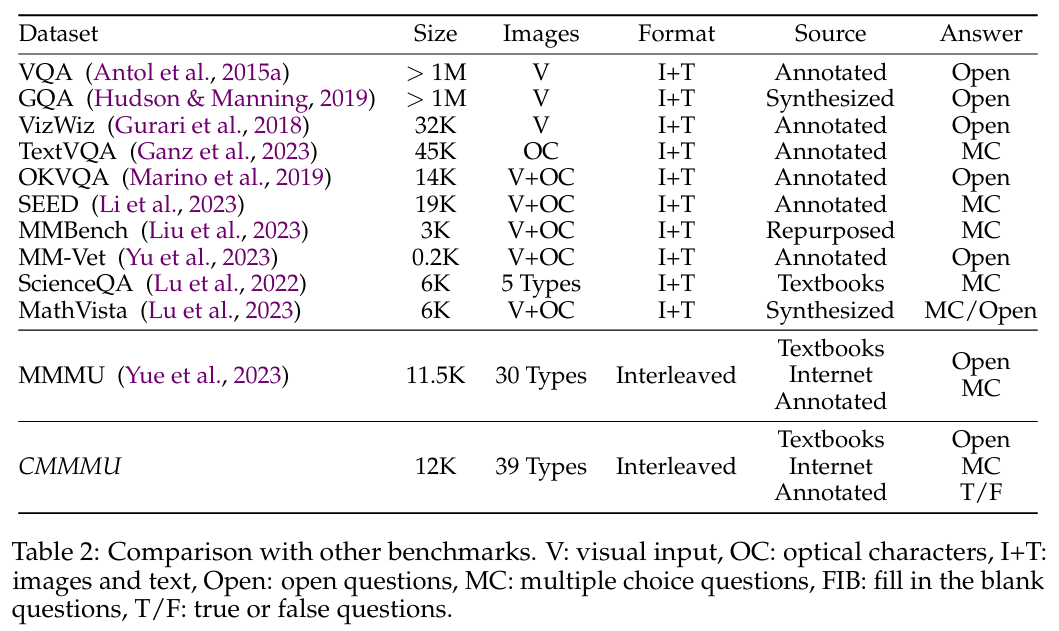
- 题目来源:共计 12,000 道题目,采自中国高校考试、教材与测验,模仿大学水平的知识难度;
- 跨学科覆盖:涵盖六大核心学科:艺术设计、商业、科学、健康医学、人文社科、技术工程,总计 30 个具体领域;
- 多样图像类型:题目配有 39 种异构图像,如图表、化学结构式、乐谱、地图等,强调视觉信息与领域知识融合;
- 参考 MMMU 注释分析流程:严格遵循此前英文评测 MMMU 的设计与分析模式,以保证设计合理并便于跨语言比较。
实验
研究团队选取了 11 个开源 LMM 模型与 GPT‑4V 作为评测对象,统一配置生成参数与评估流程:
- 生成设置:包括温度、token 限制,因模型而异(如 GPT‑4V 温度 1.0,输出长度限制等);
- 评测流程:每道题以图文方式输入模型,采集模型输出并评估其答案正确性,统计分类准确率;
- 定性分析:分析模型在不同学科、题型、图像类型下的表现差异。
结果
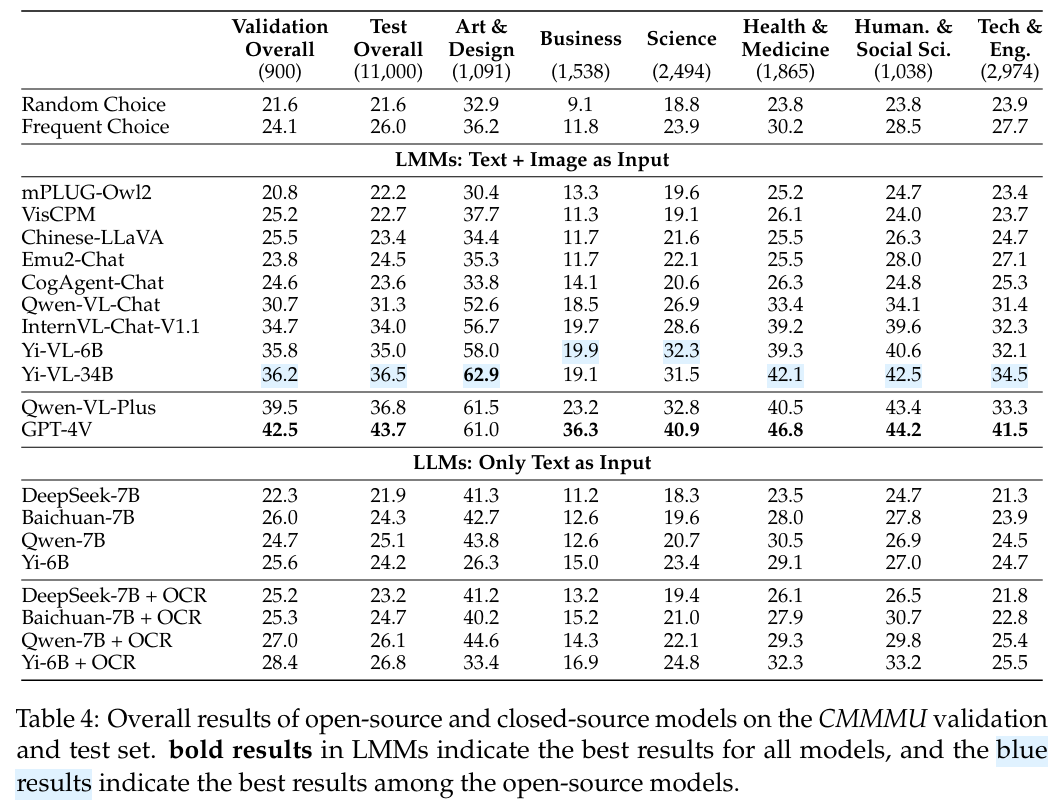
- GPT‑4V 为最强模型,整体准确率仅为 42%,其余 LMMs 表现更差。
- 不同学科与图像类型间表现差异显著,特别是在需要深入领域知识与复杂视觉解析的题目上,模型的表现相对薄弱。
- 整体结论:当前最先进的多模态模型在中文大学级学科任务中仍有巨大进步空间。
总结
CMMMU 作为首个大型中文多学科多模态评测基准,具有以下价值:
- 弥补语言与学科空白:将中文、多模态、大学级学科三者结合,为中国语境下的模型提供真实评测平台;
- 评测体系严谨:题目选自真实教材与考试,覆盖广泛学科与丰富图像类型,兼顾感知和推理;
- 促进模型进化:当前模型在该框架下准确率偏低,表明提升空间明显,激发研究者向“专家级人工智能”迈进;
- 开放共享:公开 12k 中文图文问答任务,助力社区共建基于中文的高级多模态理解系统。