RoCo Challenge @ AAAI 2026 冠军:ARC-VLA(Anchor & Recovery Curriculum)
官方主页:https://rocochallenge.github.io/RoCo2026/
赛事:RoCo Challenge @ AAAI 2026 — Robotic Collaborative Assembling for Human-Centered Manufacturing
团队:IIGroup(Tsinghua University)
成绩:初赛第 3|决赛第 1(冠军,First Place Award)

RoCo Challenge @ AAAI 2026 — First Place Award
1. 赛事背景与任务设定(RoCo 2026)

RoCo(Robotic Collaboration)面向人机协作制造中的真实装配需求,强调“人类参与导致的非理想初始状态”和“错误恢复”对部署鲁棒性的决定性影响。RoCo 2026 以gearbox assembly为核心场景,围绕三类代表性任务构建评测闭环:
- Assembly from Scratch:从空工作台开始,完成完整装配流程。
- Resume from Partial State:从部分装配状态继续执行,要求准确状态理解与续装策略。
- Error Detection & Recovery:识别并修复“人类式失误/扰动”后恢复装配,要求错误诊断与闭环恢复能力。

赛事包含线上仿真阶段与现场真机阶段(sim-to-real finals),以统一指标评估跨阶段可迁移性与稳定性。
2. 成绩
- Online (Preliminary) 排名:第 3 名
- Onsite (Final) 排名:第 1 名(冠军)
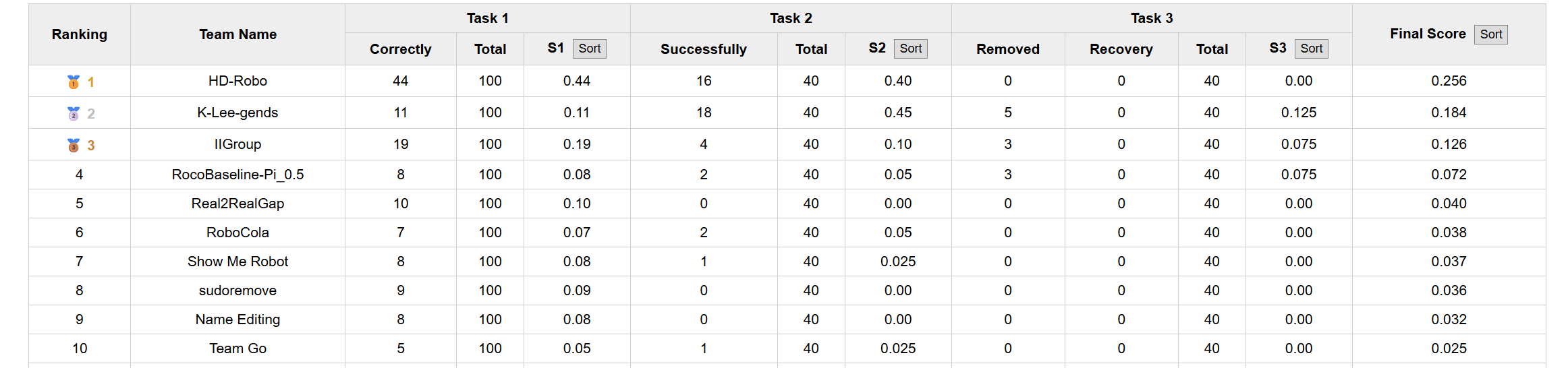
Preliminary leaderboard (online): Rank #3
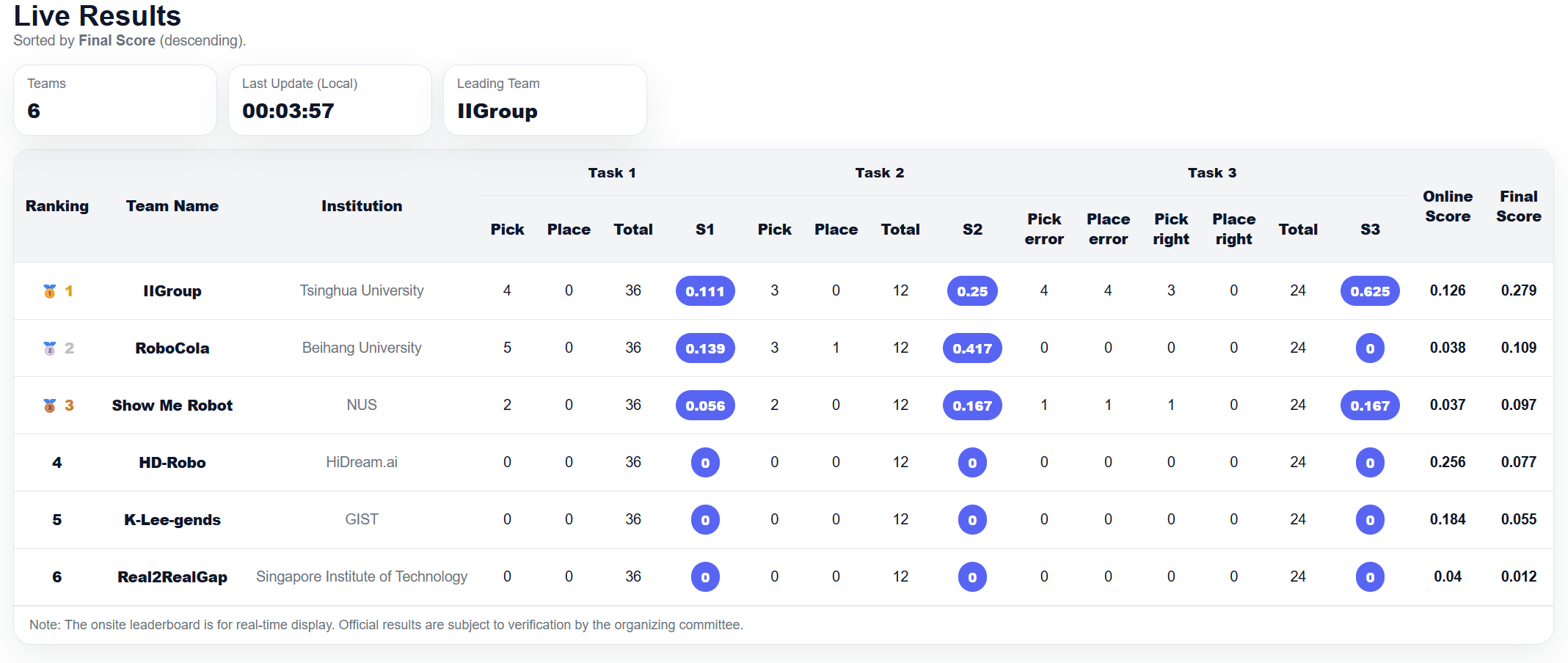
Final leaderboard (onsite): Rank #1
3. 方法总览:ARC-VLA(Deployability-First)
