⭐ [EMNLP 2022] Zero-Shot Learners for Natural Language Understanding via a Unified Multiple Choice Perspective
Published in EMNLP, 2022
关键词
- 零样本学习 / Zero‑Shot Learning
- 多项选择格式 / Multiple Choice Format
- 预训练掩码语言模型 / Pre‑trained Masked Language Model (PMLM)
- 选项掩码预测 / Option‑Masked Language Modeling (O‑MLM)
- 选项预测 / Option Prediction (OP)
- UniMC(统一多选模型) / Unified Multiple Choice model
Arxiv地址:https://arxiv.org/abs/2210.08590
EMNLP 2022: https://aclanthology.org/2022.emnlp-main.474/
相关报道:打破不可能三角、比肩5400亿模型,IDEA封神榜团队仅2亿级模型达到零样本学习SOTA
一、背景 Background
- 研究问题:如何在不用额外示例或微调的情况下,让小规模模型(约2亿参数)在多个语言理解任务上实现零样本推理?
- 任务背景:
- 现有的零样本方法依赖上百亿参数的大型模型(如 GPT‑3、PaLM、FLAN),成本高、推理慢、需设计大量 prompts 和 verbalizers。
- PMLM(如 BERT/ALBERT)虽然适合 NLU,但传统方式只能通过微调分类器实现,无法直接零样本推理。
- 存在“不可能三角”:模型体量小、零样本性能强、可微调性能好三者兼得非常困难。
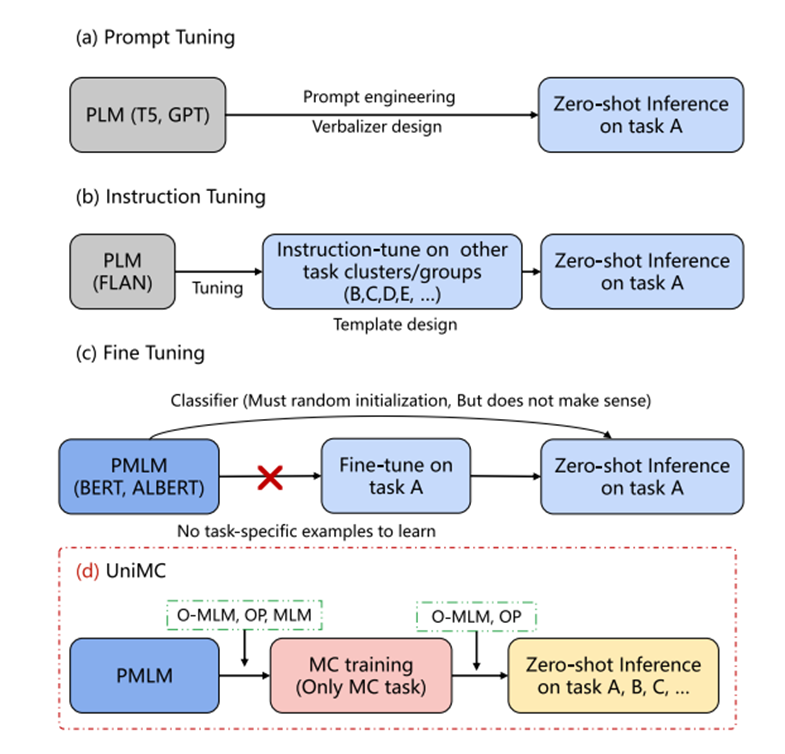
二、方法 Methods
- 核心创新:提出 UniMC,一种将各种标签型 NLU 任务统一转为 多项选择格式 的轻量级模型结构。
- 统一输入格式:将 context、question、每个标签选项拼接,并在选项前加特殊 token
[O-MASK] - 无需额外参数:复用原 PMLM 的 Mask‑LM head,无需在其上添加分类层或自回归生成头
- Option‑Masked LM (O‑MLM):预测每个
[O-MASK]是“yes”还是“no” - Option Prediction (OP):对所有选项的“yes” logits 做 softmax,最大值对应选定答案
- 统一训练与推理机制:在多项选择任务集上做 batch 训练,推理时相同机制用于零样本推理
- 统一输入格式:将 context、question、每个标签选项拼接,并在选项前加特殊 token
