💭🚩 Think-with-Rubrics: From External Evaluator to Internal Reasoning Guidance
Published in Arxiv, 2026
Arxiv地址:https://arxiv.org/abs/2605.07461
1. 关键词 (Keywords)
- Rubric-Guided Reasoning / 量规引导推理
- Instruction Following / 指令遵循
- Rubric-as-Reward / 量规作为奖励
- Internal Reasoning Guidance / 内部推理引导
- Self-Generated Rubrics / 自生成量规
- Golden Rubric Consistency / 黄金量规一致性
- Self-Consistency Reward / 自一致性奖励
- Open-Ended RL / 开放式任务强化学习
2. 背景与动机 (Background & Motivation)
问题定义
论文关注开放式 instruction following 中的一个核心问题:rubric 目前多被用作外部评价器,而不是模型生成过程中的内部指导。
在可验证任务中,RL 可以依赖标准答案、程序检查或规则 reward;但在开放式任务中,模型输出没有唯一 ground truth,简单 scalar reward 或整体 LLM-as-a-judge 往往过于粗糙。因此,近年出现了 Rubric-as-Reward 范式:把任务拆成多条可解释 criteria,再根据 response 满足多少 criteria 来给 reward。
但已有 Rubric-as-Reward 仍然存在一个关键局限:rubric 只在回答生成之后作为 post-hoc evaluator 使用。也就是说,模型回答时并没有显式看到或构造这些成功标准,rubric 只能衡量输出,而不能主动指导输出。
核心动机
Think-with-Rubrics 的出发点是:人类解决复杂任务时,往往会先明确“什么算成功”,再据此执行。对应到 LLM,模型也应该先生成任务相关 rubric,再在这个 rubric 的约束下生成答案。
这使 rubric 从外部评价物转变为内部推理轨迹的一部分:
- 外部评价:answer → rubric evaluator → reward;
- 内部指导:instruction → self-generated rubric → answer。
