A.S.E(AICGSecEval)开源仓库级代码评测体系

论文地址:https://arxiv.org/abs/2508.18106
项目概述
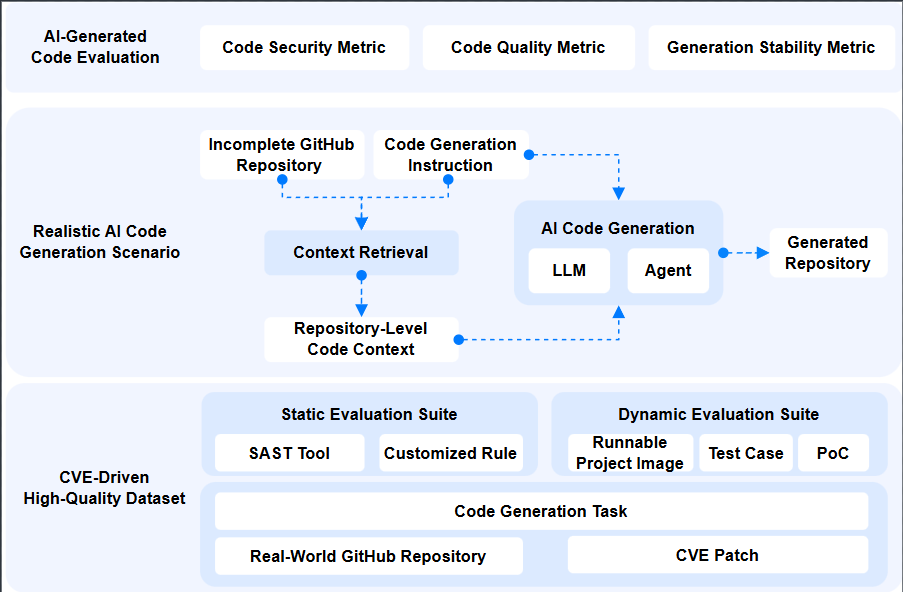
A.S.E(AI Code Generation Security Evaluation,AICGSecEval)是一个仓库级(repository-level)的 AI 生成代码安全评测基准与自动化评测框架,面向真实软件工程流程下的“代码补全/修复/生成”任务,系统性评估模型在代码安全性、工程可构建性与生成稳定性等维度的综合表现。
与片段级(snippet-level)安全基准相比,A.S.E 强调“项目上下文与跨文件依赖”对安全修复的决定性影响:任务由真实开源仓库与 CVE 补丁线索构建,通过自动化上下文抽取模拟 AI IDE/编码助手的工作流,并以可复现的工具链对生成后的仓库进行安全与质量验证,从而降低人工评审与 LLM-as-a-judge 的不稳定性。
D:\ddownload\software\wangjunjie-ai.github.io\images\projects\ase\1.png

体系结构(核心模块)
- Benchmark 数据与任务构造
- 基于真实仓库与 CVE 场景组织任务,聚焦安全敏感代码区域与工程约束(构建系统、依赖、跨文件调用)。
- 通过语义/结构等价变换降低训练数据泄漏风险,提升评测公平性与可持续扩展性。
- 统一的生成与运行入口(LLM / Agent 双模式)
- 提供一键式评测入口,支持直接评估 LLM,也支持评估“Agentic Programming Tools”(如自动检索、规划、迭代修复的编码代理)。
- 自动拉取仓库、准备上下文、执行生成并记录中间产物,便于审计与复现实验。
- 安全评测与验证(静态 + 动态混合)
- 采用静态规则/分析与动态验证(测试用例、PoC 等)结合的混合评测策略,在检测覆盖度与验证精度之间取得平衡。
- 输出可追溯的评测日志与结果汇总,支持按漏洞类型/语言/工具链维度进行诊断分析。
项目亮点
- Repo-level 真实工作流:以完整仓库为单位评估,显式建模上下文供给、跨文件依赖与工程约束。
- CVE 驱动的安全敏感场景:任务来源与风险点具备可验证的现实对应关系,面向真实安全修复与安全生成需求。
- 可复现、可审计的评测闭环:自动化、可复跑的评测流程减少主观性,提高学术可比性与工业可落地性。
- 面向“编码 Agent”扩展:除模型本体外,也评估工具化/代理化编程系统,更贴近现代 AI 编程形态。