最大的开源的交错图文对数据集:PIN
📘 项目概述
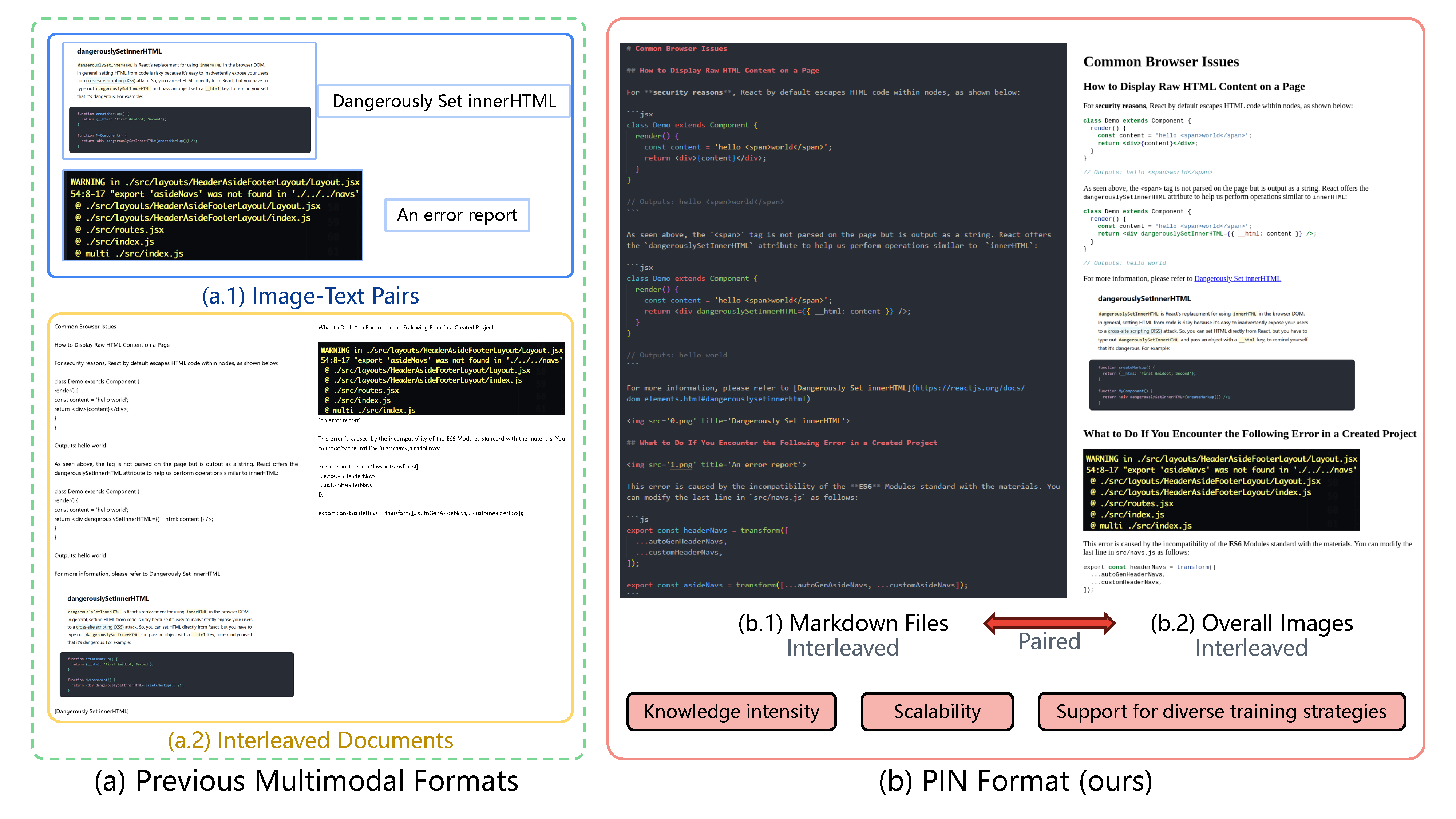
PIN(Paired and INterleaved multimodal documents)是一种新颖的多模态数据集格式,旨在提升大型多模态模型(LMM)在知识密集场景下的感知与推理表现。
论文链接:https://arxiv.org/abs/2406.13923
它基于三个核心设计原则:
- 知识密集:结合图文、科学内容、图表等复杂元素,增强语义结构深度。
- 可扩展:提供统一数据格式与处理流程,可将现有多模态数据集转换为 PIN。
- 多样训练:支持图文对齐训练与交错训练,可基于 Markdown 文本预测图像或从图像提炼知识。
✅ 数据集发布
PIN‑14M
- 包含约 1,410 万 样本,涵盖中文与英文内容,共计约 7.33B token。
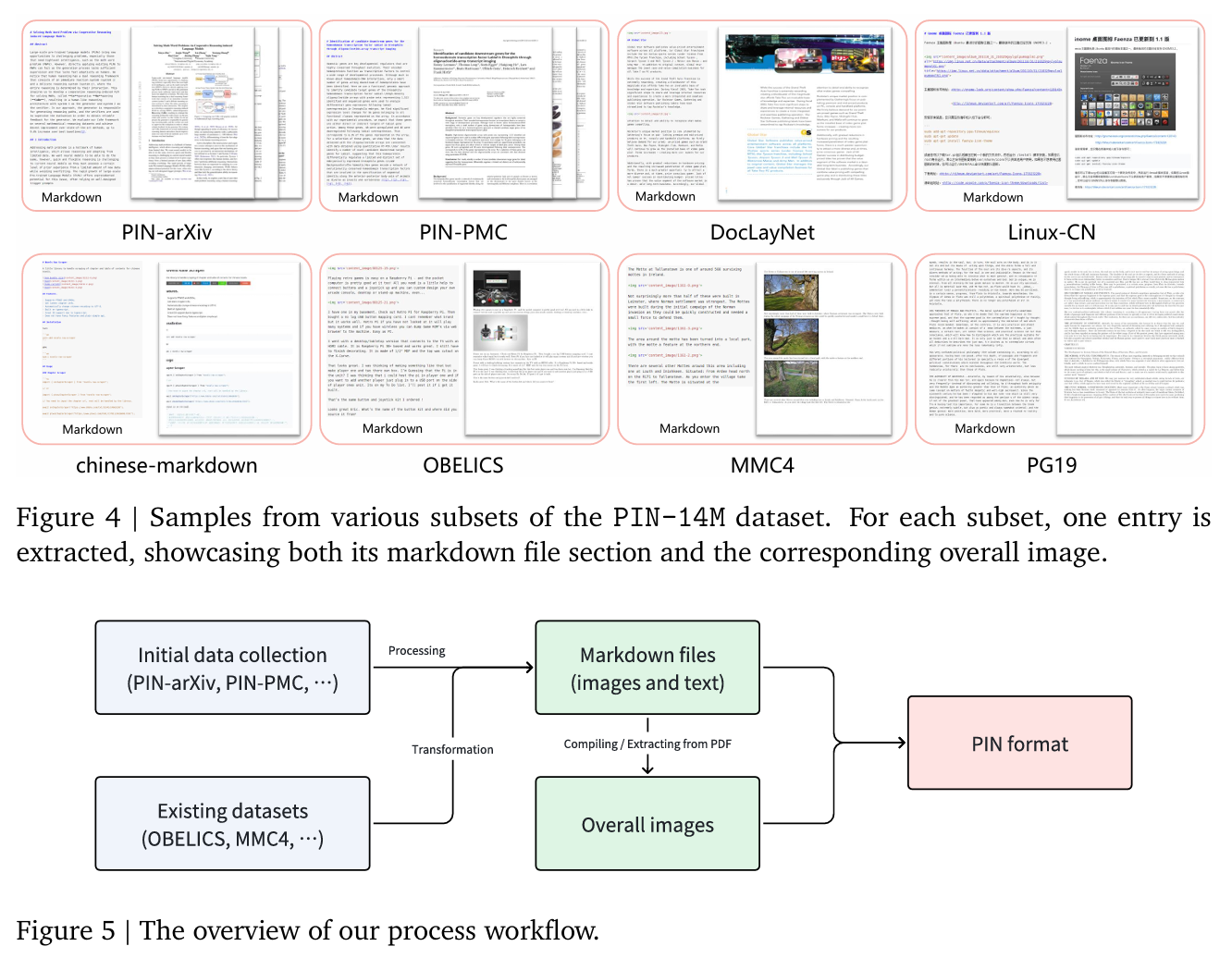
- 覆盖多样子集,如 PG19、OBELICS、MMC4、DocLayNet、LeetCode、Linux-CN、PIN-PMC 等,提供 markdown 文本、content 图与 overall 整体图。
- 附带“质量信号”(quality signals),便于研究者根据质量筛选样本。
- Hugging Face 地址:PIN-14M 数据集
PIN‑100M
- 目标数据体量为 1 亿 样本,存储需求超过 150TB。