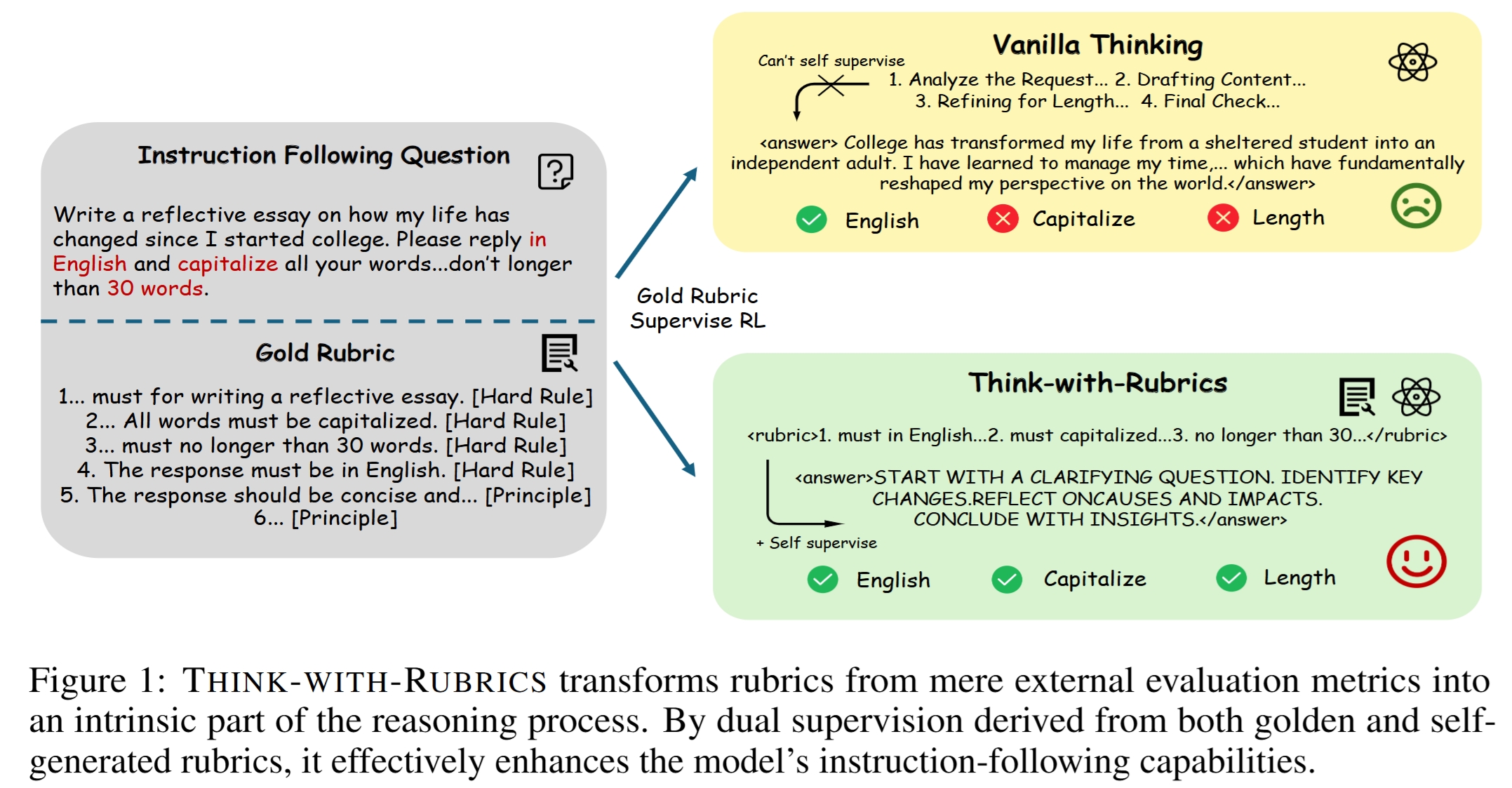
与普通 thinking 的区别
普通 chain-of-thought 或 free-form thinking 可以帮助模型分析问题,但它不一定形成可验证、可监督的标准。Think-with-Rubrics 则把思考过程结构化为 criteria,天然适合 reward 分解、consistency checking 和 RL 训练。
换言之,rubric 是一种更可监督的 reasoning trace:它不仅解释模型在想什么,还明确列出 answer 应满足哪些 hard rules 和 quality principles。
3. 核心方法 (Core Methodology)
整体框架:Think-with-Rubrics
Think-with-Rubrics 要求模型按如下格式输出:
<rubric>
1. ... [Hard Rule]
2. ... [Principle]
</rubric>
<answer>
...
</answer>
模型先为当前 instruction 生成 self-generated rubric,再基于该 rubric 生成 final answer。轨迹可以理解为:
instruction x --> self-generated rubric r_hat --> answer y与传统只生成 answer 的 policy 不同,这里 policy 先显式建模成功标准,再生成答案;因此 answer 可以被训练为同时满足 golden rubric 和模型自己生成的 rubric。
Problem Formulation
论文将 rubric 定义为一组离散 criteria:
r = {c_1, c_2, ..., c_n}OpenRubrics 中的 golden rubric 会把 criteria 分成两类:
- Hard Rules:必须满足的硬约束,例如格式、语言、长度、必须包含某类内容;
- Principles:更高层次的质量原则,例如完整性、帮助性、简洁性。
Think-with-Rubrics 的 policy 生成联合轨迹:
pi_theta(tau | x) = pi_theta(r_hat | x) * pi_theta(y | x, r_hat)其中 r_hat 是模型自生成 rubric,y 是最终 answer。
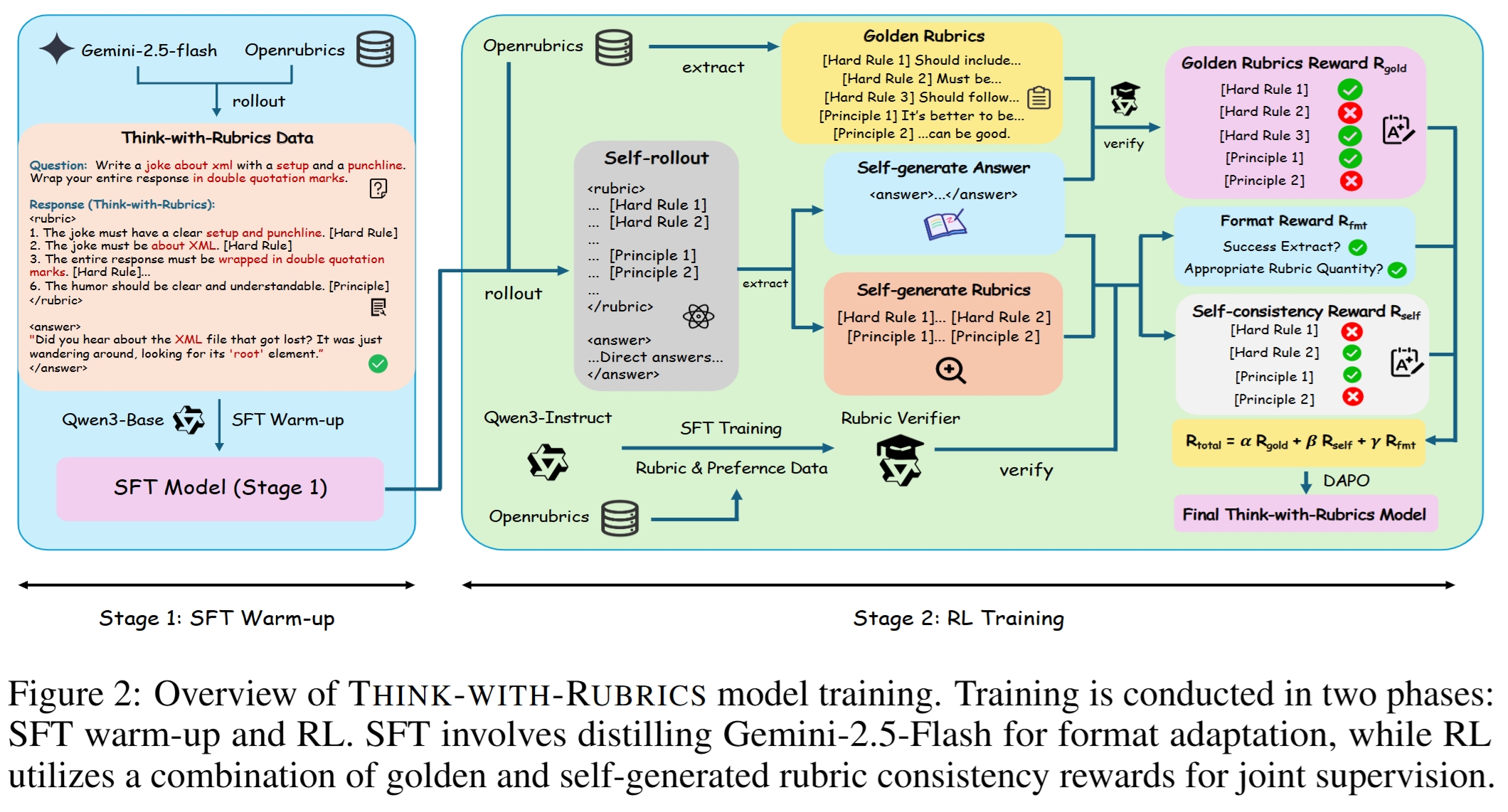
SFT Warm-up
