⭐ [CVPR 2023] MAP: Modality-Agnostic Uncertainty-Aware Vision-Language Pre-training Model
Published in CVPR, 2023
关键词
- 多模态 / Multimodality
- 不确定性建模 / Uncertainty Modeling
- 视觉-语言预训练 / Vision-Language Pre-training
- 概率分布编码器 / Probability Distribution Encoder (PDE)
- 跨模态对齐 / Cross-modal Alignment
Arxiv地址:https://arxiv.org/abs/2210.05335
背景
- 问题与挑战:随着多模态表示学习的快速发展,视觉-语言任务(如图文检索、视觉问答等)取得了显著进展。然而,在实际的多模态语义理解中,存在大量的“不确定性”,表现为同一视觉区域可能对应多个目标,或同一文本描述可能有多种解释。这种不确定性包含了模态内(intra-modal)与模态间(inter-modal)两类,若忽视这部分内容,容易导致对复杂概念的理解受限,缺乏预测的多样性。
- 现有方法局限:当前主流预训练方法多采用确定性(point representation)表示,难以捕捉和建模数据中潜在的不确定性。这限制了模型对复杂语义的表达能力和泛化能力。
- 任务目标:论文希望提出一种可以有效感知和表达多模态不确定性的预训练方法,从而提升视觉-语言任务中的语义理解能力和结果多样性。

方法
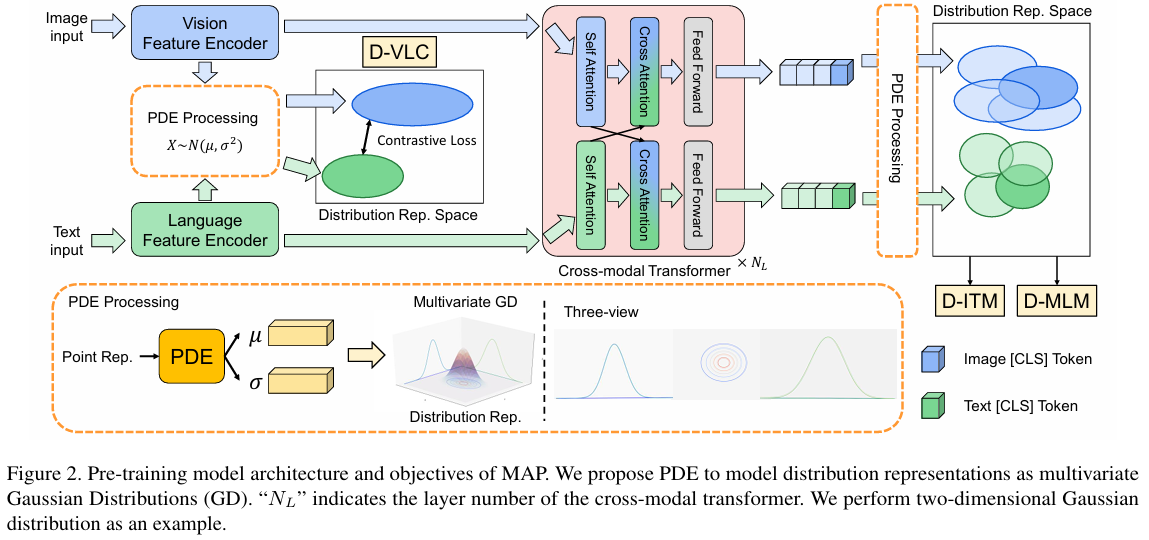
- 核心思想:将多模态特征从点表示扩展为概率分布表示,具体为高维高斯分布(multivariate Gaussian),从而表达语义空间中的不确定性和多样性。
- 概率分布编码器(PDE):
- 输入为传统视觉/语言特征(点表示)。
- 通过PDE编码后,每个特征被表征为一个高斯分布(均值µ和方差σ²),用于量化其在语义空间中的位置与不确定范围。
