封神榜开源体系

论文地址:https://arxiv.org/abs/2209.02970
项目概述
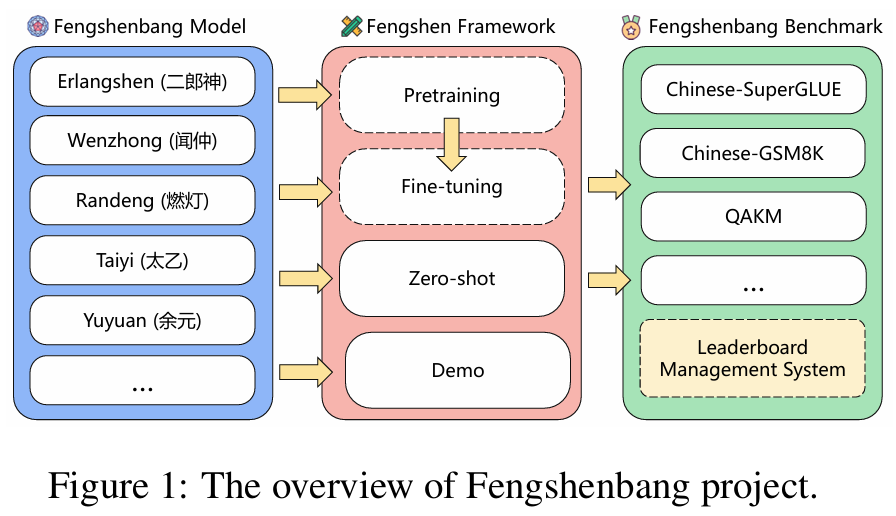
封神榜(Fengshenbang) 是由 IDEA‑CCNL(IDEA研究院认知计算与自然语言研究中心)主导的一项中文大模型开源体系,旨在成为中文认知智能与AIGC(生成式AI)基础设施。项目包括三大模块:
Fengshenbang Model(模型体系)
提供丰富的预训练大模型,以应对通用自然语言理解(NLU)、生成(NLG)、转换(NLT),以及多模态、领域专用等多场景需求。
- Erlangshen(二郎神)系列
- 面向自然语言理解(NLU)任务。
- 代表模型如 Erlangshen-MegatronBert-1.3B,是当前社区最大规模的中文 BERT 结构模型,广泛应用于分类、抽取等任务。
- Wenzhong(闻仲)系列
- 面向自然语言生成(NLG)任务。
- 代表模型如 Wenzhong-GPT2-110M、Wenzhong2.0-GPT2-3.5B,适用于写作、对话等文本生成场景。
- Randeng(燃灯)系列
- 面向自然语言转换(NLT)和序列到序列生成任务。
- 代表模型如 Randeng-T5-784M/1.0B,可用于文本摘要、翻译、问答等。
- Taiyi(太乙)系列
- 中文多模态(文本-图像)生成模型。
- 包括 Taiyi-Stable-Diffusion-1B-Chinese-v0.1,是国内首个发布的中文 Stable Diffusion 模型,具备高质量中文语义图像生成能力。
- Ziya(子牙)系列
- 通用大模型与通用人工智能(AGI)探索。
- 代表如 Ziya-LLaMA-13B-Pretrain 和 Ziya-LLaMA-13B-Chat,支持中英双语、对话、多任务等功能。

Fengshen Framework(训练框架)
- 封神框架建立在 PyTorch/PyTorch‑Lightning/DeepSpeed 上,提供分布式预训练与下游微调支持,兼容 HuggingFace 模型结构,支持低成本训练、显存优化、Docker 环境和丰富 pipeline 脚本。
Fengshenbang Benchmark(评测体系)
提供标准化评测套件与 leaderboard,覆盖 CLUE、SuperGLUE 等中文 benchmark,实现模型性能对比与迭代跟踪。
项目亮点
- 开源友好:模型、代码和评测全部开源,采用 Apache-2.0 许可,便于学界和工业界广泛应用和二次开发。
- 生态闭环:从模型预训练、微调到评测、部署,形成全流程一体化开发环境。
- 中文优化:专为中文语料和任务设计,采用多种中文特有预训练策略,如全词掩码、知识动态掩码等。
- 多模态与多领域:兼容文本、图像等多种数据模态,覆盖通用与行业垂直需求。
- 社区协同:鼓励开发者、企业和学界共同参与,持续推动中文认知智能基础设施发展。
代表性成果
- 封神榜 1.0 论文发表于 2022 年,提出系统的中文大模型开源路线。
- Erlangshen-MegatronBert-1.3B、Wenzhong-GPT2、Randeng-T5 等模型成为中文预训练模型基准。
- Taiyi-Stable-Diffusion 发布,填补中文语义图像生成领域空白。
- 多款模型在 CLUE、SuperGLUE 等评测集上取得领先成绩。
参与的相关封神榜开源模型
太乙系列 - 多模态模型
多模态基础模型
