⭐ [EMNLP 2021] MIRTT: Learning Multimodal Interaction Representations from Trilinear Transformers for Visual Question Answering
Published in EMNLP, 2021
关键词
- 多模态交互 / Multimodal Interaction
- 三线性变换器 / Trilinear Transformer
- 视觉问答 / Visual Question Answering (VQA)
- 注意力机制 / Attention Mechanism
- 预训练 / Pre-training
- 两阶段流程 / Two-Stage Workflow
EMNLP 2021: https://aclanthology.org/2021.findings-emnlp.196/
背景
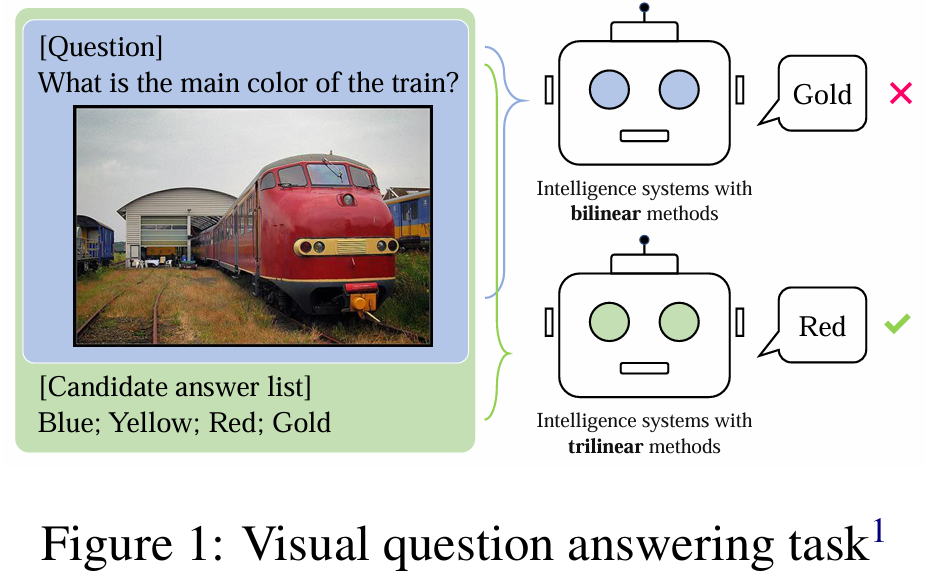
视觉问答(VQA, Visual Question Answering)是人工智能领域的一个重要挑战,要求模型能够理解并整合图片和自然语言问题,从而生成正确的答案。传统的VQA方法大多采用双线性(bilinear)模型,仅关注图片与问题之间的交互,将答案作为标签用于分类。这种做法忽略了答案本身所包含的丰富语义信息,难以充分利用多模态数据间的潜在关系。