我们提出 ARC-VLA:Anchor & Recovery Curriculum for Vision-Language-Action,将目标从“仿真中完成任务”前移为“真实部署可用(deployable competence)”。核心观点是:sim-to-real 的主要失败往往来自静默失配(silent mismatch)、脆弱性(brittleness)与过度校准(over-calibration),尤其在传感噪声、光照变化与微小装配偏移下被放大。
ARC-VLA 采用“Deployability → Capability → Stability”的设计顺序,并通过三大支柱(Pillars)形成可复现的端到端闭环,最终产出一个统一的任务条件策略,同时覆盖 Scratch / Resume / Recover。
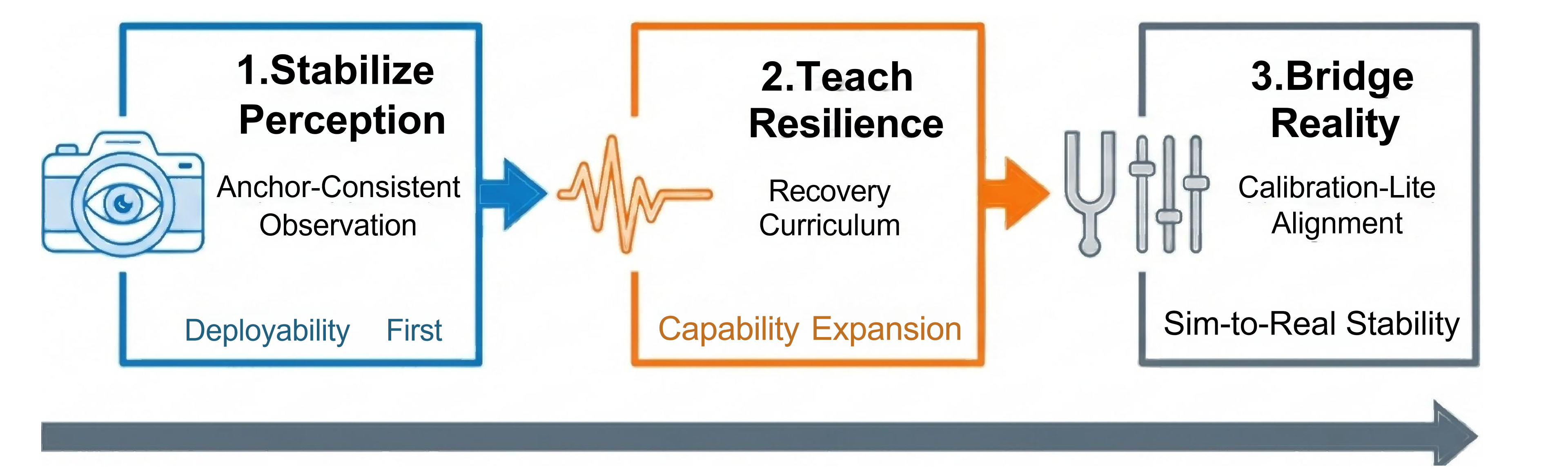
4. 架构选择:π0.5 作为 VLA Backbone
我们选择 π0.5 作为整体 VLA 框架的主干,其动机是:
- Open-World Generalization:面向开放世界的泛化能力;
- Efficient End-to-End Architecture:端到端执行的效率与工程可落地性。
结构上采用:
- Vision Encoder(SigLIP)
- VLM Backbone(Gemma)
- Action Expert(动作专家头/执行模块)
5. 三大支柱(Pillars)
Pillar I:Anchor-Consistent Observation(稳定感知)
面向部署的一致性优先:将影响闭环稳定的观测环节“锁定(LOCKED)”,降低跨域与跨阶段漂移。
- 多视角观测:Head camera + Wrist camera
- 部署清单(Checklist):
- 输入分辨率固定:224×224(LOCKED)
- 裁剪策略固定:Center-Fixed(LOCKED)
- 归一化统计(Norm stats)一致化
- 关键话题/任务设置验证(Topic Selection: Verified)
目标:把“看见什么”变成可控变量,避免策略在真实噪声下被输入漂移击穿。
Pillar II:Recovery Curriculum(恢复课程的数据编程)
仅靠成功轨迹会导致“看似完成、但不可部署”的策略。我们在仿真阶段显式加入结构化失败样本,训练策略学会“重置与重试(reset & retry)”。
