YUE开源音乐大模型
YuE: Scaling Open Foundation Models for Long-Form Music Generation

论文地址:https://arxiv.org/abs/2503.08638
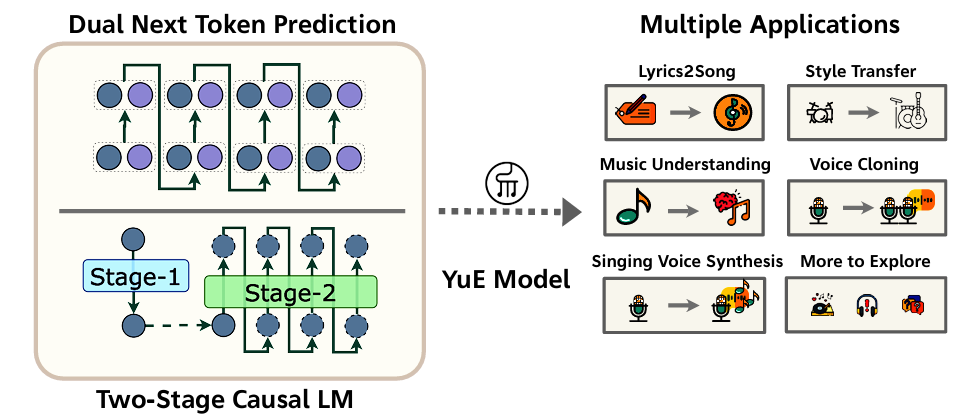
对比suno的开源模型YuE(乐),基于 LLaMA2 架构,专注于长篇音乐生成,尤其是歌词到歌曲的难题,能够生成高达五分钟的音乐并保持歌词对齐和音乐结构的连贯性。
任务背景与目标
核心任务 :论文瞄准 “lyrics-to-song”(歌词生成完整歌曲)的难题,要求模型在最长达 5 分钟的音乐上下文中,同时生成 歌词对齐的人声 和 伴奏。这是一个高挑战的长上下文、多模态整合问题。
重要性:现有方法往往仅支持几十秒的音乐生成,且通常是闭源或仅限伴奏。YuE 弥补了歌词、人声、伴奏联合生成的空白,同时开放源代码,旨在与商业模型正面竞技 。
方法技术详解
架构概览
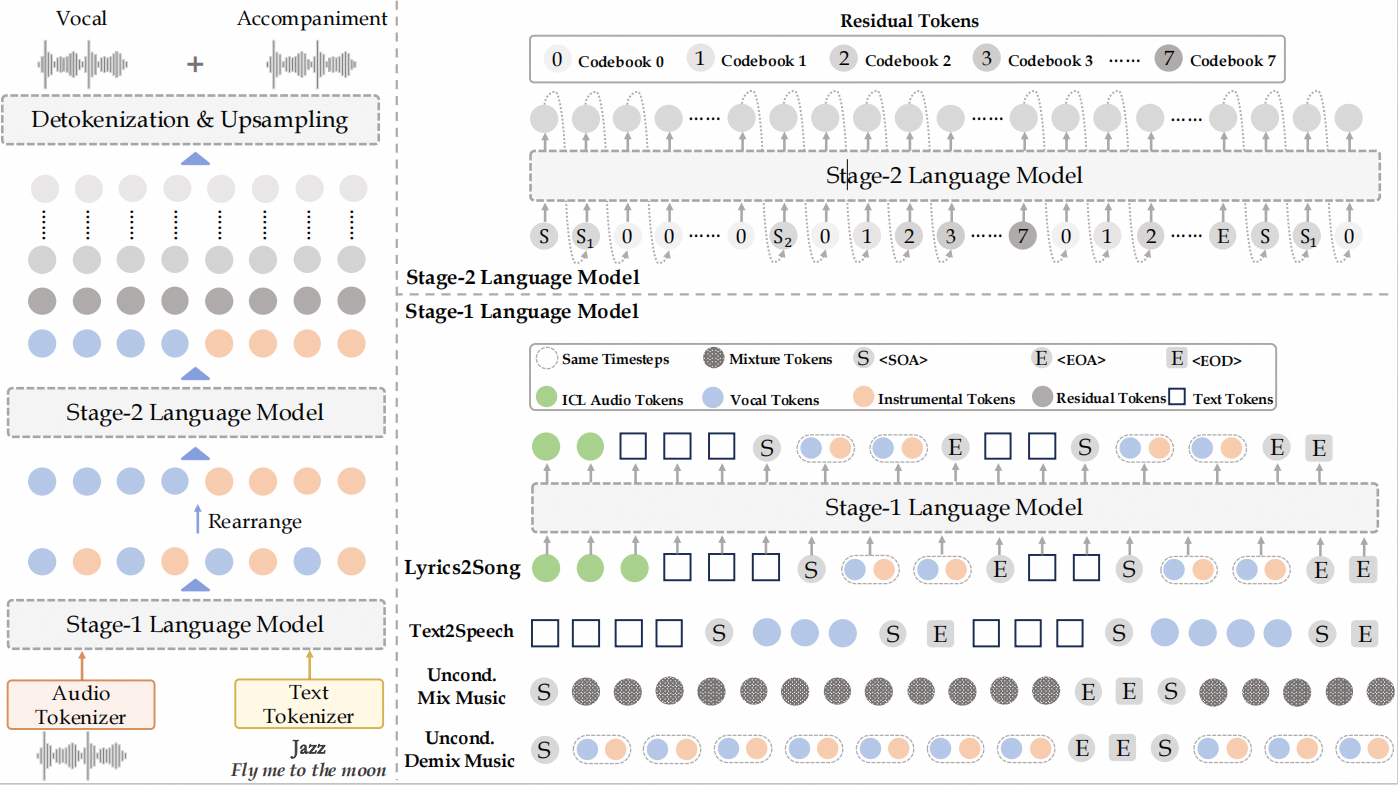
YuE 包含 两阶段生成流程:
- Stage‑1:Music Language Modeling
- Track‑decoupled Next‑Token Prediction:将“人声”与“伴奏”分别模拟,避免混合编码导致的模糊信号,提升音轨清晰度
- Structural Progressive Conditioning:按段落级别逐步添加歌词上下文,确保长篇结构与歌词节奏对齐,不至于“脱戏” 。