近期,三线性(trilinear)模型开始尝试将图片、问题与答案三者间的信息进行联合建模,但已有方法如CTI主要关注模态间(inter-modality)关系,未能充分捕捉模态内(intra-modality)信息,导致推理能力不足。
方法
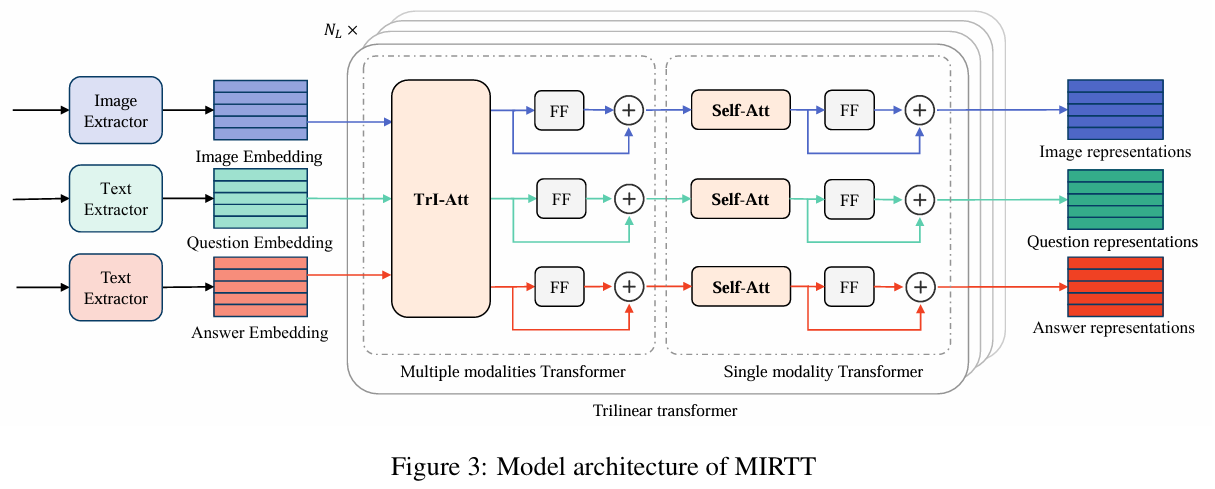
论文提出了一种新的三线性交互框架:MIRTT(Multimodal Interaction Representations from Trilinear Transformers)。其主要创新点包括:
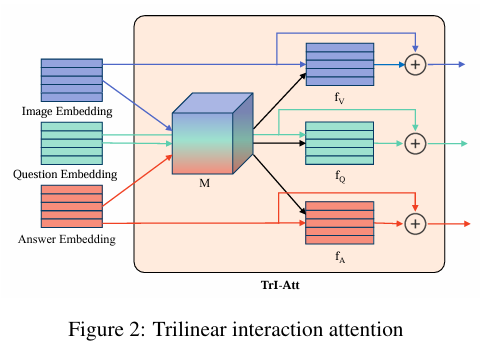
- 三线性交互注意力(TrI-Att):
- 通过三线性注意力机制,将图片、问题和答案的单模态嵌入融合到一个增强的空间中,显著提升多模态信息的表达能力。
- 通过多头注意力(multi-head attention)机制,提升模型的鲁棒性与表达力。
- 自注意力机制(Self-Att):
- 在每一模态内部引入自注意力机制,捕捉模态内的长距离依赖和细粒度信息。
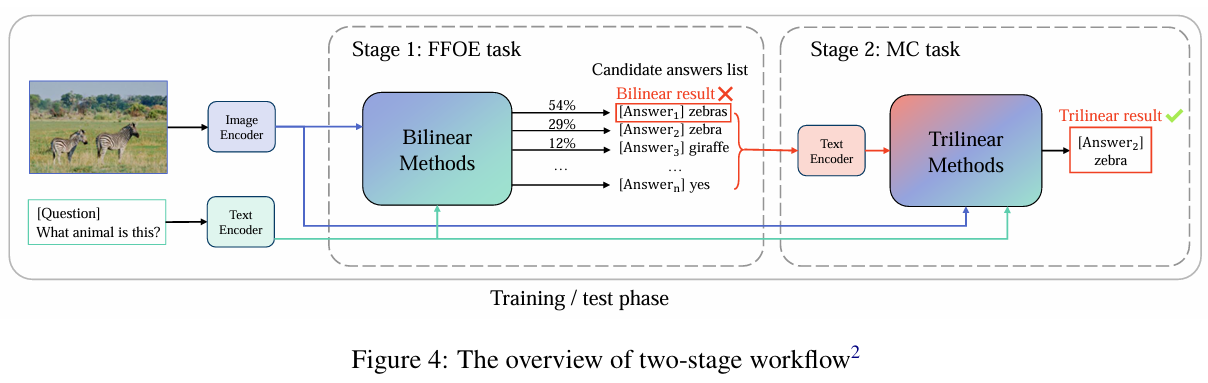
- 两阶段工作流程(Two-stage Workflow):