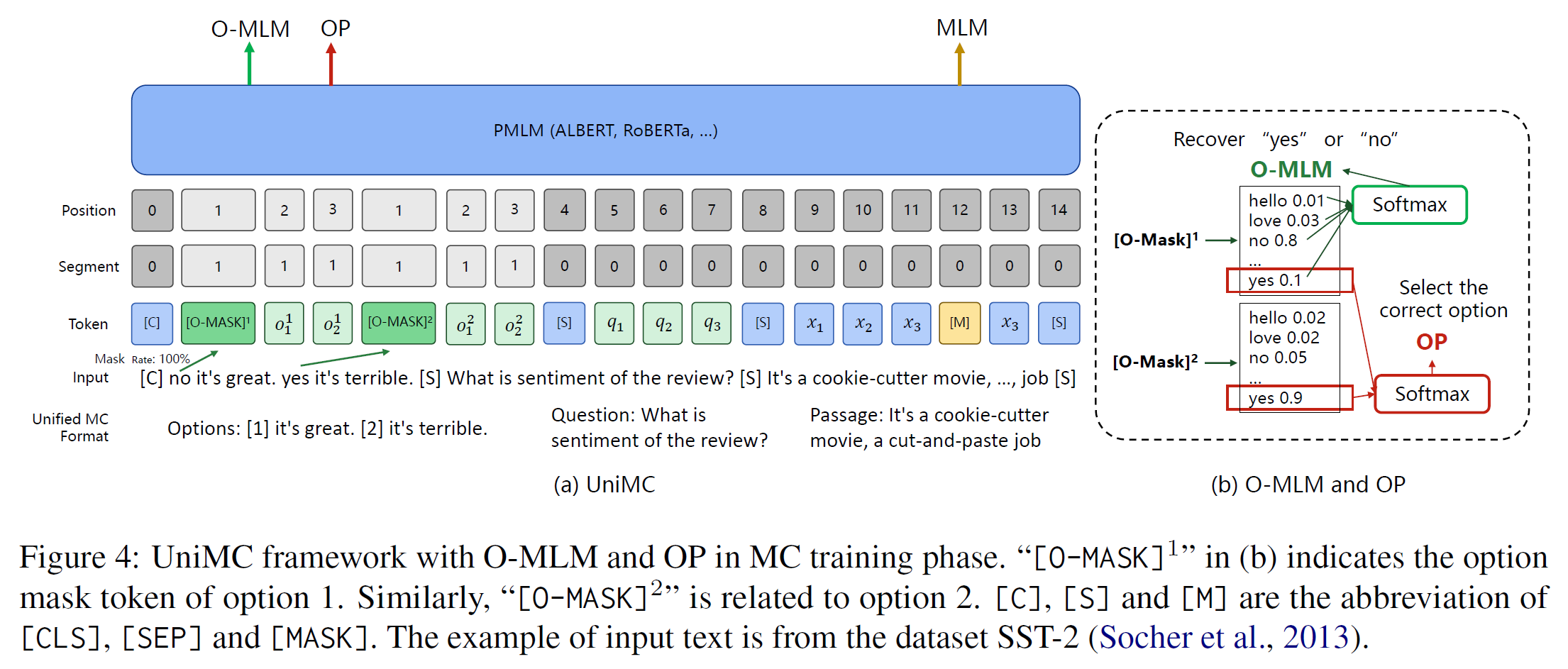
- 优点:
- 输入格式统一,减少模板设计与人工干预
- 保持训练与推理阶段一致
- 参数量小(235M),推理速度快,易部署
三、实验 Experiments
- 模型架构:基于 ALBERT(235M),在多个 MC NLU 数据集上预训练
- 训练数据:收集 14(英文)+ 40(中文)个多项选择任务,统一输入结构进行 batched MC 训练
- 评估方式:
- 英文零样本任务:自然语言推理、文本分类、常识推理与 DBpedia(多类)等任务
- 中文 FewCLUE / ZeroCLUE 数据集评测:测试中文场景下零样本和 few‑shot 推理能力
四、结果 Results
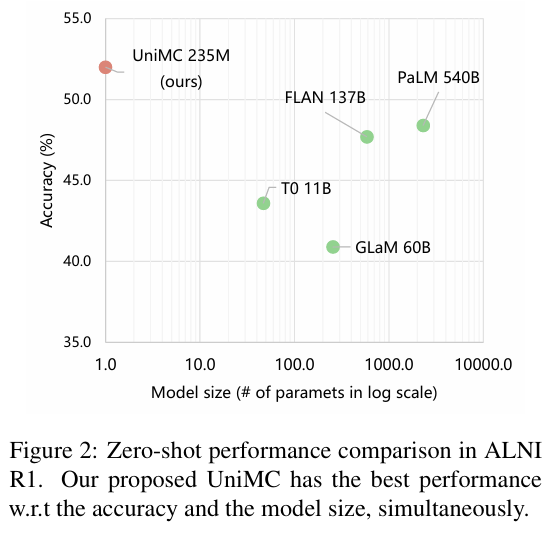
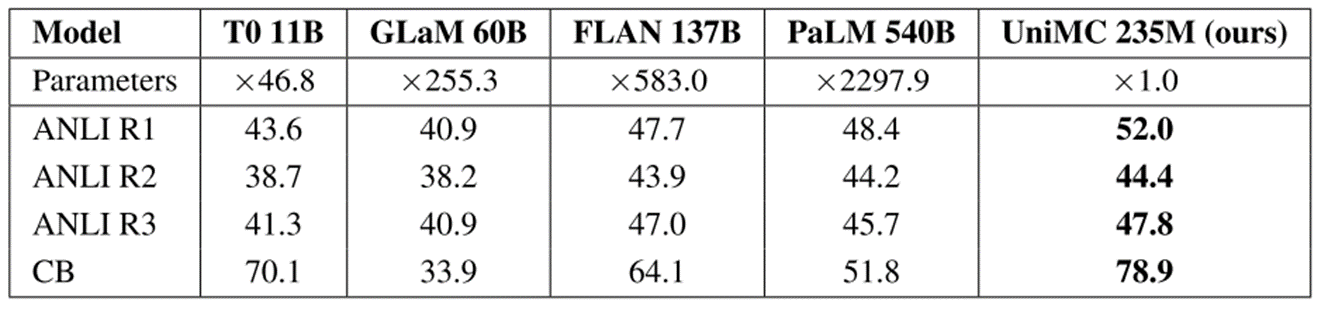
- 英文结果:
- 在多个 NLI 与分类任务上,UniMC(235M)零样本性能超过了 PaLM(540B)等千亿级模型
- DBpedia(13 类任务)中达到了 88.9% 的高准确率
- 中文结果:
- 在 FewCLUE 和 ZeroCLUE benchmark 中,UniMC(110M–1.4B 系列)达到当时榜单最高水平
