[ACL 2023] UniEX: An Effective and Efficient Framework for Unified Information Extraction via a Span-extractive Perspective
Published in ACL, 2023
关键词
- 信息抽取 / Information Extraction
- 跨任务统一 / Unified Across IE Tasks
- 跨任务跨度抽取 / Span‑extractive Framework
- 三重注意力机制 / Triaffine Attention
- 低资源迁移 / Low‑resource Transferability
- Prompt 联合编码 / Prompt‑aware Encoding
Arxiv地址:https://arxiv.org/abs/2305.10306
ACL 2023: https://aclanthology.org/2023.acl-long.907/
背景(Background)
- 信息抽取(IE)包括命名实体识别、关系抽取、事件抽取、情感分析等多种子任务。
- 目前主流方法多为任务专用模型,结构独立,效率较低,缺乏通用性。
- 近年来尝试用生成式统一模型(如 UIE、T5-based)实现跨任务 IE,但推理速度较慢且性能不稳定。
- 本论文针对以上痛点,提出一种统一、高效且兼具性能表现的抽取式统一 IE 框架——UniEX。
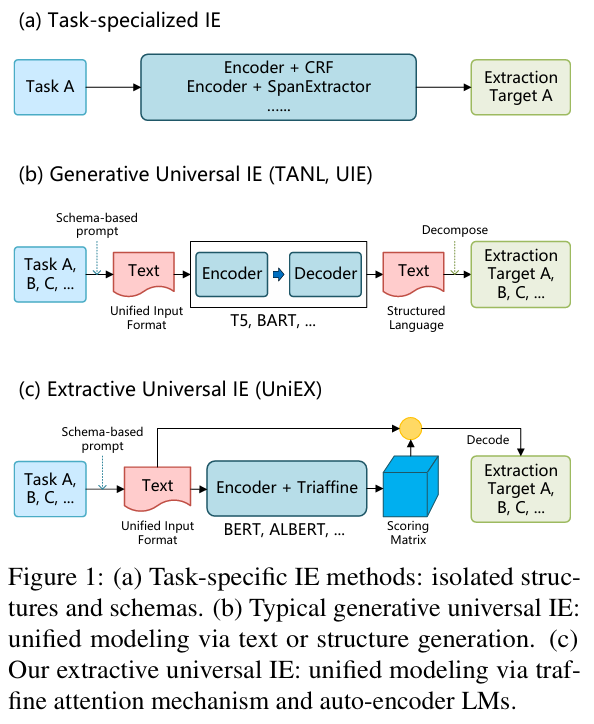
方法(Methodology)
框架概览
- 将多种 IE 任务统一视作 token-pair 问题,即对文本中所有 token 对进行分类与关联。
- 引入统一的 Prompt + 文本 输入方式,让模型可同步编码 schema 信息和正文信息。
- 输出通过 span 检测、分类、关联三个步骤得到最终抽取目标。
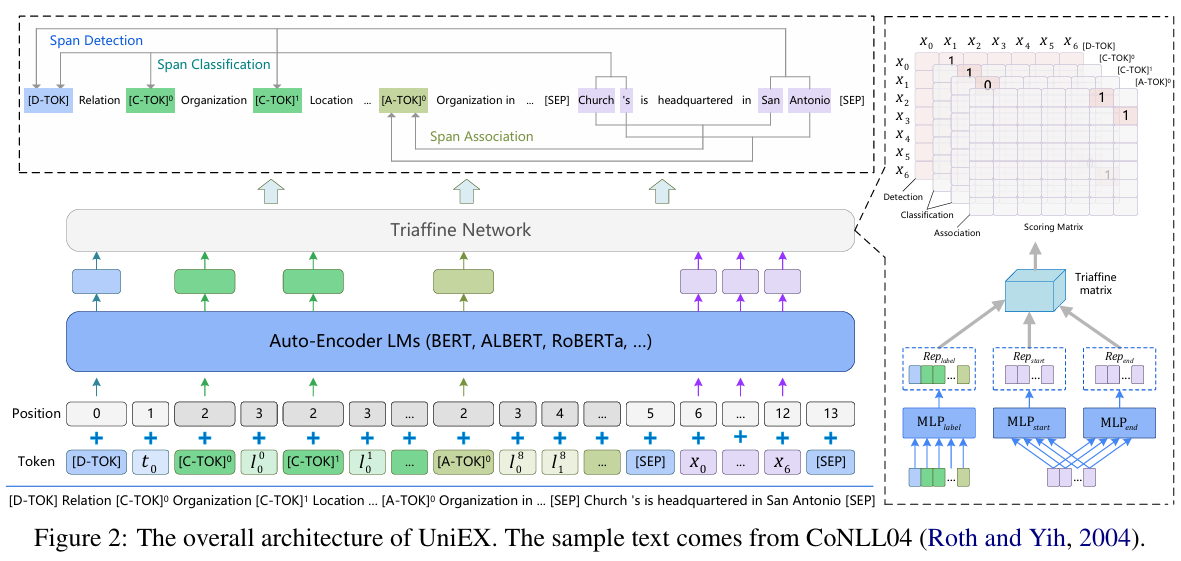
Prompt-aware 编码
- 针对每个任务与 schema,将其组织为一个 prompt,补充在文本输入之前,实现任意可定义 schema 的处理。
Triaffine 注意力机制
- 设计一种融合任务、标签、token 跨三维关系的专用注意力;可视为 triaffine 形式的 scoring 机制,用于构建 token-pair 打分矩阵。
抽取式解码
- 在训练过程中生成一个二维矩阵,代表所有 token-pair 的置信得分。
- 最终通过筛选高分 token-pair 得到实体跨度、实体类型、关联关系等信息。
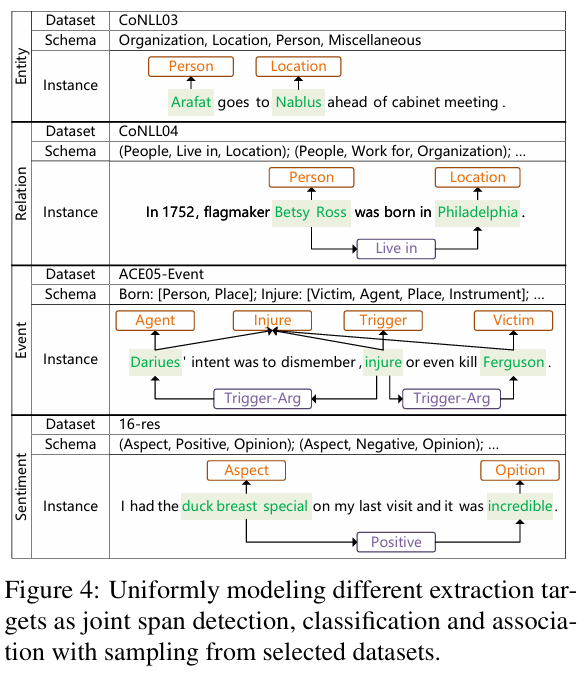
实验设计(Experimental Setup)
数据集与任务
- 覆盖 4 种主要 IE 任务,14 个 benchmark 数据集,包括 CONLL03、ACE04/05、GENIA(实体识别);CONLL04、ACE05-RE 等(关系抽取);事件抽取数据;情感分析等。