直接使用 base model 时,约 20% 样本无法稳定输出 <rubric> 与 <answer> 格式。因此,论文先进行 SFT warm-up,目标不是直接提升最终能力,而是让模型稳定掌握 “rubric → answer” 的轨迹结构。
SFT 数据来自 OpenRubrics 上的 5k 样本,由 Gemini-2.5-Flash 蒸馏生成 Think-with-Rubrics 格式的 response。模型学习完整轨迹,包括 rubric 与 answer。
Rubric Verifier
RL 阶段需要判断 answer 是否满足 rubric 中每条 criterion。论文没有直接使用通用 LLM-as-a-judge,而是训练了一个专门的 rubric verifier:
- student verifier:Qwen3-8B-Instruct;
- teacher verifier:Qwen3-32B-Instruct;
- training data:OpenRubrics 的 response pairs 与 criterion-level verification traces;
- verifier 在 1.5k response pairs 上达到 93.2% rubric-level judgment accuracy,高于原 Qwen3-8B 的 86.3%。
Verifier 对每个 criterion 判断 met / not met,再将 hard rules 和 principles 按权重聚合为 rubric-level consistency score。
Reward System
Think-with-Rubrics 的 reward 由三部分组成:
R_total = alpha * R_gold + beta * R_self + gamma * R_fmt其中:
Golden rubric consistency reward (
R_gold) 检查最终 answer 是否满足 OpenRubrics 提供的 golden rubric。Self-generated rubric consistency reward (
R_self) 检查最终 answer 是否满足模型自己生成的 rubric。它衡量的是内部一致性:模型是否真的按自己列出的标准回答。Format reward (