- 尤其 1.3B 版本模型位列中文零样本榜首
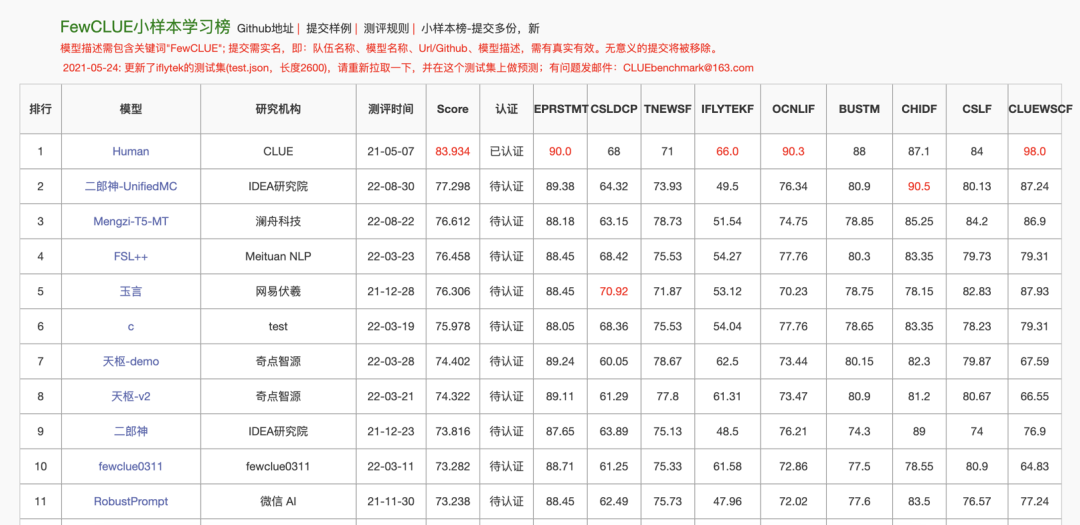
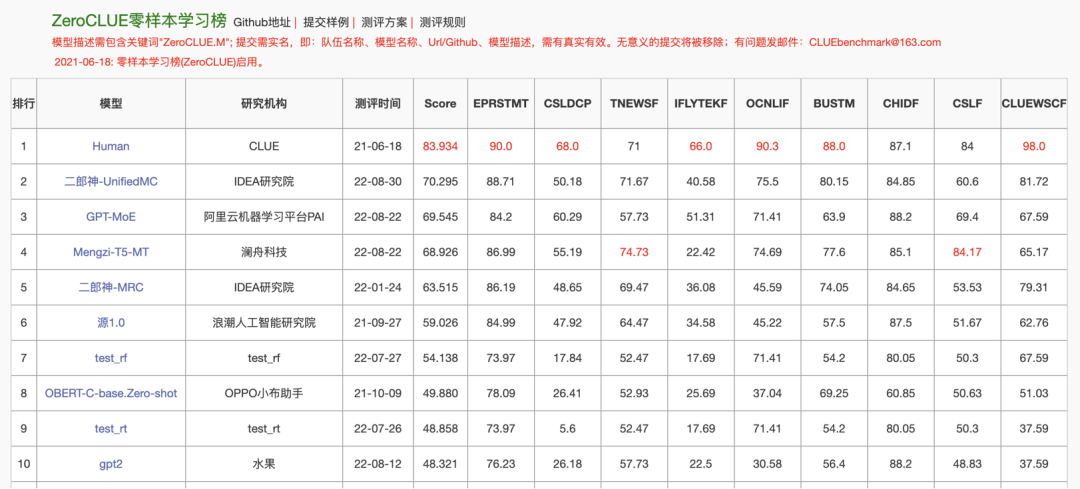
- 总体表现:
- 在几乎所有任务上优于或接近 FLAN、T0 等大型 prompt‑based 模型
- 显著减少算力成本,参数量小两至三数量级
五、总结 Conclusion
- 创新贡献:
- 提出 UniMC 框架:统一将多种 NLU 任务视为多项选择问题,通过 O‑MLM + OP 实现零样本推理
- 避免大规模生成模型的缺点,如提示模板依赖、自回归生成、参数量巨大
- 实用价值:
- 参数小、推理快、部署易,适合资源受限场景
- 不需复杂 prompt engineering 和 verbalizer 设计
- 统一训练与推理机制保证零样本性能与稳定性
- 局限与未来方向:
- 目前主要测试于 label‑based 任务,对 open‑ended 生成任务效果未验证
- 后续可扩展到更多任务格式与多语言支持
总结:
本篇论文通过将标签型语言理解任务统一建模为多项选择问题,并结合 PMLM 的掩码机制,成功实现了一个只需数亿参数、无需额外提示设计,就具备强大零样本理解能力的轻量级模型范式——UniMC。这一方法从根本上打破了“大模型、提示、性能”之间的传统权衡,具有重要的理论价值与工程应用潜力。