Taiyi-vit-87M-D:COCO和VG上特殊预训练的,英文版的MAP(名称暂定)的视觉端ViT-base。
Taiyi-Roberta-124M-D:COCO和VG上特殊预训练的,英文版的MAP(名称暂定)的文本端RoBERTa-base。
Taiyi-Roberta-124M-D-v2:使用了1M图文对进行特殊预训练的,英文版的MAP(名称暂定)的文本端RoBERTa-base。
Taiyi-CLIP-Roberta-102M-Chinese:中首个开源的中文CLIP模型,1.23亿图文对上进行预训练的文本端RoBERTa-base。
Taiyi-CLIP-Roberta-large-326M-Chinese:首个开源的中文CLIP模型,1.23亿图文对上进行预训练的文本端RoBERTa-large。
Taiyi-CLIP-RoBERTa-102M-ViT-L-Chinese:首个开源的中文CLIP模型,1.23亿图文对上进行预训练的文本端RoBERTa-base
Taiyi-CLIP-RoBERTa-326M-ViT-H-Chinese:首个开源的中文CLIP模型,1.23亿图文对上进行预训练的文本端RoBERTa-large。
多模态文生图模型
Taiyi-Diffusion-532M-Cyberpunk-Chinese:该模型由Katherine Crowson’s的无条件扩散模型在1k+张收集的赛博朋克风的图上微调而来。结合IDEA-CCNL/Taiyi-CLIP-Roberta-large-326M-Chinese可以实现中文Guided Diffusion的生成方式。
Taiyi-Stable-Diffusion-1064M-Chinese-v0.1:首个开源的中文Stable Diffusion模型,基于0.2亿筛选过的中文图文对训练。
Taiyi-Stable-Diffusion-1B-Chinese-EN-v0.1:首个开源的中英双语Stable Diffusion模型,基于0.2亿筛选过的中文图文对训练。
Taiyi-Diffusion-532M-Nature-Chinese:该模型由Katherine Crowson’s的无条件扩散模型在1k+张收集的自然风景图上微调而来。结合IDEA-CCNL/Taiyi-CLIP-Roberta-large-326M-Chinese可以实现中文Guided Diffusion的生成方式。
二郎神系列 - 统一的NLP模型
UniMC 核心思想是将自然语言理解任务转化为 multiple choice 任务,并且使用多个 NLU 任务来进行预训练。我们在英文数据集实验结果表明仅含有 2.35 亿参数的 ALBERT模型的zero-shot性能可以超越众多千亿的模型。并在中文测评基准 FewCLUE 和 ZeroCLUE 两个榜单中,13亿的二郎神获得了第一的成绩。
Erlangshen-UniMC-RoBERTa-110M-Chinese
Erlangshen-UniMC-MegatronBERT-1.3B-Chinese
Erlangshen-UniMC-Albert-235M-English
Erlangshen-UniMC-DeBERTa-v2-110M-Chinese
Erlangshen-UniMC-RoBERTa-330M-Chinese
Erlangshen-UniMC-DeBERTa-v2-330M-Chinese
配套:太乙绘画使用手册
发布时间:2022.11.21
地址:https://docs.qq.com/doc/DWklwWkVvSFVwUE9Q