- In‑Context Learning (ICL) for Music:支持双轨引用输入,可实现风格变换(如“和伴奏一致地”从日系 city pop 转成英文 rap)和双向生成。
Stage‑2:Residual Modeling
在 Stage‑1 的音频semantic token基础上,进一步生成残差层(codebook 1–7),提升音质与细节表现 。最终结合所有层重构出高保真音频。
音频表示与解码
音频通过 离散代码 分级表示:
- 0层:语义粗粒度(对齐歌词与结构)
- 1–7层:细节粒度(音色、频率、音质)
Stage‑1 生成 0层,Stage‑2 补充其余层,音频最终通过解码器重构。
训练策略
- 多任务训练:包括伴奏分离、人声音色变化等任务融合,提高模型鲁棒性。
- 分阶段预训练:先训练 Stage‑1,再接 Stage‑2,提升收敛效率与泛化能力。
- 启用 In‑Context 时:Stage‑1 输出固定,不随提示动态调整残差生成,保证一致性。
实验结果与分析
主观评价(A/B测试)
采用六项主观指标评估,包括音乐性、声乐灵活性、人歌词匹配、结构安排等,并以 Suno V4 作为基线:
- 音乐结构 & 编排:YuE 在结构一致性与编排能力上表现优异,甚至超过部分闭源模型
- 伴奏与声乐音质:相比于 Suno V4 仍有差距,YuE 在细节质量方面稍落后,主要受限于分层token化方法与音频解码器
- 可控能力:在风格、情绪、乐器控制方面表现较强,说明 conditioning 机制设计有效