- PDE模块融合了特征级(feature-level)和序列级(sequence-level)信息交互,提升分布表达的准确性和丰富性。
- 网络结构:
- 特征提取器:视觉端采用CLIP-ViT,文本端采用RoBERTa-Base。
- 跨模态Transformer:采用双流(dual-stream)结构,实现模态间的深度融合。
- 多层PDE嵌入:分别在特征提取器后和跨模态融合后引入PDE,实现从单模态到多模态的分布式表达。
- 分布式预训练任务:
- D-VLC(Distribution-based Vision-Language Contrastive learning)
基于分布的图文对比学习,实现模态间粗粒度的对齐,采用2-Wasserstein距离度量高斯分布的相似性。 - D-MLM(Distribution-based Masked Language Modeling)
基于分布的掩码语言模型,通过采样分布点预测被遮蔽的单词,实现细粒度跨模态对齐。 - D-ITM(Distribution-based Image-Text Matching)
基于分布的图文匹配任务,对采样后的融合分布特征进行匹配判别,提升图文对齐能力。 - 正则化损失:为防止分布退化为点表示,引入分布熵下界约束,保证模型持续学习和保持不确定性表达。
- D-VLC(Distribution-based Vision-Language Contrastive learning)
实验
- 实验设置:
- 特征维度768,跨模态Transformer层数6,采用大规模公开多模态数据集(MSCOCO、VG、SBU、CC-3M)进行预训练。
- 图像输入尺寸384×384,文本最大长度50。
- PDE模块头数6,激活函数采用Softmax以加强序列级交互。
- 评测任务:
- 图文检索(MSCOCO、Flickr30K):评估模型对多概念不确定性理解能力。
- 视觉问答(VQA2.0):测试模型对视觉和语言复杂语义的推理与融合能力。
