⭐ [NTCIR 15] SKYMN at the NTCIR-15 DialEval-1 Task
Published in NTCIR, 2020
关键词(中 / 英)
- 对话质量 / Dialogue Quality
- 关键转折点 / Nugget Detection
- BiLSTM 注意力机制 / BiLSTM + Attention
- 卷积神经网络 / CNN (Convolutional Neural Network)
- 预训练语言模型 / Pre‑trained Language Model
- 多任务学习 / Multi-task Learning
背景
本论文来自 NTCIR‑15 的 DialEval‑1(对话评估)任务,旨在自动评估客户服务对话的质量与关键信息点(nugget)。传统上这类评估依赖人工标注,不仅昂贵且耗时。因此,研究者期望开发自动化模型,既能给整个对话打分(任务完成度、客户满意度、效率),又能识别对话中帮助问题解决的关键转折点。本论文目标正是提出一种高效、准确的评估系统,解决当前评估瓶颈。
方法
论文比较并融合多种网络模型(CNN、BiLSTM+注意力、LSTM+GRU+CNN,简称 LGC)与预训练语言模型(如 DistilRoBERTa、ALBERT)。首先,使用 GloVe 将词语编码为 50 维词向量,处理对话文本并固定最大长度为 256。对于 CNN 模型,借鉴 Kim 模型的架构,提取局部特征并输出三类评分。BiLSTM 结构配合多头注意力机制,更好建模长程依赖与关注关键词汇位置。LGC 模型则结合 LSTM、GRU 和 CNN,兼顾长期依赖和计算效率。此外,还尝试用预训练语言模型替换嵌入层,并采用多任务学习同时训练对话质量与 nugget 检测任务。
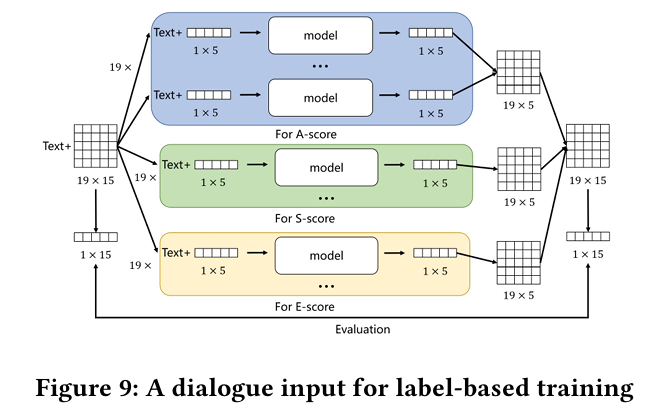
(当年我还不知道有MoE这个概念)
使用MoE架构模拟19个标注者的行为习惯,然后综合评分成一个分数分布。
实验
研究使用 NTCIR‑15 English 数据集(2,251 训练、300 测试)进行实验。每种模型训练后,在测试集上预测三种评分(A‑score, S‑score, E‑score)和 nugget 标签。模型通过度量指标如 RSNOD 和 NMD(对话质量)、RNSS 和 JSD(nugget 检测)进行评估。还进行了统计显著性检验,包括 Tukey HSD,验证提升是否稳健。
结果
- 单模型中,BiLSTM + Attention 报告平均得分优于 CNN 与 LGC。
- 使用 DistilRoBERTa 替换嵌入后,A‑score 平均值达到 0.421,显著高于基线(p < 0.0001)。
- 使用 ALBERT 后得分达 0.385,同样显著优于传统模型。
- 预训练语言模型在统计检验上优于 CNN 和 ALBERT(E‑score, p < 0.0001)。
- 多任务学习设计算法在两个子任务(对话评分与 nugget 检测)都表现良好,效率提升明显。
总结
本文提出的融合多种深度学习结构与预训练语言模型的多任务学习范式,在 DialEval‑1 任务中取得了先进水平的性能。研究表明:引入预训练语言模型(DistilRoBERTa、ALBERT)显著提升对话质量评估准确性;采用 BiLSTM + 注意力有效捕捉对话信息;而多任务训练可提高 nugget 检测与评分任务的泛化能力。未来工作可进一步探索更多预训练模型、检索方法和其他评估方案以提升性能。