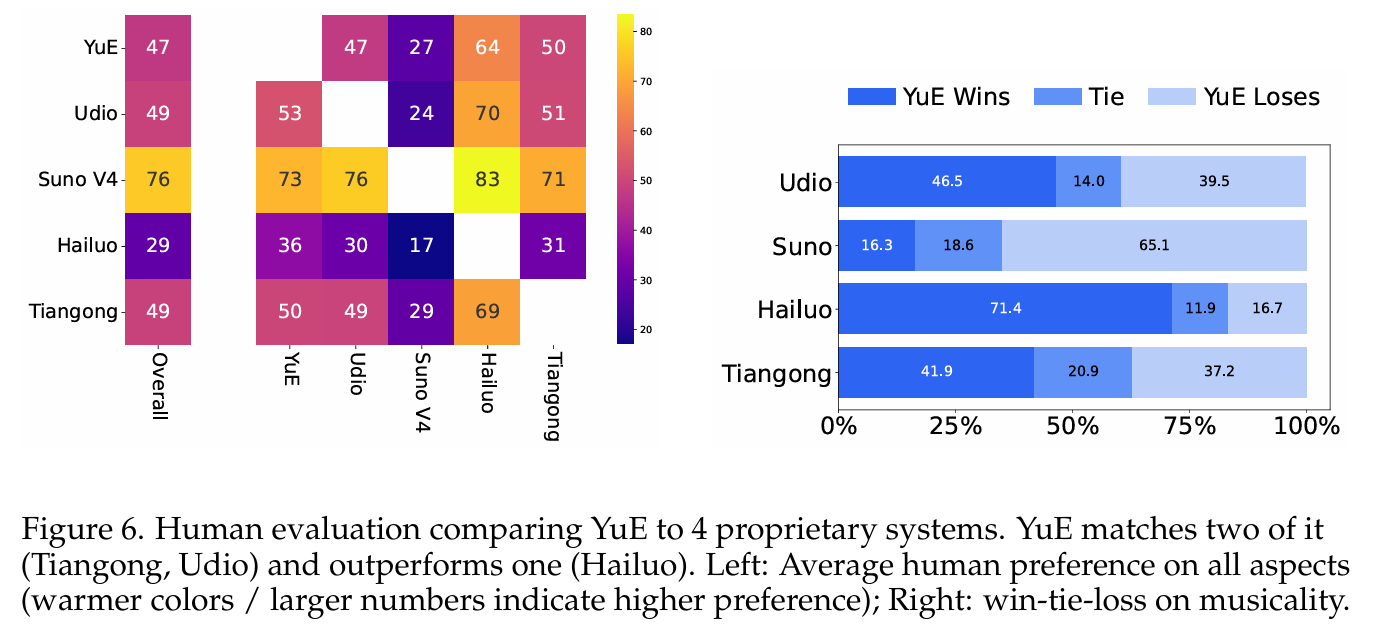
自动指标
- 声乐音域范围(Vocal Range):YuE 中位值约 27 个半音,接近 Suno V4 的表现,高于其他几乎模型(如 Hailuo、Tiangong 等 ~20 半音)
- 时长覆盖:支持超过 5 分钟生成,显著优于多数短片段模型
- 评价指标相关性分析:发现常规 CLAP 分数与主观音乐性相关性低,而 CLaMP3 分数与声乐范围表现出较好一致性,提示未来音乐评估指标需定制化
音乐理解任务
YuE 在 MARBLE benchmark(多标签音乐理解任务)上表现达到了或超过前沿模型,说明训练的表示不仅对生成有效,对理解也有泛化能力
研究贡献
- 完整开源:第一个支持完整歌词到歌曲生成的开源基础模型,架构规模达数万亿 token
- Track‑decoupled & Progressive Conditioning:创新性处理音轨分离与长度一致性问题
- In-context learning for style transfer:支持风格跨语言生成与双向建模
- 分阶段多任务训练:提升收敛效率、降低 overfitting
- 音乐理解能力:生成 + 理解能力验证
限制与未来方向
- 音频质量瓶颈:残差层音质仍略逊,未来可引入超分辨率解码器或更密编码方式。
- 评价体系不足:CLAP 等现有指标不足以衡量长歌生成质量,亟需更多音乐专属指标。
- 可控精度提升空间:节奏、歌词对齐等控制仍有提升潜能。
- 应用扩展:可进一步向 stem 分离编辑、实时自适应生成等方向探索。