R_fmt) 防止 reward hacking。模型必须成功输出<rubric>和<answer>,且 self-generated rubric 的 criteria 数量处于合理区间。OpenRubrics 中 99.61% 样本的 criteria 数量在 5 到 15 之间,平均 8.66,mode 为 10,因此 format reward 鼓励 rubric 数量接近 10。
训练使用 DAPO,无 KL loss。默认 reward 权重为:
alpha = 0.3beta = 0.5gamma = 0.2- hard rule / principle 权重:
w_h = 2,w_p = 1
4. 实验设计 (Experimental Design)
模型与数据
主要实验使用:
- Policy model:Qwen3-8B-Base;
- 4B 消融:Qwen3-4B-Base;
- SFT 数据:OpenRubrics 5k;
- Verifier 训练数据:OpenRubrics 2k;
- RL 数据:OpenRubrics 27k;
- SFT teacher:Gemini-2.5-Flash;
- Verifier teacher:Qwen3-32B-Instruct。
所有数据 split 严格不重叠,避免训练/评估泄漏。
训练设置
SFT warm-up:
- 训练 200 steps;
- learning rate
1e-5; - batch size 32;
- Qwen3-8B-Base 使用 LLaMA-Factory 和 DeepSpeed ZeRO-3;
- 4 张 H20 GPU。
RL stage:
- DAPO,无 KL loss;
- batch size 32 prompts;
- 每个 prompt rollout 8 个 replies;
- learning rate
1e-6; - 约 90 steps 达到最优;
- 8 张 H20 GPU。
详细超参见原文 Table 7 和 Table 8。
Baselines
论文比较三类设置:
- Base model:Qwen3-8B-Base / Qwen3-4B-Base。
- Rubric-as-Reward baseline:
- direct answer:直接回答,只用 golden rubric reward;
- with think:先自由 thinking,再回答,只用 golden rubric reward。
- Think-with-Rubrics:
- SFT Warm-up;
- DAPO with golden rubric reward only;
- DAPO with self-generated rubric reward only;