- 首先使用双线性模型将自由开放式VQA问题(FFOE VQA)转化为多项选择题(MC VQA),大幅降低任务难度。
- 然后利用三线性模型对图片、问题、候选答案三者联合建模,进一步提高模型推理和选择能力。
- 预训练策略:
- 利用大规模VQA相关数据集进行三模态掩码语言建模预训练,为下游任务提供更优的初始化参数,提高泛化能力。
实验
数据集
- Visual7W Telling:每个问题有四个候选答案,只能选择一个正确答案。
- VQA-1.0 Multiple Choice:每个问题有18个候选答案,适合多项选择任务。
- VQA-2.0、TDIUC、GQA:用于自由开放式问答及多模态推理任务,覆盖范围广泛。
实验设计
- 单模态特征提取:
- 图片特征通过Faster R-CNN提取,文本特征通过BERT微调获得。
- 三线性交互与自注意力堆叠:
- 模型堆叠多层三线性交互Transformer和单模态自注意力Transformer。
- 两阶段训练流程:
- 第一阶段:训练双线性模型,选出高概率的候选答案。
- 第二阶段:利用三线性模型对所有候选答案-问题-图片组合分别评分,选择最优答案。
- 预训练:
- 使用Masked Language Modeling进行三模态预训练。
评价指标
- Acc-MC(多选准确率):主用于多项选择题任务。
- ACC(自由问答准确率):考虑到人类答案多样性的准确率指标。
结果
