⭐ Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence
Published in Arxiv, 2022
关键词
- 中文预训练模型 / Chinese Pre-trained Models
- 基础模型 / Foundation Models
- 开源生态 / Open-Source Ecosystem
- 认知智能 / Cognitive Intelligence
- 基准评估 / Benchmarking
- 模型微调 / Fine-tuning
Arxiv地址:https://arxiv.org/abs/2209.02970
背景 Background
这篇论文聚焦于当前基础模型在中文方向的显著不足。尽管基础模型已成为 AI 基础设施,但绝大多数由英语社区主导,中文用户在资源、机制、社区支持方面都处于劣势。现有中文大模型缺乏统一标准、丰富的数据集和成熟的微调框架,整体发展滞后。论文旨在填补这一空白,提供一个全面、标准化、以用户为中心的中文基础模型生态系统。作者团队由中国认知计算与自然语言处理中心(CCNL)主导,联合研究机构和产业界,共同推动中文预训练大模型的开放发展。通过提供模型、API、基准和数据资源,目标是让不同计算能力的中文用户都能方便地访问并使用大规模模型。
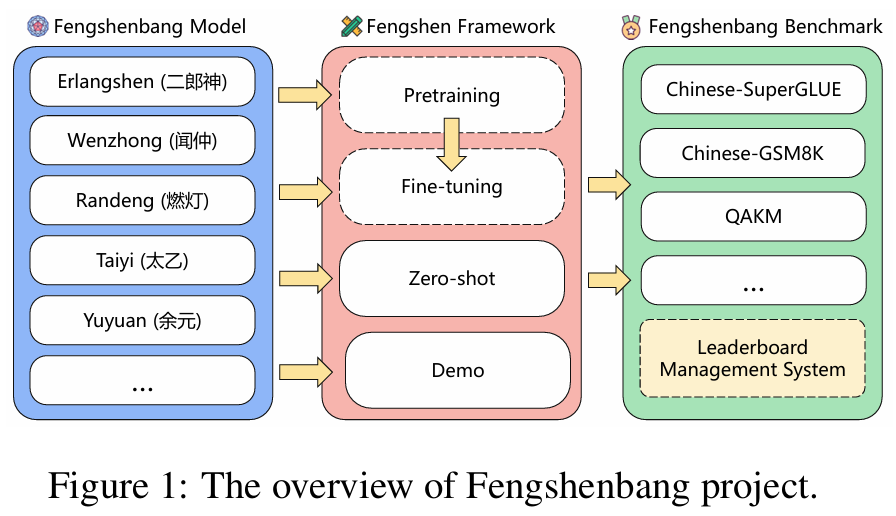
方法 Method
论文提出的方案围绕三个子项目组成一个闭环生态系统:
- Fengshenbang Model:多种不同规模和任务设置的中文预训练模型,提供从基础语言理解到生成能力的支持。
- Fengshen Framework:一套用户友好的工具链和 API,帮助用户快速选择预训练模型进行微调、部署和测试。框架包括教程、脚本、自动化接口。
- Fengshen Benchmark:由多项下游任务组成的评测集,包括分类、生成、问答、推理等多方面任务,统一评估模型性能。
系统中,用户可通过以下流程完成实验:
- 选择适合任务的预训练模型;
- 使用框架进行模型微调和推理配置;
- 在Benchmark上进行评测和对比分析。
此外,项目还提供标准化数据集、评测指标、开放文档,全方位支持中文大模型的训练与应用。
框架 Experiments
- 利用 Fengshenbang Model 提供的预训练模型,对多个公开中文任务进行微调实验。包括文本分类、阅读理解、开放领域生成等。
- 在每项任务中,使用统一流程:基于框架加载模型 → 微调 → 在 Benchmark 上评测。
- 与已有中文/多语种大模型进行对比,包括参数不同规模模型,分析性能差异。
- 实验覆盖大模型稳定性、性能提升、资源占用等多个维度,同时评价微调效率与应用便捷性。
- 数据集和任务选择多样,确保结果具有广泛代表性。
结果 Results
- Fengshenbang 提供的预训练模型整体上在中文下游任务上对标或超越现有开放源模型。
- 在大量任务中,Fengshenbang 微调模型在中文问答、文本生成、阅读理解等任务上均表现出色,取得较高精度和流畅度。
- 微调框架展现了高效且便捷的微调流程,极大降低用户上手门槛。
- Benchmark 的统一评测机制,明显推动模型间性能对比和社区协作。
- 实验还表明该生态系统在资源消耗与性能间达到了良好的平衡,适应用户不同计算资源条件。
总结 Conclusion
Fengshenbang 1.0 项目通过模型、框架和基准测试相结合,建立了中国语言基础模型发展的开放生态。该系统完备、标准、易用,覆盖中文预训练模型开发到评估的全流程。实验结果表明,其模型和工具链在任务表现和使用便利性上具有显著优势。未来愿景包括不断扩大社区规模,涵盖更多研究机构与企业,持续更新模型库与benchmark,推进中文认知智能能力。Fengshenbang 有潜力成为中文大模型发展的重要基石,进一步增强中文 AI 技术自主性与协作水平。