- Sim Stage:600 episodes(Success + Recovery)
- Real Stage:400 alignment episodes(Finetuning)
- 核心原则:用结构化失败增强标准成功轨迹,形成可控的恢复技能分布。
恢复类型(Recovery Taxonomy)
- Type 1: Perturb-and-Correct
- 场景:位置偏移(position offsets)
- 行为:on-the-fly correction(在线纠偏)
- Type 2: Fail-and-Reset
- 场景:抓取失败(grasp failure)
- 行为:Lift → Retreat → Retry(抬起-撤退-重试)
目标:把“恢复”从偶发技巧变为被系统性教授的能力。
Pillar III:Calibration-Lite Alignment(轻量对齐,稳定部署)
完整几何标定成本高且脆弱。我们采用 Calibration-Lite:只对齐那些会破坏闭环稳定的最小集合。
- Start-Segment Sanitization:移除静态前缀(removes static prefixes)
- Temporal Chunking (K):作为稳定性旋钮,抑制动作振荡
- Joint Mapping:确定性符号约定(deterministic sign convention)
- 对齐目标:仅对齐 Normalization Stats 与 Motor Signs 等关键因素
目标:以最小可行对齐代价获得最大闭环稳定收益。
6. 两阶段训练协议(Sim → Real)
为保证跨阶段一致性,我们采用两阶段训练并保持观测管线锁定:
- Stage A:Simulation “Pre-Tuning”
- 600 episodes(mixed success + recovery)
- 目标:学习装配逻辑与恢复课程
- Stage B:Real-Robot Alignment Finetuning
- 400 real episodes
- 目标:适配真实动力学与传感噪声
- Transfer:从 Sim 向 Real 迁移权重(Sim-to-Real knowledge transfer)
- 关键约束:Observation pipeline 在两阶段保持 LOCKED,确保可复现与一致性