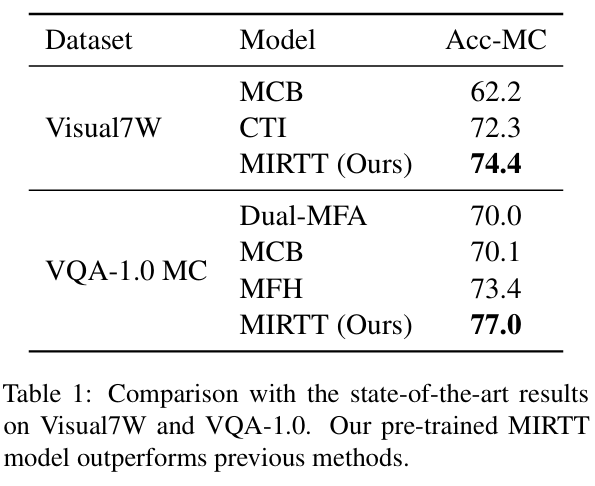
- 主流数据集表现优异:
- 在Visual7W Telling和VQA-1.0 MC任务中取得最新最优(state-of-the-art)结果,准确率分别达到74.4%和77.0%。
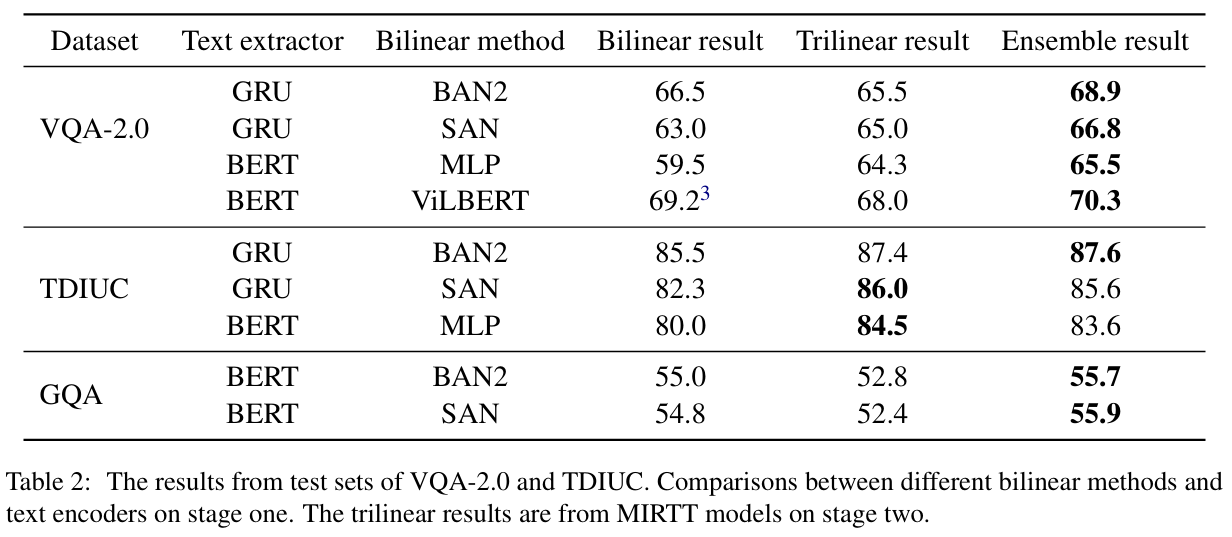
- 在VQA-2.0、TDIUC、GQA等开放式问答任务中,MIRTT均超越传统双线性基线方法,表现出良好的泛化能力和鲁棒性。
- 注意力机制有效性验证:
- 三线性注意力(TrI-Att)和自注意力(Self-Att)共同作用,显著提升模型性能。
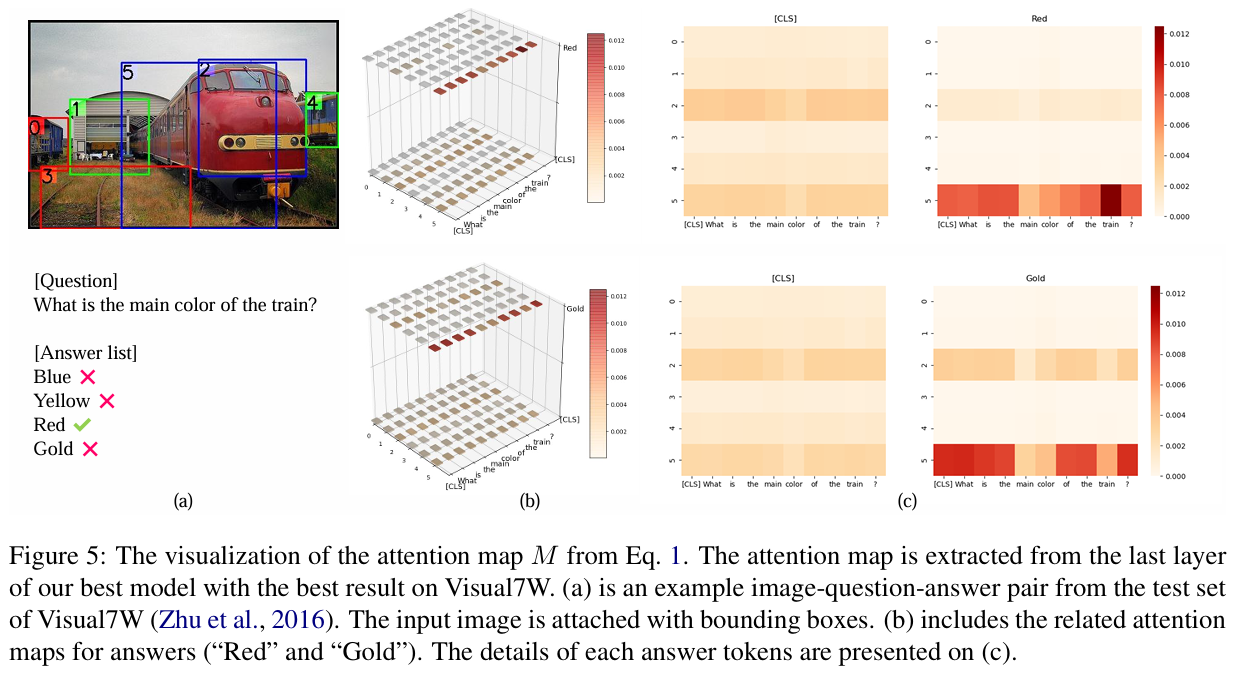
- 可视化分析显示模型能将正确答案与图片中关键对象和问题内容建立有效关联。
- 两阶段流程优势明显:
- 成功将复杂的自由问答任务转化为易于三模态建模的多项选择题,提升整体系统的可用性和可解释性。

总结
本论文提出的MIRTT模型及两阶段工作流程,在视觉问答任务中实现了对图片、问题与答案三模态信息的深度融合。创新的三线性交互注意力和自注意力机制,使模型能有效捕捉模态间及模态内的信息,提升了推理和泛化能力。大量实验证明MIRTT在多项主流VQA数据集上均取得了显著提升,为多模态人工智能任务提供了新思路和强有力的基线。