Open‑Sora

技术报告:report
🎥 Open-Sora 1.1 项目介绍
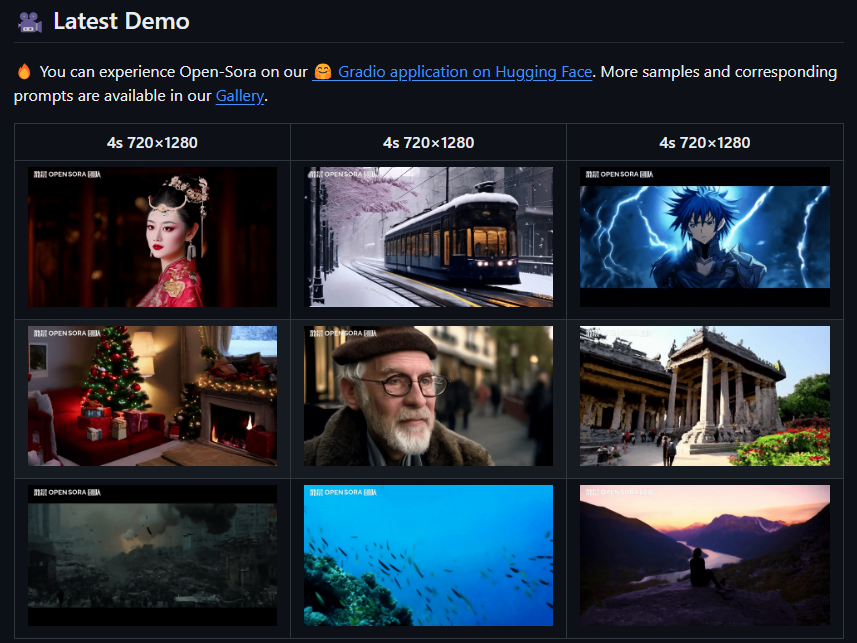
Open-Sora 1.1 是一个高效、开放的视频生成平台,专注于实现灵活且高质量的视频生成和编辑功能。1.1版本在1.0基础上进行了关键的优化,包含:
- 多尺度训练策略:支持多种分辨率、视频长度、宽高比的训练。
- 图像与视频统一建模:采用统一的mask策略以实现多种视频生成与编辑任务。
- 数据预处理流程完善:确保高质量的数据输入,提升生成效果。
- 架构与编码器优化:通过ST-DiT模型和QK归一化提高训练效率和稳定性。
- 多阶段训练流程:从低分辨率到高分辨率的逐步优化,显著提升模型效果。
📌 数据处理流程(Data Processing)
数据集的质量与规模对模型表现起到至关重要的作用,因此我们构建了自动化的数据处理流程:
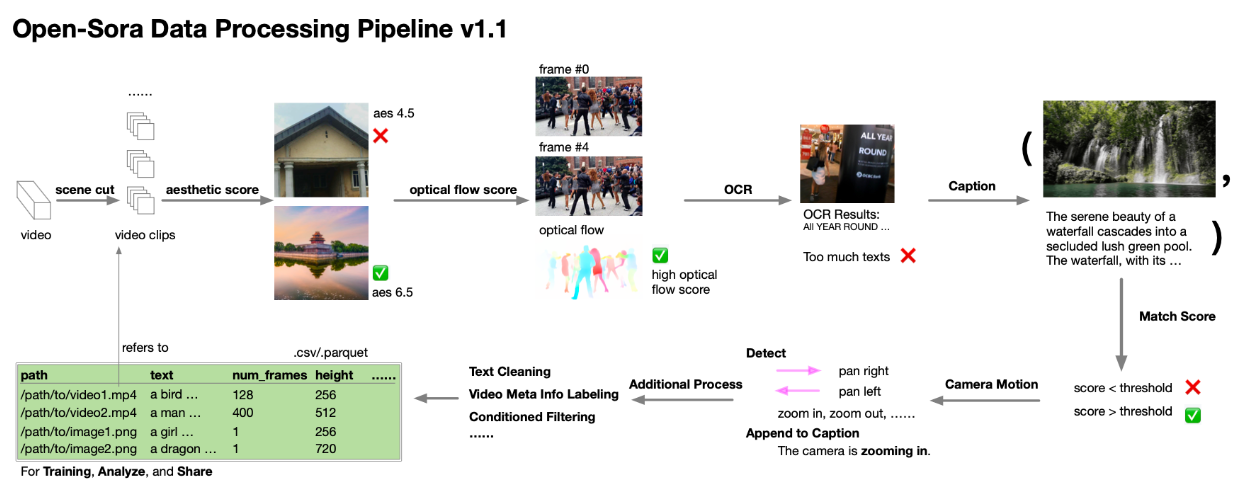
- 场景剪辑:自动提取独立且连续的视频片段。
- 美学评分过滤:去除低质量和视觉美感较差的视频。
- 光流分数过滤:评估视频的运动平滑性,去除运动异常或抖动明显的视频。
- OCR文本过滤:检测并排除含有大量文本(如字幕或水印)的场景。
- 字幕生成与匹配分数过滤:自动生成视频字幕并评估匹配度,去除内容不一致的视频片段。
- 其他辅助处理:包括文本清理、元数据(meta)标注,确保数据一致性。
上述流程极大提高了数据质量和可用性,保障了模型的高效训练。