- 包括多个领域、语言、格式(平坦实体、嵌套实体、实体+关系)场景。
对比 baselines
- 与生成式统一 IE 模型(如 TANL、UIE 等)比较,并加入标准的监督任务专用模型作为对比组。
实验设定
- 在完全监督设置下验证性能;并在低资源场景(少量训练样本)评估迁移能力。
- 测量指标包括精度、召回率、F1,以及推理速度(效率评估)。
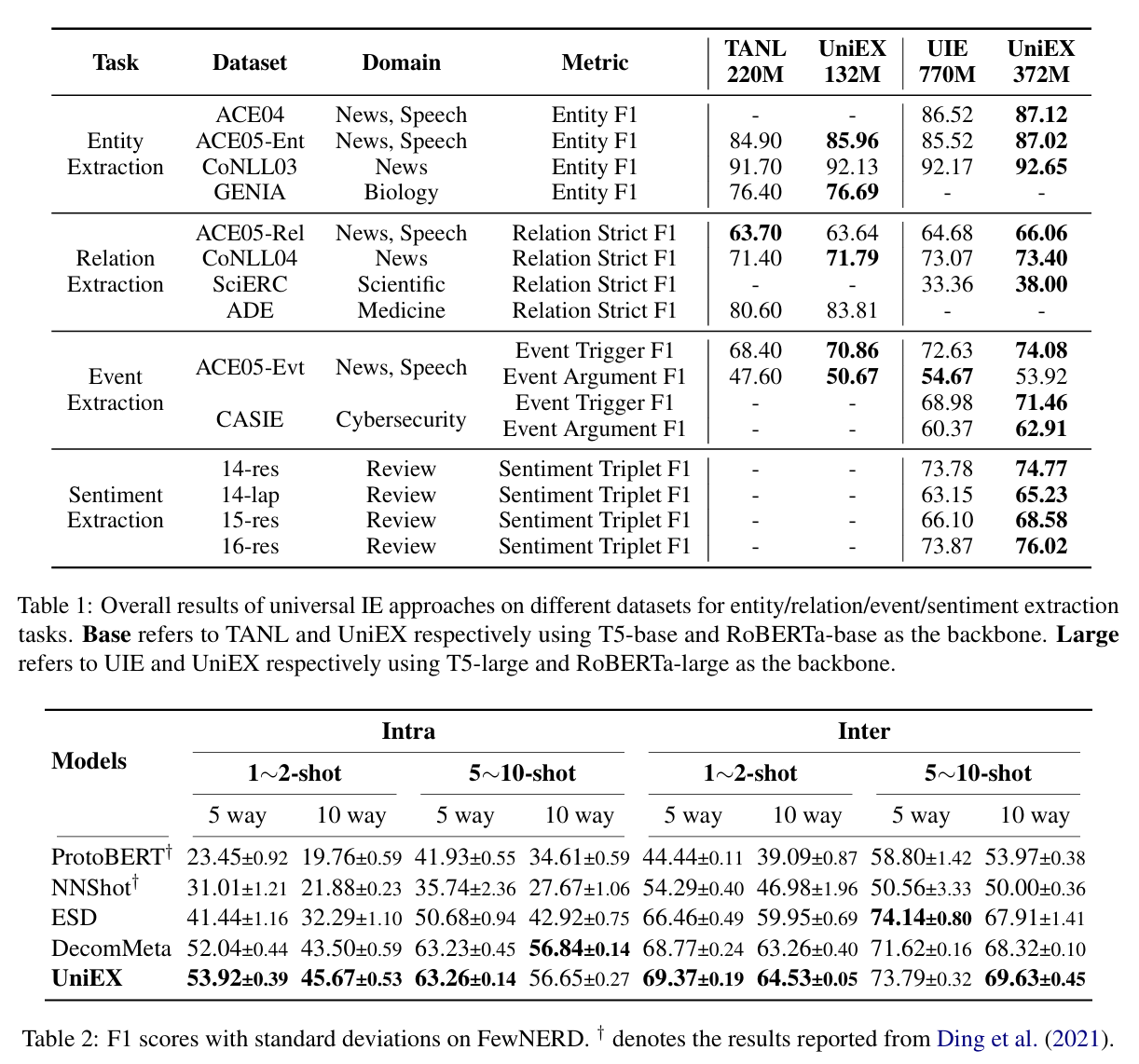
结果(Results)
- 在所有 14 个基准测试中, UniEX 较生成式模型表现出更高的 F1 分数:
- 性能提升普遍、稳定,实体/关系抽取任务中尤为明显。
- 推理速度显著快于生成式模型,因为一次性计算 token-pair 矩阵,而非逐项解码。
- 低资源实验表明,UniEX 在少量训练样本下仍维持强迁移能力,性能下降缓慢。
总结(Conclusion)
- 提出 UniEX:一个统一、高效、可扩展的信息抽取框架。
- 它通过 token-pair 抽取、prompt-aware 编码、triaffine 注意力等机制,有效将多任务统合。
- 实验全面验证:在多任务多数据集上均超越生成式统一 IE 方法,不仅性能优,更推理快、扩展性强。
- 特别适用于低资源场景,展现良好迁移能力。
- 为未来跨任务、跨领域、高效信息抽取奠定经典架构基础。