- 当前仍在持续构建中,已提前发布部分内容,由于 Hugging Face 存储限制,仍在补充数据中。
- Hugging Face 地址:PIN-100M 数据集
🔧 数据构建流程
以子集为例展示 PIN 的处理流程:
PIN‑arXiv(科学论文):
- 收集 PDF + source code → 使用 Engrafo 转 HTML,再转换 markdown。
- 使用 parser 恢复图像、表格等视觉信息。
- 将每页 PDF 转为 overall 图像,最终生成 markdown + 整体图的 PIN 样本。
- 生成超百万规模数据。
PIN‑PMC(医学文献):
- 从 XML 提取结构化内容、图表及参考。
- 合并为 markdown + 对应整体图。
其他来源如 DocLayNet、Linux-CN、chinese-markdown、OBELICS、Web 页面,均采用类似流程:markdown 渲染 → 截图 → 配对生成 PIN 格式样本。
📚 项目价值与应用前景
- 提升 LMM 能力:通过高密度知识结构与图文 + 图文交错训练,增强模型对图表、图像中隐含意义的理解和推理能力。
- 统一格式:PIN 提供标准化流程,适配多源数据,便于未来学术研究与预训练任务。
- 开放生态:PIN‑14M 已开源,附带数据质量指标;PIN‑100M 正在扩展中,是未来大型模型训练的重要资源。
🧭 未来规划
- 正式发表更深入技术评估论文。
- 丰富 PIN‑100M 子集,目标全面覆盖。
- 持续发布质量信号、子集及流程工具。