准备了10M数据集,最终使用9.7M视频和2.6M图片进行预训练,560k视频和1.6M图片进行微调。
最终视频长度:
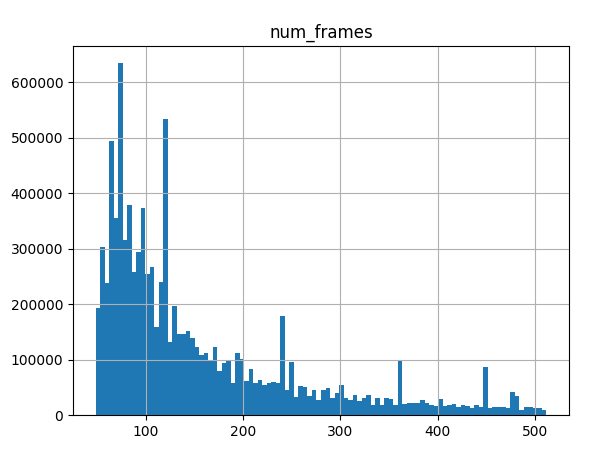
大部分视频集中在36-256帧。
🚀 训练流程(Training Procedure)
训练过程采用多阶段策略,以逐步优化模型的性能:
第零阶段(初始化微调)
- 基于Pixart-alpha-1024检查点迁移学习。
- 使用不同分辨率的图像微调6000步。
- 引入扩散模型训练加速工具SpeeDiT进行优化。
第一阶段(低分辨率预训练)
- 最初使用梯度检查点技术,发现训练速度偏慢。
- 通过减少批次大小并取消梯度检查点,增加了总训练步数。
- 训练分辨率为240p和144p。
- 引入QK-归一化稳定训练,增加遮罩比率至25%。
- 总步数为81000步,使用64个H800 GPU训练约一周。
第二阶段(中高分辨率优化)
- 提升分辨率到240p和480p。
- 在所有预训练数据上训练22000步,耗时一天。
第三阶段(高分辨率精细微调)
- 提高训练分辨率至480p和720p。
- 使用精选高质量数据训练4000步。
- 加载上一阶段优化器状态,加速训练。
- 训练耗时一天,显著提高视频生成质量。
🔮 总结与展望
Open-Sora 1.1通过精细化的数据处理、创新的训练策略和优化的模型结构,显著增强了视频生成的效果和灵活性。后续版本计划持续优化模型质量、提升审美效果,并进一步扩展其视频编辑能力,为开源视频生成领域提供更强有力的支持。