- DAPO with mixed reward。
Evaluation Benchmarks
论文评估三个 instruction-following benchmark:
- IFEval:严格指令约束;
- IFBench:多规则指令遵循;
- InfoBench:开放式 instruction-following quality。
IFEval 和 IFBench 报告 strict prompt-level 和 instruction-level accuracy;Average 使用 IFEval prompt-level、IFBench prompt-level 和 InfoBench 三者宏平均。
5. 实验结果与分析 (Results & Analysis)
主结果:Rubrics 作为内部推理优于外部奖励
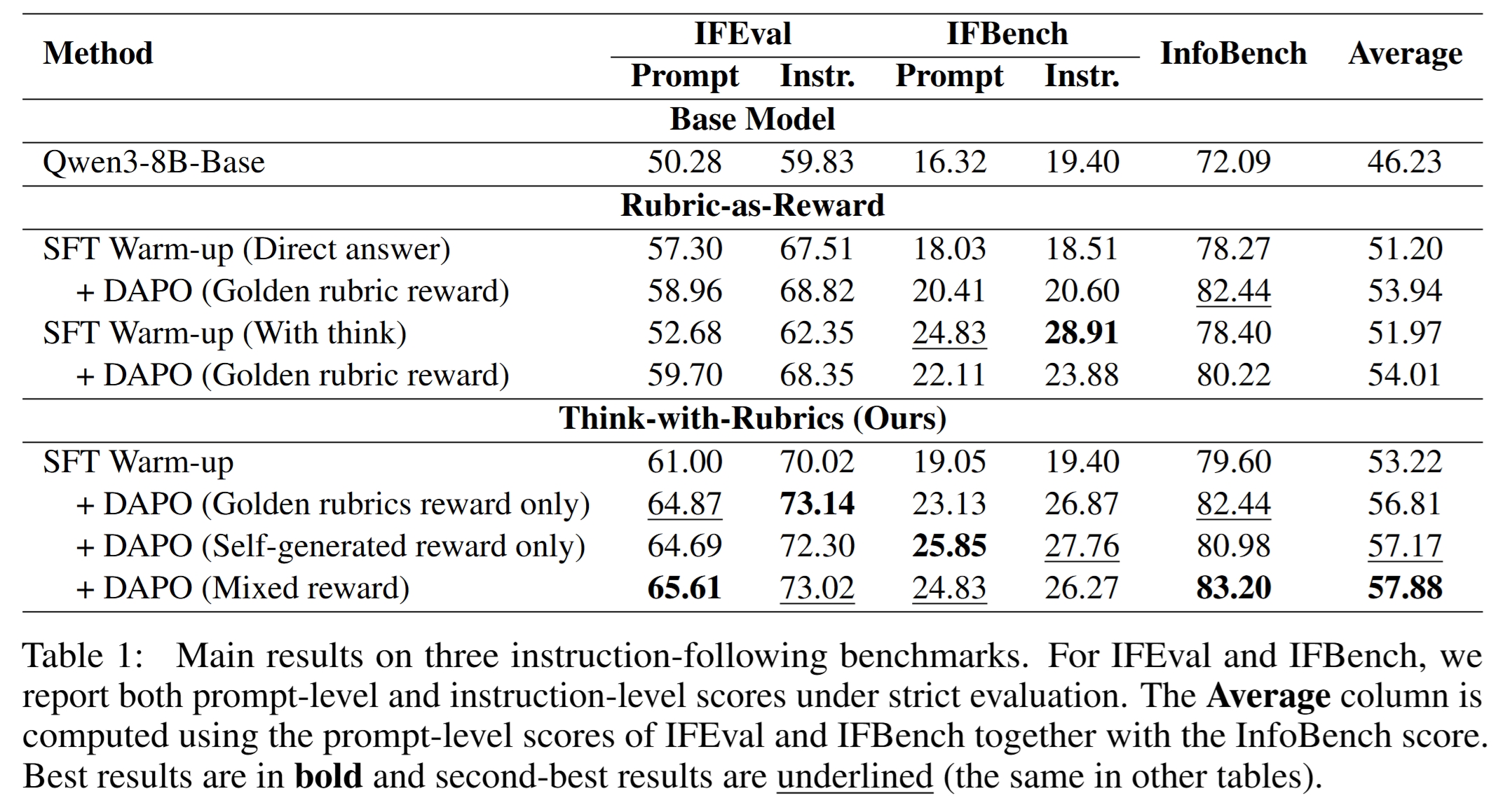
在 Qwen3-8B-Base 上,Think-with-Rubrics mixed reward 取得最佳平均分:
- Base Model:46.23
- Rubric-as-Reward direct answer + DAPO:53.94
- Rubric-as-Reward with think + DAPO:54.01
- Think-with-Rubrics SFT:53.22
- Think-with-Rubrics + DAPO golden only:56.81
- Think-with-Rubrics + DAPO self-generated only:57.17
- Think-with-Rubrics + DAPO mixed reward:57.88
相较最强 Rubric-as-Reward baseline,Think-with-Rubrics 平均提升约 3.87 points。
这说明 rubric 不只是 reward,也可以作为更有效的 reasoning scaffold。普通 free-form thinking 虽然能让模型“思考”,但不如 rubric 这种结构化、可监督的 thinking trace。
Mixed reward 最有效
Table 1 显示 mixed reward 效果最好。论文给出的解释是:golden rubric reward 和 self-generated rubric reward 解决的是不同问题。
