⭐ Towards No.1 in CLUE Semantic Matching Challenge: Pre-trained Language Model Erlangshen with Propensity-Corrected Loss
Published in Arxiv, 2022
关键词
- 语义匹配 / Semantic Matching
- 预训练语言模型 / Pre-trained Language Model (PLM)
- 二郎神 / Erlangshen
- 知识动态遮蔽 / Knowledge-based Dynamic Masking (KDM)
- 倾向校正损失 / Propensity‑Corrected Loss (PCL)
- 全词遮蔽 / Whole Word Masking (WWM)
- CLUE 语义匹配挑战 / CLUE Semantic Matching Challenge
论文地址:https://arxiv.org/abs/2208.02959
背景
- 问题描述:在 NLP 中,语义匹配作为二分类或排序任务,决定两句话是否含义相同,用于信息检索、多来源数据融合等场景。
- 挑战任务:CLUE 发布的 QBQTC 数据集具有三分类标签(不相关、部分相关、高度相关),且偏向于学习排序,且数据严重类别不平衡。
- 问题难点:传统交叉熵对大量负样本过于敏感,会忽略正样本,导致 F1 得分下降。
🛠 方法
1. Erlangshen PLM 架构
- 基于 Transformer、参考 BERT 和 ALBERT,通过 MLM + SOP 策略预训练,采用 WWM 实现整词遮蔽。
- 引入 知识动态遮蔽 (KDM):优先遮蔽语义丰富的实体和事件,而非随机遮蔽,以增强预训练挑战性。
2. 倾向校正损失 (PCL)
- 针对类别不平衡和标签“距离”差异设计:鼓励预测接近真实标签,惩罚跨距离预测错误。
- 通过设定 PCL+ 和 PCL− 分别调整标签平衡,作为 Label‑smoothing 损失的补正。

实验
- 数据集:使用 CLUE QBQTC 数据集,train/dev/test 比例为 18万/2万/5万,标签比例稳定,平均句长约 34 词。
- 预训练与微调:
- 微调模型为
Erlangshen-MegatronBert-1.3B-Similarity。 - 对比模型包括 MacBERT 和 RoBERTa‑wwm。
- 微调模型为
- 消融对比:
- Erlangshen + label‑smoothing 对比基线提升明显。
- 加入 PCL 后,所有模型 F1 与准确度显著提升,Erlangshen F1 提升约 0.50,Acc 提升约 0.90。
结果
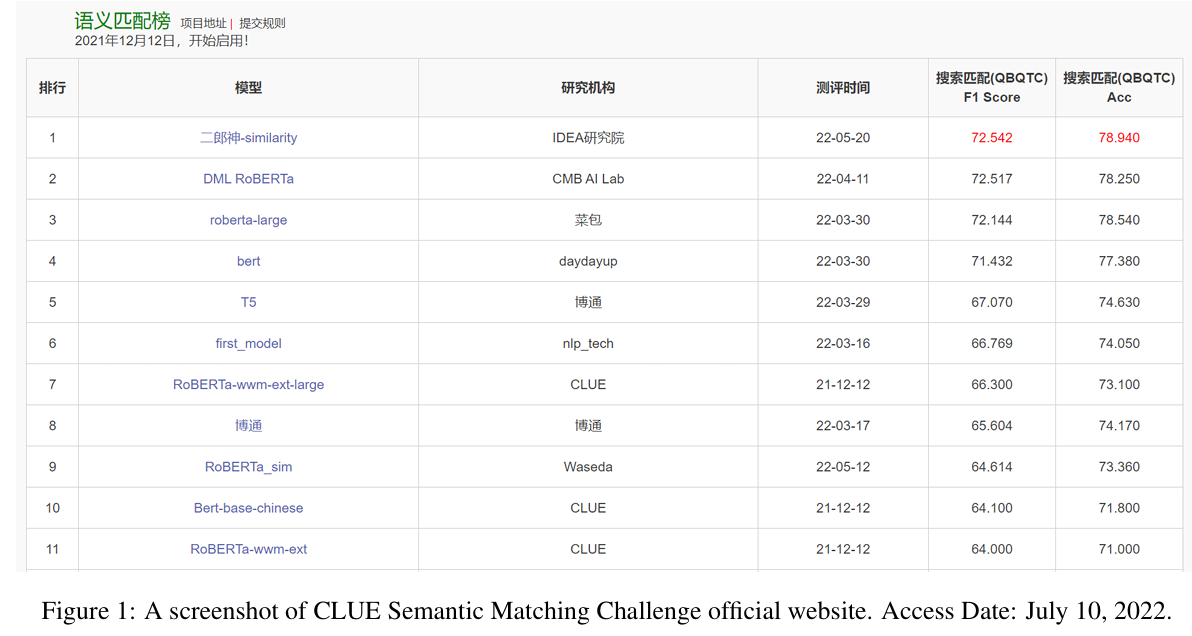
- Leaderboard 排名:Erlangshen + PCL 以 F1 = 72.54、Acc = 78.94 排名第一。
- 对比显著:高于 MacBERT (~71.78 F1)、RoBERTa‑wwm (~70.03 F1)。
- 消融分析:KDM 和 PLM 本身已提供大块性能提升,PCL 对正样本学习仍有进一步加成。
总结
- 贡献:
- 基于全词遮蔽 + 知识动态遮蔽的中国预训练模型 Erlangshen;
- 倾向校正损失 (PCL),针对三分类、标签距离大于单纯交叉熵的限制;
- 系统方案在 CLUE 语义匹配挑战中获第一,F1 达 72.54、Acc 达 78.94(test)。
- 未来方向:作者计划将 PCL 引入局部/全局层面,探索 Erlangshen 在其他下游任务的效果。