- 视觉推理(NLVR2)、视觉蕴涵(SNLI-VE):考查模型处理模态间、模态内歧义与复杂语义推理的能力。
- 对比方法:
- 与当前主流视觉-语言预训练模型(如UNITER、ViLT、ALBEF、METER等)以及采用概率分布建模的PCME进行全面对比。
- 消融实验:
- 探讨PDE结构不同设计(如是否引入序列级交互)、不同预训练任务组合、不同Transformer层数对下游任务的影响,证明PDE结构与分布式预训练的有效性。
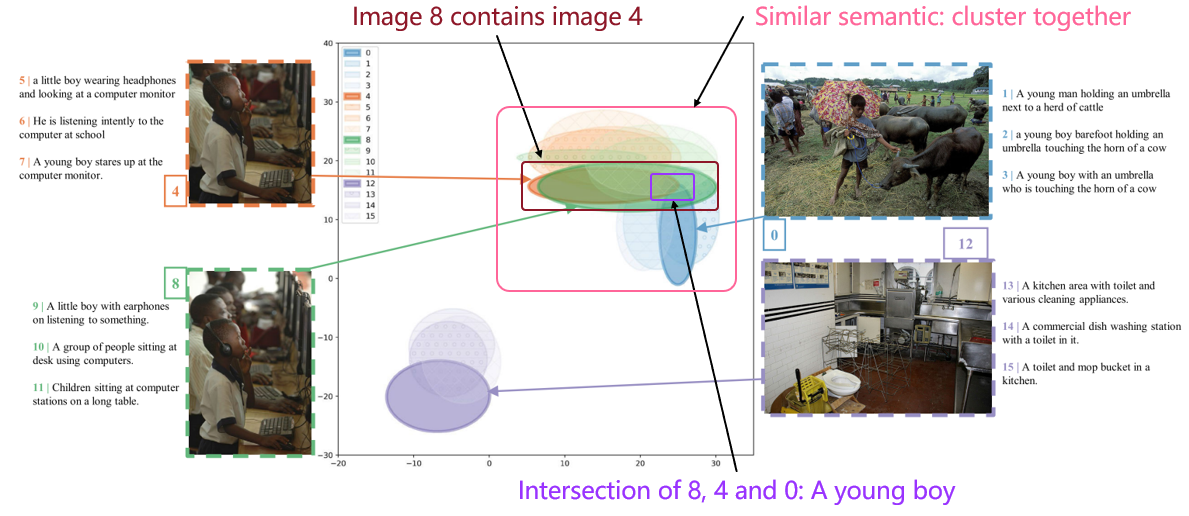
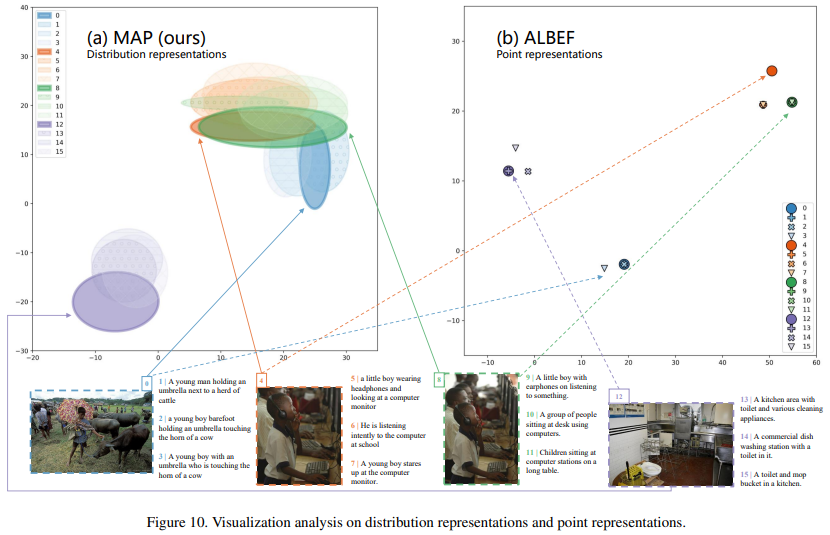
- 可视化分析显示,采用分布建模后,语义相近的图文样本在分布空间中能够有效聚类,同时模型输出也能实现多样化预测。
结果
- 主结果:
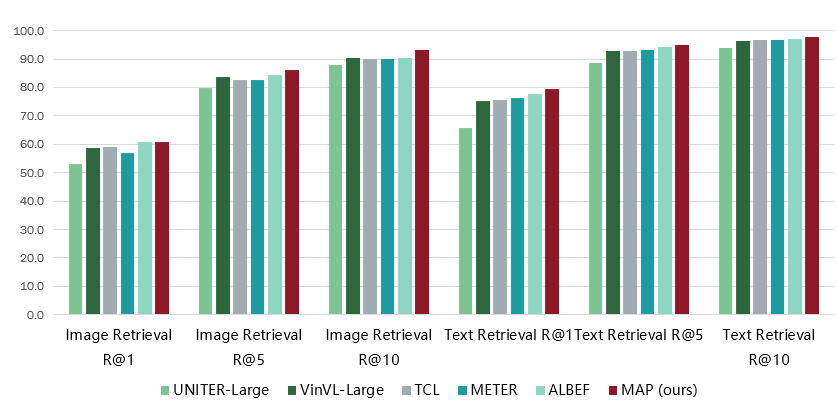
- MAP在多个视觉-语言下游任务上取得了最优或次优表现,尤其在图文检索(MSCOCO、Flickr30K)、视觉问答(VQA2.0)、视觉推理(NLVR2)和视觉蕴涵(SNLI-VE)上均超越主流SoTA模型。
- 具体在MSCOCO检索任务上,MAP在Recall@1/5/10等各项指标均取得最佳表现。
- 在VQA2.0等任务上,MAP相较于不采用不确定性建模的模型有0.5分以上提升。
- 不确定性建模优势:
- 能够捕捉多样的语义对应关系,支持多样性预测(如视觉问答中可给出多个合理答案)。
- PDE的引入显著提升了模型的泛化能力和对复杂语义关系的刻画能力。
总结
- 论文针对多模态不确定性建模难题,创新性地提出了概率分布编码器(PDE),将视觉和语言特征映射为高斯分布,实现从单点到分布的多样性表达。
- 结合分布建模,设计了三项全新的分布式预训练任务,显著提升了模型对复杂语义和不确定性的理解能力。
- 通过大量实验与消融分析,MAP模型不仅在标准数据集上实现了性能提升,还展现出更强的多样性预测能力和泛化能力。
- 该方法为未来多模态语义理解与生成提供了新的研究思路和技术基础。