R_gold主要让 answer 对齐外部标准,并间接提升 self-generated rubric 的质量;R_self主要让 answer 遵循模型自己生成的 rubric,提高内部一致性;- 二者结合,使模型既能生成更合理 rubric,也能更稳定地按 rubric 执行。
值得注意的是,self-generated reward only 已经达到 57.17,略高于 golden only 的 56.81。这说明一旦 rubric 被内化到 reasoning trace 中,自监督式 self-evolution 是可行的。
Rubric 质量分析
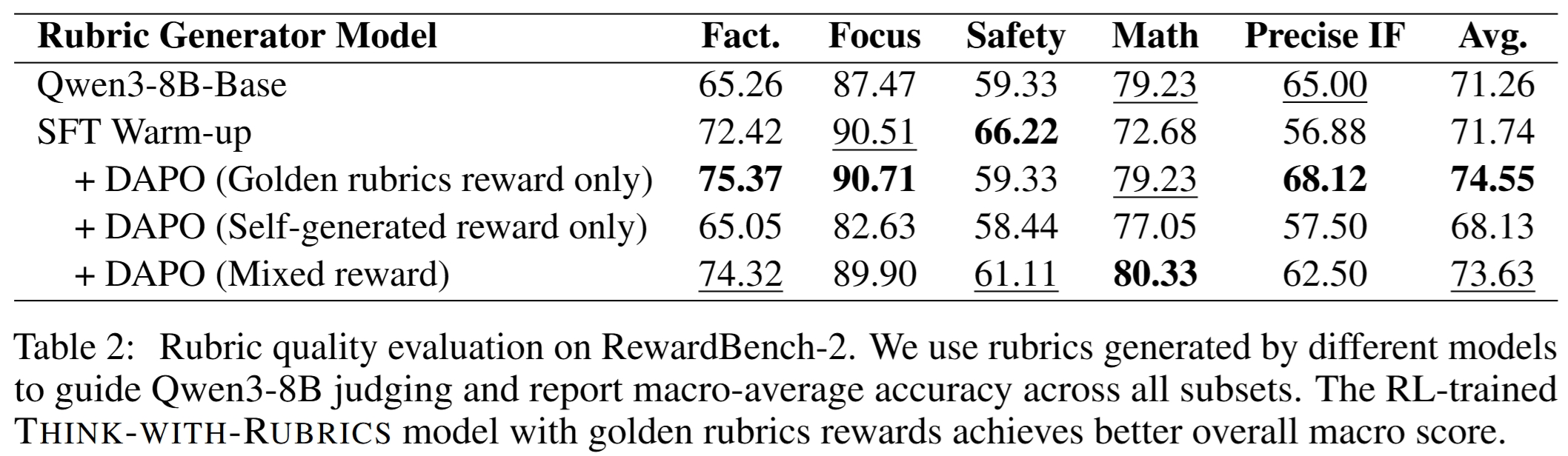
论文用不同模型生成的 rubric 去指导 Qwen3-8B-Instruct 在 RewardBench-2 上做 judge,并用 judge accuracy 评估 rubric 质量。
主要结果:
- Qwen3-8B-Base rubric:Avg = 71.26
- SFT Warm-up rubric:Avg = 71.74
- Golden reward only:Avg = 74.55,最高;
- Self-generated reward only:Avg = 68.13;
- Mixed reward:Avg = 73.63。
这说明 golden rubric supervision 可以间接提高 self-generated rubric 的外部评价质量。但 self-only 模型虽然 instruction-following 表现强,生成的 rubric 作为外部 judge 的质量反而下降。这表明 self-generated rubric 的价值不一定在于成为通用外部评价器,而在于成为模型自身 answer generation 的内部控制信号。
内部一致性分析

论文用 rubric verifier 评估模型生成 answer 与 self-generated rubric 之间的一致性。结果显示:
- SFT Warm-up:IFEval 58.91,IFBench 60.15;
- Golden only:IFEval 68.70,IFBench 75.12;
- Self-generated only:IFEval 69.00,IFBench 75.45;
- Mixed reward:IFEval 69.38,IFBench 77.82。
加入 self-generated reward 后,answer-rubric consistency 平均提升约 14.07 points。这解释了为什么 self-only reward 能有效:它直接训练模型遵循自己生成的标准,缓解了“想到了但没做到”的内部不一致问题。
Reward 权重敏感性
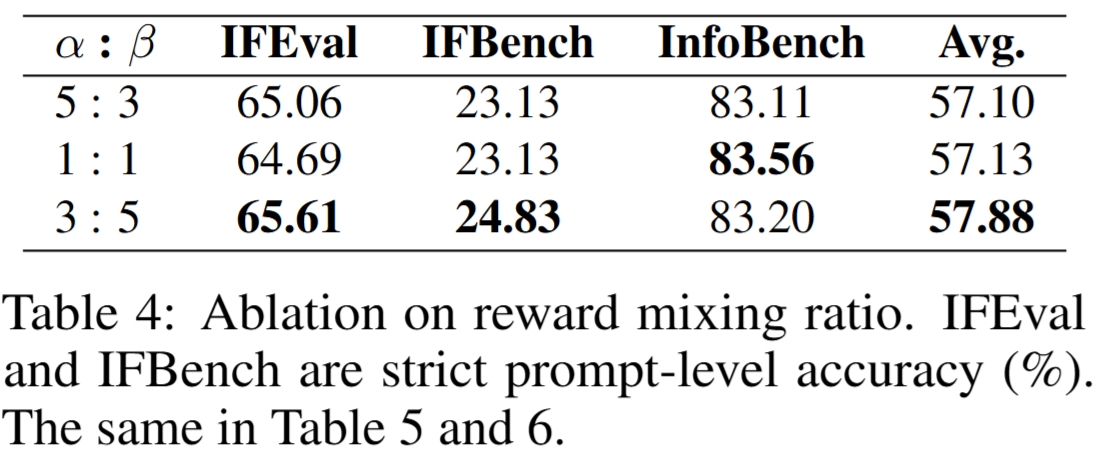
论文比较 alpha:beta = 5:3, 1:1, 3:5,即 golden reward 和 self-generated reward 的权重比例。三种设置都表现较强,平均分差距在约 1.3 点以内,其中 3:5 最好,Avg = 57.88。
这说明 Think-with-Rubrics 对 reward mixing ratio 较稳健;略偏向 self-generated reward 有利于提升最终表现。
Hard Rule 与 Principle 权重
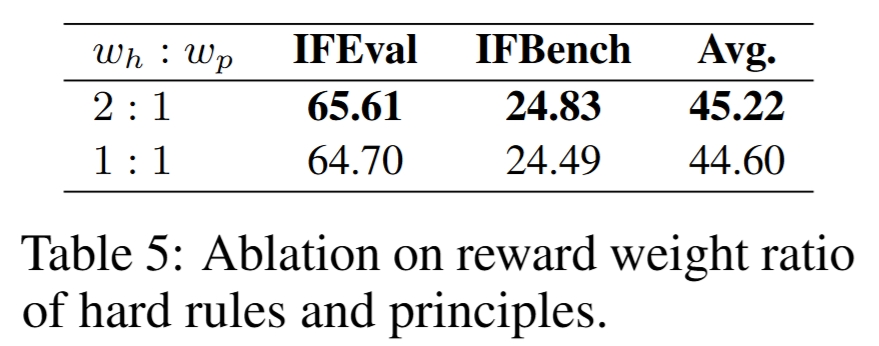
论文比较 hard rules 与 principles 的 reward 权重:
w_h:w_p = 2:1:IFEval 65.61,IFBench 24.83,Avg 45.22;w_h:w_p = 1:1:IFEval 64.70,IFBench 24.49,Avg 44.60。
结果显示 hard rules 更高权重略优,说明模型生成的 rubric 中确实存在重要性层级;但该因素不是主导性能的唯一原因。
4B 模型消融
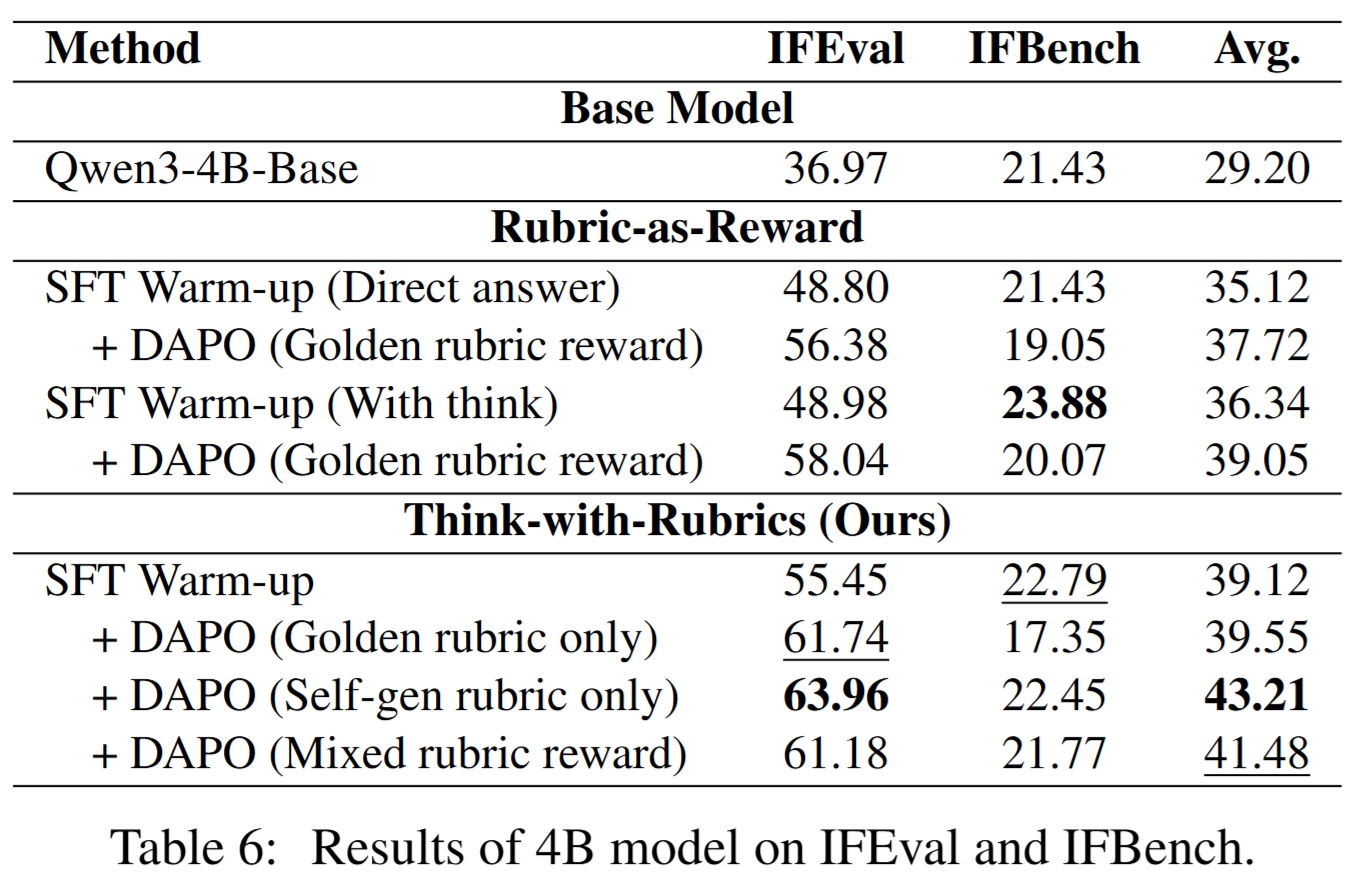
在 Qwen3-4B-Base 上,Think-with-Rubrics 仍然优于 Rubric-as-Reward:
- Base:Avg = 29.20
- Rubric-as-Reward direct + DAPO:Avg = 37.72
- Rubric-as-Reward with think + DAPO:Avg = 39.05
- Think-with-Rubrics SFT:Avg = 39.12
- Think-with-Rubrics golden only:Avg = 39.55
- Think-with-Rubrics self-generated only:Avg = 43.21
- Think-with-Rubrics mixed reward:Avg = 41.48
4B 上 self-generated only 表现最好,说明较小模型尤其需要 self-consistency supervision 来减少“生成了 rubric 但 answer 不遵循”的问题。
Case Study

案例来自 IFEval:用户要求用英文、全大写、30 词以内,给出关于 college life reflective essay 的写作建议。
Rubric-as-Reward baseline 给出了语义合理但违反 capitalization 或长度约束的回答。普通 thinking 甚至识别了约束,却在 final check 中错误地认为已经满足。Think-with-Rubrics 则先列出 hard rules,再生成完全大写且长度合规的 answer。
这个案例说明:非结构化 thinking 可能识别约束但无法保证执行;rubric 化 thinking 能把约束变成 answer generation 前的显式 checklist,再通过 self-consistency reward 训练模型遵守自己的 checklist。
6. 总结与贡献 (Conclusion & Contribution)
主要结论
Think-with-Rubrics 的核心结论是:rubric 不应只作为外部 evaluator 或 RL reward,而可以被内化为模型生成前的结构化推理指导。当模型先生成 rubric 再生成 answer 时,rubric 既是 reasoning scaffold,也是可监督对象,从而把 judge ability 和 solve ability 更紧密地连接起来。
核心贡献
- 提出 Think-with-Rubrics 范式:将 rubric 从 post-hoc evaluation artifact 转化为内部 reasoning trace。
- 构建两阶段训练流程:先 SFT warm-up 学习
<rubric> → <answer>格式,再用 DAPO 进行 rubric consistency reward 优化。 - 设计三部分 reward system:结合 golden rubric consistency、self-generated rubric consistency 和 format reward。
- 实证超过 Rubric-as-Reward baseline:8B 平均提升约 3.87 points,4B 上也保持优势。
- 解释机制来源:golden supervision 提升 self-generated rubric 质量,self-generated supervision 提升 answer-rubric 内部一致性。